So what does this algorithm look like in action? Let's try it with an example. We'll consider the grammar $G$, defined by $$ S \to ( S ) S \mid \varepsilon $$ Here, $L(G)$ is the language of well-balanced parentheses, called the Dyck language. Applying the first step, adding a new start variable, we obtain \begin{align*} S_0 &\to S \\ S &\to (S)S \mid \varepsilon \end{align*} Then eliminating the $\varepsilon$-production, we have \begin{align*} S_0 &\to S \mid \varepsilon \\ S &\to (S)S \mid () S \mid (S) \mid () \end{align*} Then, we eliminate unit productions to obtain \begin{align*} S_0 &\to (S)S \mid () S \mid (S) \mid () \mid \varepsilon \\ S &\to (S)S \mid () S \mid (S) \mid () \end{align*} Then, we introduce productions for each terminal, \begin{align*} S_0 &\to A_LSA_RS \mid A_LA_R S \mid A_LSA_R \mid A_LA_R \mid \varepsilon \\ S &\to A_LSA_RS \mid A_LA_R S \mid A_LSA_R \mid A_LA_R \\ A_L &\to ( \\ A_R &\to ) \end{align*} Then final step is to ensure every production is broken up into the form $A \to BC$.
A few things to note. As you might guess from the construction, grammars in CNF can be quite large. In fact, if you have a CFG of size $n$, an equivalent grammar in CNF can be as large as $O(n^2)$. This means that while CNF grammars have some nice properties for proofs, it doesn't seem so great for implementation. Secondly, grammars in CNF can be ambiguous. Since inherently ambiguous context-free languages exist, that must mean that any grammar in CNF that generates those languages must also be ambiguous.
So how exactly are context-free languages more powerful than regular languages? It would be helpful to have some qualiites of how they compare to regular languages. Here, we will do just that, by returning to the notion of a machine.
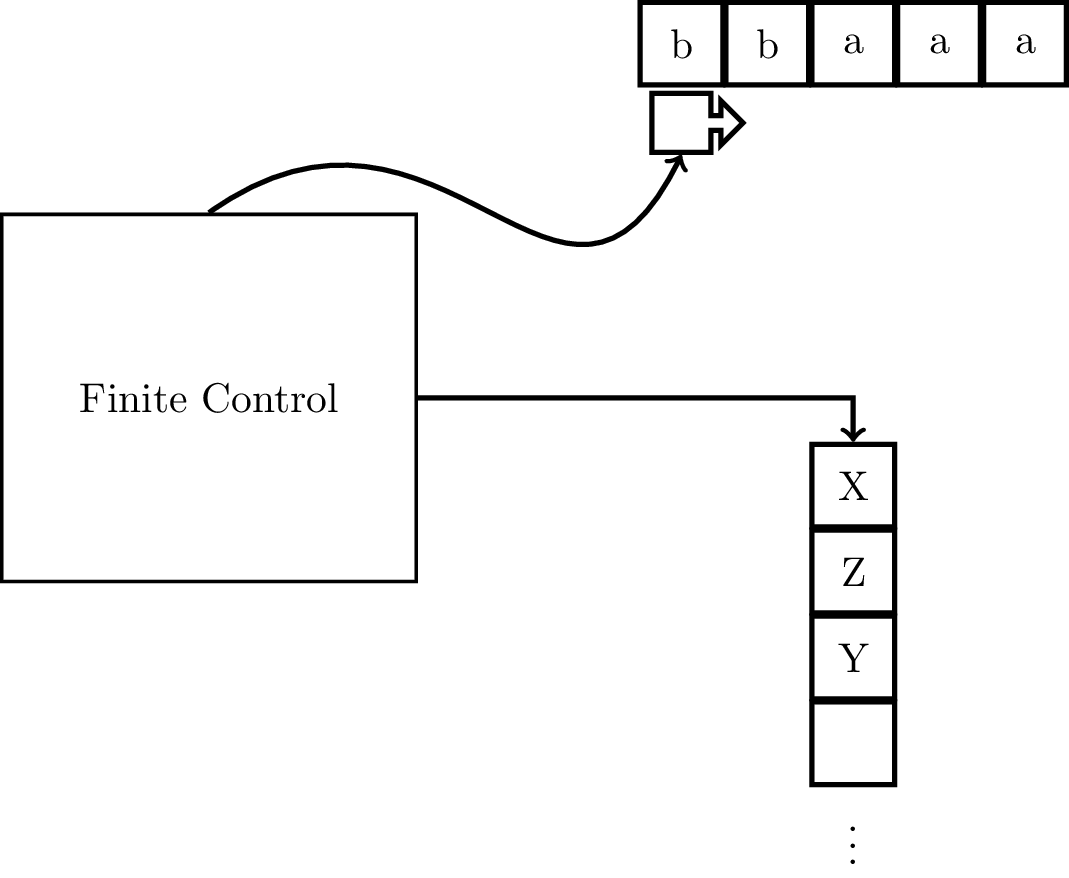
Recall that a finite automaton is limited in two important ways: the input can only be read once and it only has a finite amount of memory. We will be augmenting the NFA to take care of the second problem, by giving it access to a stack with unlimited memory.
The idea is that when you read a symbol on the input tape, you also take a symbol off of the stack. The transition depends on three pieces of information: the symbol you read on the input tape, the current state, and the symbol on the top of the stack. These determine what the next state is and what gets put onto the stack. So although the machine now has access to unlimited memory, there are restrictions on how it is able to access this memory.
Much of the fundamental properties of pushdown automata can be attributed to Schützenberger (1963), who was one of Chomsky's early collaborators in formal languages, and Chomsky himself, though many of these discoveries were independently published by others (Oettinger 1961, Evey 1963). Around this time, research into formal languages and automata theory was picking up and there were all sorts of investigations into modifications and restrictions on grammars and automata. The pushdown automaton is one result of these kinds of questions being pursued.
Formally, pushdown automaton (PDA) is a 7-tuple $M = (Q,\Sigma,\Gamma,\delta,q_0,Z_0,F)$, where
There are a few features of the transition function that should be mentioned. First, the transition function is nondeterministic. Secondly, on a transition, the machine takes the top symbol off of the stack but can put many symbols onto the stack, as long as it is a finite amount.
As with finite automata, we can enumerate the parts of the PDA.
We write transitions in the following way: $$\delta(q,a,X) = \{(q_1,\alpha_1), \dots, (q_n,\alpha_n)\}$$ where $q,q_1,\dots,q_n \in Q$, $a \in \Sigma$, $X \in \Gamma$, and $\alpha_1,\dots,\alpha_n \in \Gamma^*$. Since $\alpha_i$ is a string, it's important to note the order in which we push symbols onto the stack. If $\alpha_i = X_1 X_2 \cdots X_k$ where $X_j \in \Gamma$, $X_k$ gets pushed onto the stack first and after all of $\alpha_i$ is pushed onto the stack, $X_1$ is on the top of the stack. In other words, the top of the stack should look like we just took $\alpha_i$ and turned it 90 degrees so that $X_k$ is at the bottom and $X_1$ is at the top.
As an example, we write one of the transitions from the above machine as $$\delta(q_0,a,Z_0) = \{(q_0,XZ_0)\}.$$
Of course, as with NFAs, listing the entire transition function explicitly can be quite cumbersome. Also, note that just like for NFAs, we can draw a state diagram for a PDA. The idea is mostly the same, but the difference is how to denote the changes to the stack. For a transition $(q',\alpha) \in \delta(q,a,X)$ we label the transition from $q$ to $q'$ by $a,X/\alpha$.
As with the NFA, if a transition is undefined, we assume that it goes to the empty set (since the image of the transition function is subsets of $Q \times \Gamma^*$). In practice, we treat this as the machine crashing. For a PDA, in addition to not having transitions defined on a state and symbol, we also take into consideration the symbol that we pop from the stack. One particular case of this is when we try to pop an element off of an empty stack (this is undefined, so we go to the empty set).
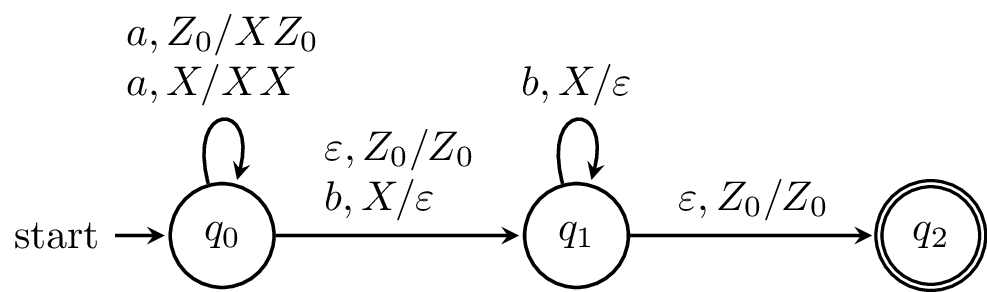
Here, we have a PDA that we claim recognizes the language $\{a^k b^k \mid k \geq 0\}$. In order to verify our claim, we'll need to formalize notions of what it means for a PDA to "recognize" or "accept" a language. And in order to do that, we'll need to formalize the notion of what it means for a word to move through a PDA.
Describing the computation of an NFA was simple, since it's really just a path and all we needed to know to describe what the state of the NFA was is how far in the input string the NFA is and what state(s) the NFA is on. With the PDA, there is one more piece of information that we need to take into account: the stack.
The description of the state of a PDA is called the configuration of a PDA and it is a 3-tuple $(q,w,\gamma)$, where
Now, we want to describe transitions from one configuration to another in the PDA. Suppose we have two configurations $(q,w,\gamma)$ and $(p,z,\zeta)$. Then we write $(q,w,\gamma) \vdash (p,z,\zeta)$ if $\gamma = X\beta$ and $w = az$ such that
We can, as usual, extend this definition for more than one step. Let $I,J \in Q \times \Sigma^* \times \Gamma^*$ be configurations of a PDA $P$. Then $I \vdash^* I$ for all $I \in Q \times \Sigma^* \times \Gamma^*$. Then if for some $K \in Q \times \Sigma^* \times \Gamma^*$, we have $I \vdash K$ and $K \vdash^* J$, then $I \vdash ^* J$. Then a computation in a PDA $P$ is a sequence of configurations $K_1, K_2, \dots, K_n$, where $K_1 \vdash K_2 \vdash \cdots \vdash K_n$.
We say a PDA $P$ accepts a word $x$ if $(q_0,x,Z_0) \vdash^* (q,\varepsilon, \gamma)$ for some $q \in F$ and $\gamma \in \Gamma^*$. The language of a PDA $P$ is $$ L(P) = \{w \in \Sigma^* \mid \text{ $P$ accepts $w$ }\}.$$
Let's look at the PDA from earlier again.
We can describe how this PDA works informally. The PDA begins by reading $a$'s and for each $a$ that's read, an $X$ is put on the stack. Then, once a $b$ is read, and the computation moves onto the next state. For every $b$ that is read, an $X$ is taken off the stack. The machine can only reach the final state if the stack is empty and there is no more input to be read.
We can trace a computation on the word $aabb$ to see how this works. We begin in the initial configuration $(q_0,aabb,Z_0)$. Then our computation looks like this: $$(q_0,aabb,Z_0) \vdash (q_0,abb,XZ_0) \vdash (q_0,bb,XXZ_0) \vdash (q_1,b,XZ_0) \vdash (q_1,\varepsilon,Z_0) \vdash (q_2,\varepsilon,Z_0).$$
Note that the definition of the transition function prevents any other word from reaching the final state. For instance, $a$'s can't be read after moving to $q_1$, otherwise the machine will crash. Similarly, if a $b$ is read and there are is no corresponding stack symbol, the machine crashes, and a $\varepsilon$-transition can only be taken to reach the final state if the stack is empty.
Here, we want to define a PDA that recognizes the language of marked palindromes, $$\{w \# w^R \mid w \in \{a,b\}^* \}.$$
The idea is quite simple: we can read $w$ and keep track of it on the stack until we read the marker $\#$. Once we do that, we just need to make sure that the rest of the word matches the reverse of $w$. Luckily, this is exactly how stacks work.
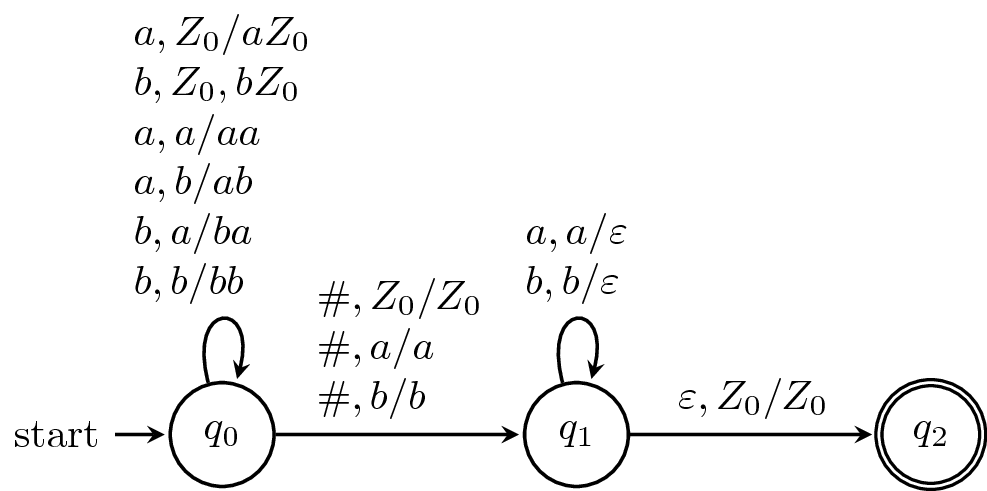
Like the example above, processing the latter part of the word depends on what is on the stack. If the lengths of the stack and the second half of the word don't match up, then the machine crashes. Similarly, if a symbol is read that doesn't match what's on the stack, then the machine crashes. Or, if more than one marker symbol is read, the machine crashes.
Again, we can trace the computation of a word $ab\#ba$, \begin{align*} (q_0,ab\#ba,Z_0) &\vdash (q_0,b\#ba,aZ_0) \vdash (q_0,\#ba,baZ_0) \\ &\vdash (q_1,ba,baZ_0) \vdash (q_1,a,aZ_0) \vdash (q_1,\varepsilon,Z_0) \\ &\vdash (q_2,\varepsilon,Z_0). \end{align*}
As it turns out, acceptance by final state is not the only model of acceptance for pushdown automata. Let $P$ be a PDA. Then we can define the language of the machine in the following way $$ N(P) = \{w \in \Sigma^* \mid (q_0, w, Z_0) \vdash^* (q,\varepsilon,\varepsilon), q \in Q \}.$$
In other words, we accept a word if the stack is empty after reading it. Obviously, under this model, final states are superfluous, so PDAs using this acceptance model can be described by a 6-tuple instead.
As it turns out, the two models of acceptance are equivalent. That is given a PDA defined under one model of acceptance, it's possible to construct a PDA under the other model of acceptance which accepts the same language. We'll sketch out the constructions.
Theorem 6.9. Let $A$ be a PDA that accepts by final state. Then there exists a PDA $A'$ which accepts $L(A)$ by empty stack.
Proof (sketch). Our new machine $A'$ needs to satisfy two properties. First of all, whenever $A$ reaches a final state on a word $w$ (that is, $A$ accepts $w$), we want to empty the stack. Secondly, we don't want the stack to ever be empty before the entire input is read.
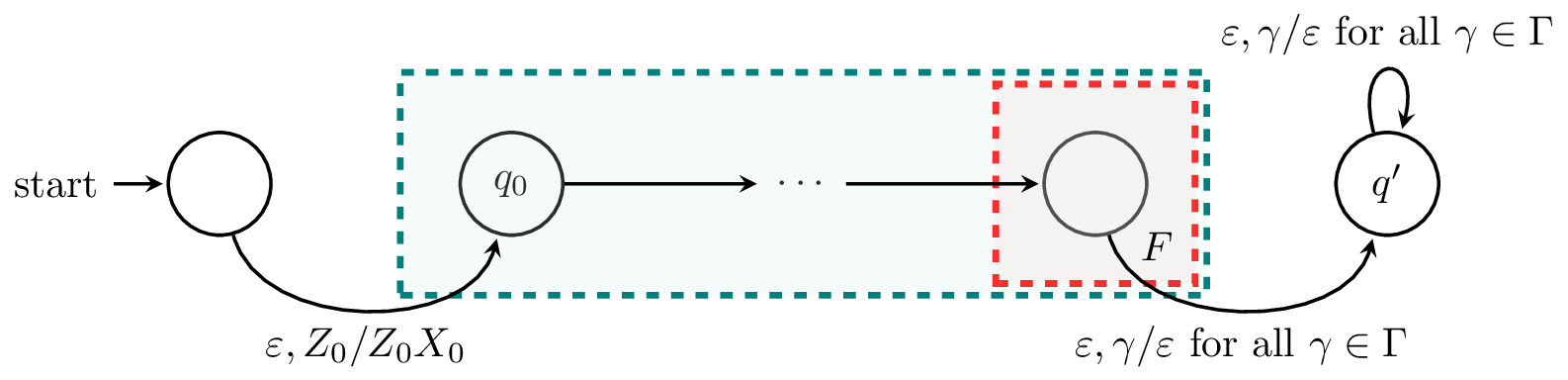
For the first property, we create a new state $q'$ and add transitions $\delta(q,\varepsilon,\gamma) = (q',\varepsilon)$ from every final state $q$ of $A$ to $q'$. Then $q'$ only contains transitions of the form $\delta(q',\varepsilon,\gamma) = (q',\varepsilon)$ for all $\gamma \in \Gamma$. Also note that any computation that enters $q'$ with part of the input still unread will crash.
For the second property, to prevent the stack from being empty during the course of the computation, we add a new symbol $X_0$ to the bottom of the stack. We do this by adding a new initial state with a transition to the initial state of $A$ whose only function is to place $X_0$ below $Z_0$ on the stack. Since $X_0$ is not in the stack alphabet of $A$, there is no transition that can remove it and the only way the stack can be empty is after visitng $q'$. $$\tag*{$\Box$}$$
Theorem 6.11. Let $B$ be a PDA that accepts by empty stack. Then there exists a PDA $B'$ which accepts $L(B)$ by final state.
Proof (sketch). To construct our new PDA $B'$, we need to ensure that the machine enters a final state whenever the machine would have emptied its stack and accepted. To do this, we add a new state $q'$ to $B'$ which is its sole accepting state.
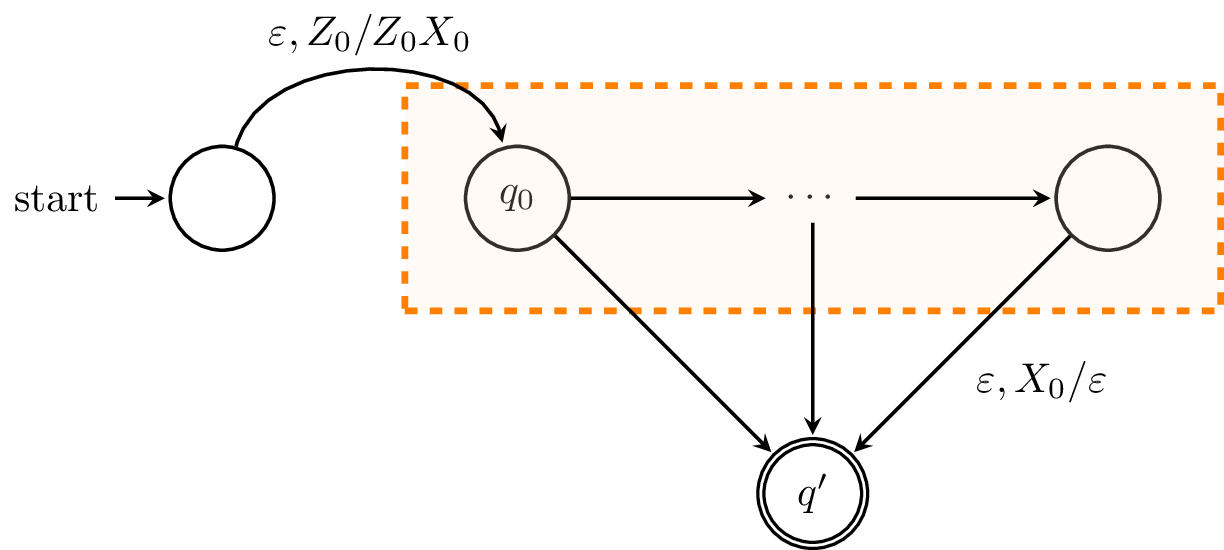
However, we also need a means of detecting that the stack is empty. To do this, we again add a new symbol $X_0$ to the stack alphabet and add a new initial state that adds $X_0$ to the stack below $Z_0$.
With this, we can add transitions $\delta(q,\varepsilon,X_0) = (q',\varepsilon)$ from every state $q$ of $B$. Since there are no transitions involving the stack symbol $X_0$ in $B$, it is clear that the machine only takes the transition to $q'$ whenever $B$ would have emptied its stack. $$\tag*{$\Box$}$$