Let $\Sigma = \{0,1\}$. We say that a word $w \in \Sigma^*$ is balanced if $|w|_0 = |w|_1$. Let $L = \{w \in \Sigma^* \mid |w|_0 = |w|_1 \}$ be the language of binary balanced words. We claim that the grammar $G$, defined by $$S \to 0S1S \mid 1S0S \mid \varepsilon$$ generates $L$.
Proposition. $L(G) = L$.
Proof. First, we will show that $L(G) \in L$ by induction on the number of steps $k$ in a derivation of a word $w \in L(G)$.
For our base case, we have $k = 1$ and we have $w = \varepsilon \in L$.
Now consider $k \geq 2$ and assume that every word $w' \in L(G)$ with fewer than $k$ steps in its derivation is in $L$. Since $k \geq 2$, we will consider the first step in the derivation of $w$ to be $S \to 0S1S$. Let $u,v \in L(G)$ be words that can be derived in fewer than $k$ steps and let $w = 0u1v$. Then we have $|w|_0 = |u|_0 + |v|_0 + 1$ and $|w|_1 = |u|_1 + |v|_1 + 1$. But $u,v \in L$ by our induction hypothesis, so we have $|u|_0 = |u|_1$ and $|v|_0 = |v|_1$, giving us $|w|_0 = |w|_1$. A similar argument can be made when taking $S \to 1S0S$ as the first step of the derivation. Therefore, we have $w \in L$ and $L(G) \subseteq L$ as desired.
Next, we will show that $L \subseteq L(G)$. Let $w \in L$. We will show this by induction on $n = |w|$.
For the base case, we have $n = 0$ and $w = \varepsilon \in L(G)$ by $S \Rightarrow \varepsilon$.
Now let $n \geq 1$ and assume that for all strings $w' \in L$ with $|w| < n$, we have $w' \in L(G)$. Let $w = a_1 \cdots a_n$, where $a_i \in \Sigma$ for $1 \leq i \leq n$. Since $w \in L$, we have $$|a_1 \cdots a_n|_0 = |a_1 \cdots a_n|_1.$$
Let $m$ be the minimum value such that $$|a_1 \cdots a_m|_0 = |a_1 \cdots a_m|_1.$$
In other words, $a_1 \cdots a_m$ is the shortest prefix of $w$ that is still balanced. We will show that $a_1 \neq a_m$. Assume to the contrary that $a_1 = a_m$. We define $$d_k = |a_1 \cdots a_k|_1 - |a_1 \cdots a_k|_0$$ for all $1 \leq k \leq m$. From above, we must have $d_m = 0$. Then, we have \begin{align*} |a_1 \cdots a_m|_1 &= |a_1 \cdots a_{m-1}|_1 + |a_m|_1 = |a_1 \cdots a_{m-1}|_1 + |a_1|_1 \\ |a_1 \cdots a_m|_0 &= |a_1 \cdots a_{m-1}|_0 + |a_m|_0 = |a_1 \cdots a_{m-1}|_0 + |a_1|_0 \end{align*} and by subtracting these two equations, we have $d_m = d_{m-1} + d_1$. Observe that $d_m = 0$ and $d_1 \neq 0$, and therefore we have $d_{m-1} \neq 0$ and that $d_{m-1}$ and $d_1$ must have opposite sign. But note also that consecutive values of $d_k$ differ by only 1. Since $d_1$ and $d_{m-1}$ have opposite sign, this must mean there exists $k$ with $2 \leq k \leq m-2$ such that $d_k = 0$, contradicting our assumed minimality of $m$. Thus, $a_1 \neq a_m$.
This will allow us to construct our derivation. Since $$|a_1 \cdots a_m|_0 = |a_1 \cdots a_m|_1$$ and $a_1 \neq a_m$, we have $u = a_2 \cdots a_{m-1}$ and $v = a_{m+1} \cdots a_n$ such that $|u|_0 = |u|_1$ and $|v|_0 = |v|_1$. Since $|u|,|v| < n$, we have $u,v \in L(G)$ and therefore $S \Rightarrow^* u$ and $S \Rightarrow^* v$. Then we have the following possibile derivations for $w$, \begin{align*} S &\Rightarrow 0S1S \Rightarrow^* 0u1v = w, \\ S &\Rightarrow 1S0S \Rightarrow^* 1u0v = w. \\ \end{align*} Thus, $w \in L(G)$ and $L \subseteq L(G)$ as required. $$\tag*{$\Box$}$$
As we've seen from our definition of context-free grammars, we never really need to specify a particular order for how we might apply production rules or the order in which we should replace variables. However, it's a good idea to have some sort of systematic approach to how we apply productions and the kinds of derivations that result from such an approach.
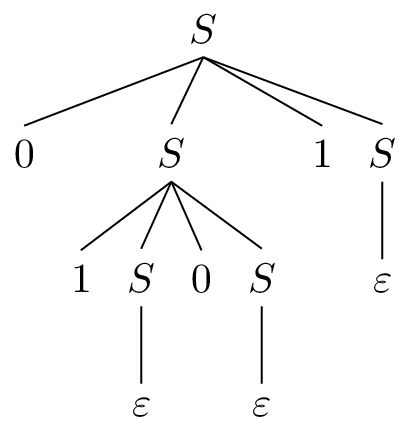
We say that a leftmost derivation is a derivation in which the leftmost variable is expanded at each step. Here's an example of a leftmost derivation of a string generated by the grammar for binary balanced words: $$S \Rightarrow 0S1S \Rightarrow 01S0S1S \Rightarrow 010S1S \Rightarrow 0101S \Rightarrow 0101.$$
We can define the rightmost derivation similarly. Since, as mentioned above, it doesn't matter which order variables are acted upon by production rules, we can conclude that every word generated by a CFG has a leftmost derivation. As it turns out, leftmost derivations have an interesting correspondence with parse trees. Parse trees are a way for us to visualize how a word is generated from a grammar.
Given a grammar $G$, a tree is a parse tree for $G$ if it satisfies the following conditions:
Any subtree of a parse tree is also a parse tree, except for a leaf.
The yield of a parse tree is the concatenation of the symbols at the leaves of the tree from left to right. A full parse tree is one whose root is the start variable and the leaves are all labeled with terminals. Such a tree yields a word generated by the grammar. The following is the parse tree for the derivation we saw earlier.
As alluded to before, there is a bijection between the set of parse trees of a word and the set of its leftmost derivations. It isn't difficult to see that performing a depth-first traversal of a parse tree allows us to recover a leftmost derivation. There are a whole bunch of results that we could prove about this, but we're only interested in parse trees in how they can be used for other purposes.
From what we just discussed, you might have noticed that we talked about sets of leftmost derivations of a single word. While it's not a surprise that there may be multiple ways to arrive at an arbitrary derivation of a word, it is a bit more interesting that even in restricting ourselves to leftmost derivations, we can come up with multiple derivations. For instance, here is a different derivation generating the same word from earlier: $$S \Rightarrow 0S1S \Rightarrow 01S \Rightarrow 010S1S \Rightarrow 0101S \Rightarrow 0101.$$
And here is its associated parse tree.
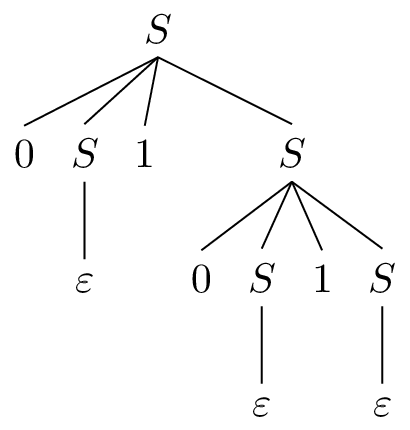
A grammar $G$ is ambiguous if there is a word $w \in L(G)$ with more than one leftmost derivation (or, equivalently, parse tree).
Obviously, we would like for our grammars to be unambiguous as much as is possible. For instance, we can do a bit of work and come up with an unambiguous grammar for balanced words as follows: \begin{align*} S &\to 0X1S \mid 1Y0S \mid \varepsilon \\ X &\to 0X1X \mid \varepsilon \\ Y &\to 1Y0Y \mid \varepsilon \end{align*}
Here, we've added variables to sort of corral the derivation into obeying some property. Here, we define new variables which obey the property that words they generate are totally balanced. A totally balanced word $w$ has the property that, in addition to satisfying $|w|_0 = |w|_1$, every prefix $w'$ of $w$ satisfies $|w'|_0 \geq |w'|_1$. This is the case for words generated by $X$, while the role of 0 and 1 are reversed for those words generated by $Y$. In this way, there is only one option for a particular string to be generated.
But what we would really like is to be able to take a grammar $G$ that is ambiguous and compute an equivalent grammar that is unambiguous. Unfortunately, we run into our first allusion to the idea of uncomputability here: there does not exist any algorithm which allows us to determine whether or not a grammar is ambiguous.
Furthermore, so far as we've discussed it, ambiguity is a property of a grammar, not a language. This raises the natural question of whether every context-free language has an unambiguous grammar. Unfortunately, the answer is no.
We say that a language is inherently ambiguous if there is no unambiguous grammar that generates it. An example of an inherently ambiguous language is $$\{a^k b^k c^m \mid k,m \geq 0\} \cup \{a^k b^m c^m \mid k,m \geq 0 \}.$$ We won't be proving this, but to see how this might be the case, one can consider parse trees for the string $a^n b^n c^n$.
One of the problems of having so much flexibility in the production rules and how to apply them is that it makes it difficult to reason about. Much of the time, when we run into situations like these, we want to find some sort of standard form which has some structure that we can rely on. For CFGs, this idea is captured in the Chomsky normal form. Unsurprisingly, this normal form and many of its properties are due to Chomsky (1959). That this one is named after Chomsky also implies that there are other normal forms (Greibach, Kuroda).
A context-free grammar $G$ is in Chomsky normal form if every production of $G$ has one of the following forms:
There are a few things to note about grammars in CNF. The first is the very useful property that every parse tree for a string $w \in L(G)$ will have exactly $2|w| - 1$ nodes which are variables and exactly $|w|$ leaf nodes. In other words, every derivation of a non-empty string $w$ via a grammar in CNF has exactly $2|w| - 1$ substitutions.
Theorem. Let $G$ be a context-free grammar in Chomsky normal form. Then for any non-empty word $w \in L(G)$, a derivation of $w$ in $G$ has $2|w| - 1$ steps.
Proof. We will show something more general: that for any variable $A$ in $G$, a derivation $A \Rightarrow^* w$ has $2|w| - 1$ steps. We will show this by induction on $|w|$. For the base case, we have $|w| = 1$. Then the only step in the derivation is $A \to w$. Otherwise, a production rule of the form $A \to BC$ leads to a word of length at least two, since there are no rules of the form $B \to \varepsilon$. Thus, we have a derivation of length 1 and $1 = 2 \cdot 1 - 1$ so the base case holds.
Now we consider $|w| > 1$. Our induction hypothesis is that for all words $w'$ with $A \Rightarrow^* w'$ and $|w'| < |w|$, the derivation of $w'$ has length $2|w'| - 1$. Since $|w| > 1$, the first step of the derivation must be on a rule $A \to BC$. This means we can write $w = w_1 w_2$ and we have $B \Rightarrow^* w_1$ and $C \Rightarrow^* w_2$ and $w_1, w_2$ are both non-empty. Since both $w_1$ and $w_2$ are shorter than $w$, by the induction hypothesis, they have derivations of length $2|w_1| - 1$ and $2|w_2| - 1$. Then a derivation of $w$ has length $$2|w_1| - 1 + 2|w_2| - 1 + 1 = 2(|w_1|+|w_2|) - 1 = 2|w| - 1.$$ $$\tag*{$\Box$}$$
The second fact is that every context-free language has a grammar in CNF.
Theorem 7.16. Let $L \subseteq \Sigma^*$ be a context-free language. Then there exists a CFG $G$ in Chomsky normal form such that $L(G) = L$.
Proof. We will begin with an arbitrary CFG $H$ and perform the following algorithm to construct an equivalent CFG $G$ in CNF.
This completes the construction. $$\tag*{$\Box$}$$