We'll take care of the rest of the proof of Theorem 3.7 now.
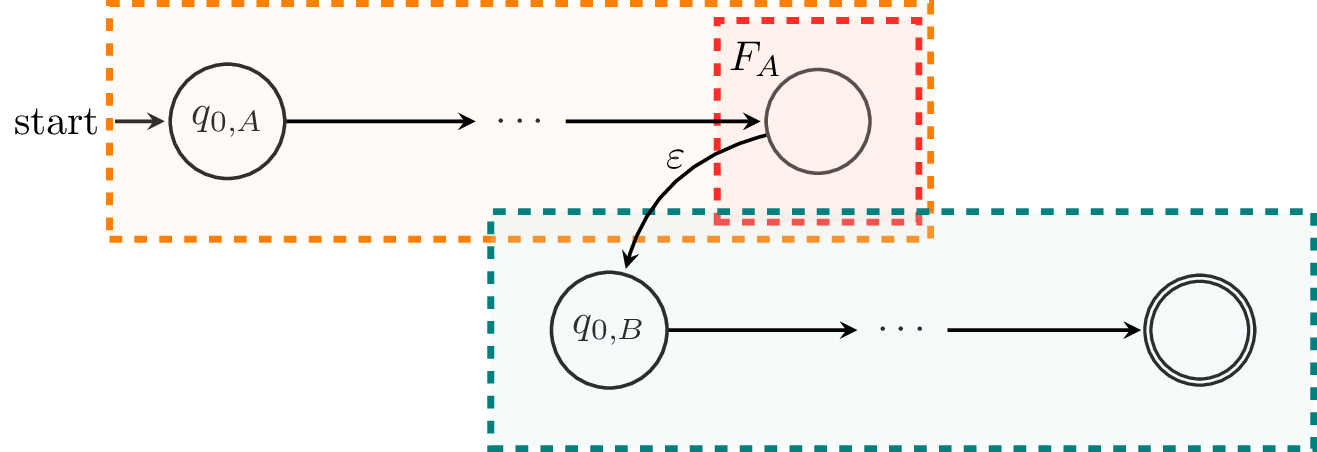
Next, we'll consider $L_A L_B$. An NFA for this would look something like this:
Formally, let $C = (Q_A \cup Q_B, \Sigma, \delta_C, q_{0,A}, F_B)$, where the transition function $$\delta_C : (Q_A \cup Q_B) \times (\Sigma \cup \{\varepsilon\}) \to 2^{Q_A \cup Q_B}$$ is defined by
We can show that $L(C) = L(A)L(B)$ by a similar argument to the case of union. Essentially, this involves arguing that the path that a word $w$ must take in order to reach a final state of $C$ must go through a final state of $A$ and hence the initial state of $B$. From this, one can conclude that $w = uv$ with $u \in L(A)$ and $v \in L(B)$.
Finally, we consider $L_A^*$. We can construct an NFA that looks like this:
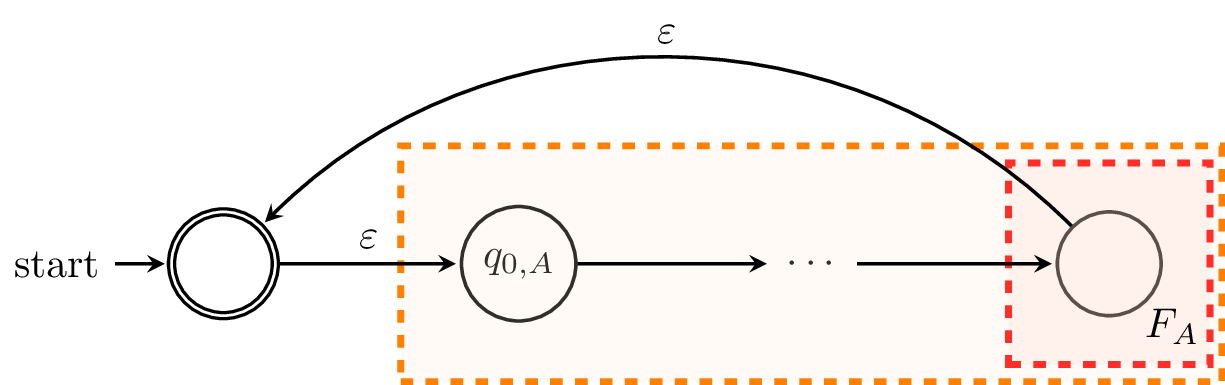
Here, we define $C$ by $C = (Q_A \cup \{q_{0,C}\}, \Sigma, \delta_C, q_{0,C}, \{q_{0,C}\})$, where the transition function $\delta_C : Q_A \times (\Sigma \cup \{\varepsilon\}) \to 2^{Q_A \cup \{q_{0,C}\}}$ is defined by
Here, we make some significant modifications to the machine. First, we need to create a new initial state and make it an initial state, in case $\varepsilon \not \in L_A$. Secondly, for each state in $F_A$, instead of adding it to the set of final states in $C$, we add $\varepsilon$-transitions to the sole final state of $C$, $q_{0,C}$. While this is mostly cosmetic, it makes the construction clearer. Each word that is accepted by $C$ must begin at $q_{0,C}$ and must end at $q_{0,C}$, making zero or more traversals through $A$, and each traversal of $A$ must be a word accepted by $A$. Hence, each word accepted by $C$ is a concatenation of multiple words accepted by $A$ and thus, a word that belongs to $L_A^*$.
Thus, we have shown that we can construct $\varepsilon$-NFAs for $L_A \cup L_B$, $L_A L_B$, and $L_A^*$ and therefore, we can construct a DFA that accepts any given regular language. $$\tag*{$\Box$}$$
Up to now, we've only considered finite automata as a way to describe a language. However, using finite automata as a description has its limitations, particularly for humans. While all of the finite automata we've seen so far are reasonably understandable, they are relatively small. Finite automata as used in practical applications can contain hundreds or thousands or more states. Luckily, our definition of regular languages will give us a more succinct and friendlier way to describe a regular language, via regular expressions.
We say $R$ is a regular expression over an alphabet $\Sigma$, and $L(R)$ is the language of the regular expression $R$, if $R$ satisfies one of the following conditions:
and for regular expressions $R_1$ and $R_2$,
Furthermore, we establish an order of operations, like for typical arithmetic expressions:
and as usual, we can explicitly define an order for a particular expression by using parentheses.
We can see that this definition mirrors that of the definition for regular languages and we can pretty easily conclude that the regular expressions describe exactly the class of regular languages. It's also important to note that we should separate the notion of a regular expression and the language of the regular expression. Specifically, a regular expression $R$ is just a string, while $L(R)$ is the set of words described by the regular expression $R$.
Here are some examples of some regular expressions and the languages they describe.
We've already shown that for every regular language, there is a DFA that accepts it. Now, we complete the characterization by showing the other direction: that the language of any DFA is regular. We will do this by showing that we can take any DFA and construct a regular expression that recognizes the same language.
Theorem 3.4. Let $A$ be a DFA. Then there exists a regular expression $R$ such that $L(R) = L(A)$.
Proof. Let $A = (Q,\Sigma,\delta,q_0,F)$ and without loss of generality, let $Q = \{1,2,\dots,n\}$. For every pair of states $p,q \in Q$ and integer $k \leq n$, we define the language $L_{p,q}^k$ to be the language of words for which there is a path from $p$ to $q$ in $A$ consisting only of states $\leq k$. In other words, if $w$ is in $L_{p,q}^k$, then for every factorization $w = uv$, we have $\delta(p,u) = r$ such that $r \leq k$ and $\delta(r,v) = q$.
We will show that every language $L_{p,q}^k$ can be defined by a regular expression $R_{p.q}^k$. We will show this by induction on $k$. The idea is that we will begin by building regular expressions for paths between states $p$ and $q$ with restrictions on the states that such paths may pass through and inductively build larger expressions from these paths until we acquire an expression that describes all paths through the DFA with no restrictions.
We begin with $k=0$. Since states are numbered $1$ through $n$, we have two cases:
For our inductive step, we consider the language $L_{p,q}^k$ and assume that there exist regular expressions $R_{p,q}^{k-1}$ for languages $L_{p,q}^{k-1}$. Then we have $$L_{p,q}^k = L_{p,q}^{k-1} \cup L_{p,k}^{k-1} (L_{k,k}^{k-1})^* L_{k,q}^{k-1}.$$ This language expresses one of two possibilities for words traveling on paths between $p$ and $q$. First, if $w \in L_{p,q}^{k-1}$, then $w$ does not travel through any state $k$ or greater between $p$ and $q$.
The other term of the union consists of words $w$ which travel through $k$. The language $L_{p,k}^{k-1}$ is the set of words travelling from $p$ to $k$ restricted to states $\leq k-1$ and the language $L_{k,q}^{k-1}$ is the set of words travelling from $k$ to $q$ restricted to states $\leq k-1$. In between these two languages is $L_{k,k}^{k-1}$, which is the set of words travelling from $k$ back to $k$ without going to any state greater than $k-1$.
This gives us the regular expression $$R_{p,q}^k = R_{p,q}^{k-1} + R_{p,k}^{k-1} (R_{k,k}^{k-1})^* R_{k,q}^{k-1}.$$ From this, we can conclude that there exists a regular expression $$ R = \sum_{q \in F} R_{q_0,q}^n.$$ Here, $R$ is the regular expression for the language of all words for which there exist a path from $q_0$ to a final state $q \in F$. In other words, $R$ is a regular expression such that $L(R) = L(A)$. $$\tag*{$\Box$}$$
Putting Theorems 3.4 and 3.7 together, we get Kleene's theorem. The definition of what we now call regular expressions is due to Kleene in 1951 and is basically the reason why we call the star operator the Kleene star. The same 1951 RAND memo (which was later published in a journal in 1956) contained Kleene's theorem.
Another thing you may notice is that the regular expressions that we've defined are much more restricted than the ones we commonly see in the course of software development. Indeed, a lot of regular expression tools have various convenient features. Some of these features are only conveniences which don't give regular expressions any additional power, some of which we'll see shortly.
However, some other features, like backtracking, are powerful enough that they can recognize languages which are not regular. A formal study of the power of such "practical" regular expressions was done by Câmpeanu, Salomaa, and Yu in 2003. But what do languages that aren't regular look like? We will have a look at such languages later.