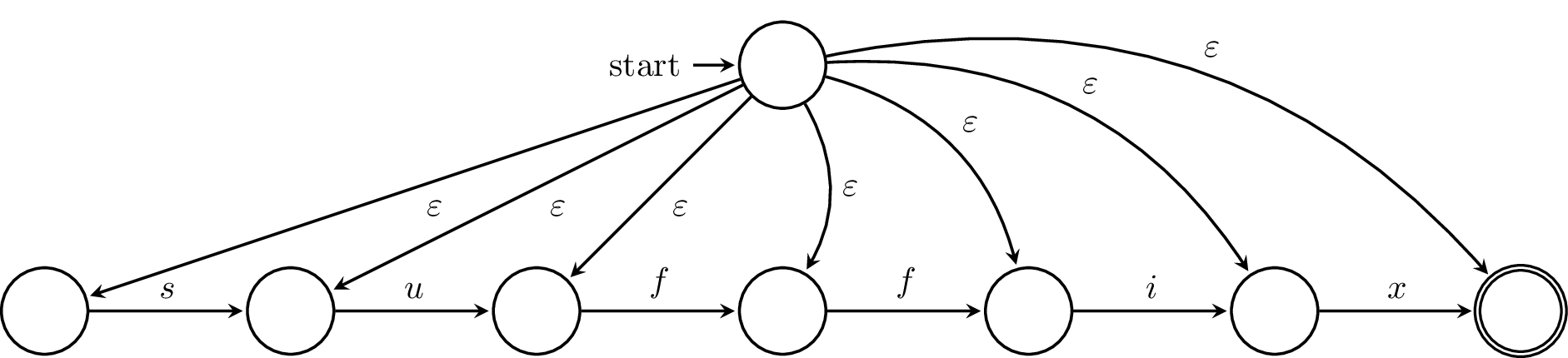
Now, we'll consider another possible enhancement to the finite automaton: allowing transitions to other states via $\varepsilon$. This additional trick will be very convenient later on, but again, we have to ask the question: does this make finite automata more powerful? We will answer this shortly. First, an example.
This here is an $\varepsilon$-NFA that recognizes the language of all suffixes of the word $suffix$.
Formally, an $\varepsilon$-NFA is a 5-tuple $A = (Q,\Sigma,\delta,q_0,F)$ as in the definition of the NFA, except that the transition function is now a function from a state and either a symbol or $\varepsilon$ to a set of states, $\delta : Q \times (\Sigma \cup \{\varepsilon\}) \to 2^Q$.
So the question now is, what is the result of a transition function that allows $\varepsilon$s? What we would like is a way to say, for some set of states $P \subseteq Q$, "all the states that are reachable on one or more $\varepsilon$-transitions from a state $p \in P$". We'll define the $\varepsilon$-closure of $P$ to be exactly this.
Formally, the $\varepsilon$-closure of a state $q \in Q$ is denoted by $\overline \varepsilon(q)$ and is defined recursively:
Then the $\varepsilon$-closure of a set $P \subseteq Q$, denoted $\overline \varepsilon(P)$ is defined by $$\overline \varepsilon(P) = \bigcup_{p \in P} \overline \varepsilon(p).$$
Now, we can define our new extended transition function $\hat \delta : Q \times \Sigma^8 \to 2^Q$. First, if $|w| = 0$, then $w = \varepsilon$ and $\hat \delta(q,\varepsilon) = \overline \varepsilon(q)$. Then for $|w| > 0$, we let $w = xa$ with $a \in \Sigma$ and we have $$\hat \delta(q,w) = \hat \delta(q,xa) = \overline \varepsilon \left( \bigcup_{p \in \hat \delta(q,x)} \delta(p,a) \right).$$
In other words, our new extended transition function for the $\varepsilon$-NFA is just the one for the ordinary NFA, except that we need to ensure that we account for the $\varepsilon$-closure of the result.
You might observe that, as we still only need to consider at most $2^{|Q|}$ possible sets, that allowing $\varepsilon$-transitions do not give NFAs any additional power, and you would be absolutely correct. At this point, you can play the same game as with the NFA and perform the subset construction to acquire an equivalent DFA, as long as you make sure to account for the $\varepsilon$-closure.
If we have an $\varepsilon$-NFA $N = (Q,\Sigma,\delta,q_0,F)$, we can define a DFA $\mathcal D_\varepsilon(N) = (Q',\Sigma,\delta',q_0',F')$ in the same way as the subset construction above, but with two differences:
In other words, the subset construction for $\varepsilon$-NFAs is exactly the same as for NFAs, except that all the states of $\mathcal D_\varepsilon(N)$ are $\varepsilon$-closed subsets of $Q$. We can then use this to show the following.
Theorem 2.22. A language $L$ is accepted by an $\varepsilon$-NFA if and only if $L$ is accepted by a DFA.
The proof is almost exactly the same as for ordinary NFAs so we won't be going through it here. This result establishes that DFAs, NFAs, and $\varepsilon$-NFAs are all equivalent models and that they all recognize the same class of languages, the regular languages. In other words, nondeterminism and $\varepsilon$-transitions do not give our basic finite automaton model any additional power.
Now, we'll be revisiting the idea of languages as sets and define another way to describe a language. Recall that languages are sets and that we can perform all the usual set operations on these sets to describe new languages. We also extended some string operations to languages. We will now define a specific set of these operations to be regular operations.
Let $\Sigma$ be an alphabet and let $L,M \subseteq \Sigma^*$ be languages. The following operations are the regular operations:
So what's so special about these particular operations? These operations define what we call the class of regular languages
A language $L$ is regular if it satisfies the following definition.
Let $L_1$ and $L_2$ be regular languages.
Now, we'll prove that some very simple languages are regular, based on this definition.
Theorem. If $|L| = 1$, then $L$ is regular.
Proof. Let $L = \{w\}$. We will prove this by induction on $|w|$. If $|w| = 0$, we have $L = \{\varepsilon\}$, which is regular by definition.
Now, we consider $|w| \geq 1$ and assume that $\{u\}$ is regular for all $|u| < |w|$. Let $w = ua$ for $a \in \Sigma$ and let $L_1 = \{u\}$ and $L_2 = \{a\}$. Then $L_1$ is regular by our induction hypothesis and $L_2$ is regular by definition. Since they are both regular, we can concatenate them to get $L_1 L_2 = \{w\}$ which is regular by definition. $$\tag*{$\Box$}$$
Theorem. If $|L|$ is finite, then $L$ is regular.
Proof. We will prove this by induction on $|L|$. If $|L| = 0$, we have $L = \emptyset$, which is regular by definition.
Now, consider $|L| \geq 1$ and assume that all languages $L'$ with $|L'| < |L|$ are regular. Since $L$ is finite, we can write $L = \{w_1, w_2, \dots, w_k\}$ for some $k \geq 1$. Then $L = \{w_1, w_2, \dots, w_{k-1}\} \cup \{w_k\}$. But $\{w_1, w_2, \dots, w_{k-1}\}$ has size $k-1$ and therefore, by our induction hypothesis, it is regular and $\{w_k\}$ is regular by the previous theorem. Since $\cup$ is a regular operation, we can conclude that $L$ is regular. $$\tag*{$\Box$}$$
Earlier, it was mentioned in passing that finite automata recognize the class of regular languages. Now that we have a definition for regular languages, we should show that finite automata really can accept any regular language. In other words, we'll show formally that given any regular language, we can construct a DFA that recognizes it.
Theorem 3.7. Let $L \subseteq \Sigma^*$ be a regular language. Then there exists a DFA $M$ with $L(M) = L$.
Proof. We will show this by structural induction. Since we've already shown that they're equivalent to DFAs, we will actually just construct $\varepsilon$-NFAs for convenience.
First, for our base case, we can construct the following $\varepsilon$-NFAs for each of conditions (1–3):

Since these are pretty simple, we won't formally prove that they're correct, but you can try on your own if you wish.
Now, we will show that we can construct an $\varepsilon$-NFA for each of conditions (4–6). For our inductive hypothesis, we let $L_A$ and $L_B$ be regular languages and assume that they can be accepted by DFAs $A = (Q_A,\Sigma,\delta_A,q_{0,A},F_A)$ and $B = (Q_B,\Sigma,\delta_B,q_{0,B},F_B)$, respectively.
First, we'll consider $L_A \cup L_B$. Informally, we can make an NFA that looks like this:
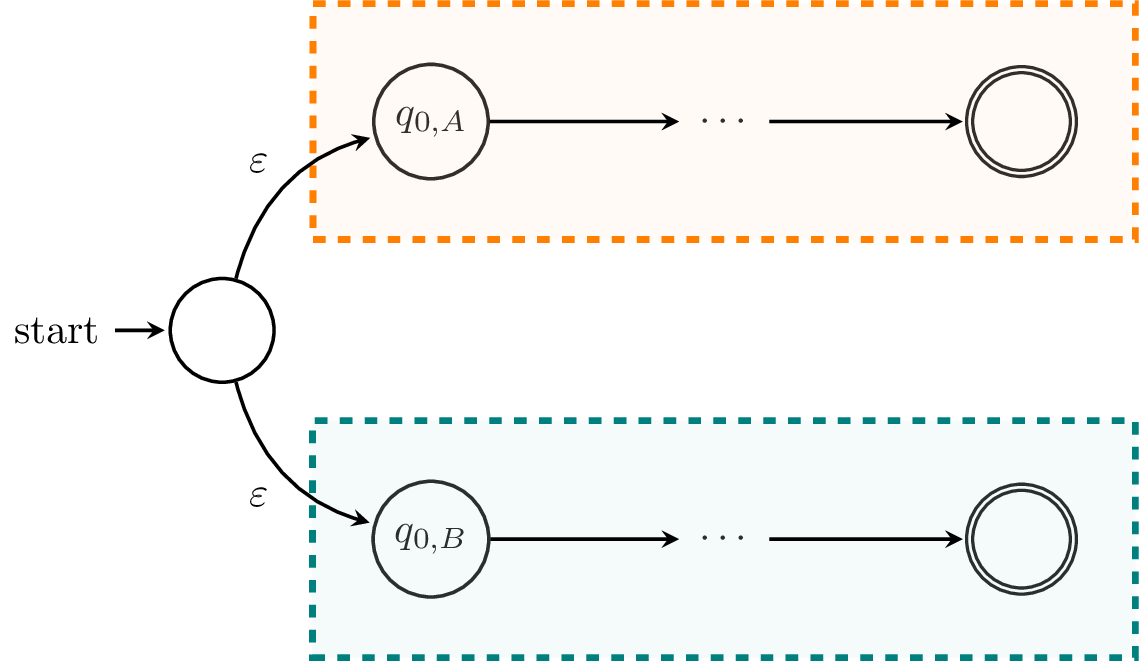
Formally, let $C = (Q_C,\Sigma,\delta_C,q_{0,C},F_C)$, where $Q_C = Q_A \cup Q_B \cup \{q_{0,C}\}$, $F_C = F_A \cup F_B$, and the transition function $\delta_C : Q_C \times (\Sigma \cup \{\varepsilon\}) \to 2^{Q_C}$ is defined by
Now, we'll show that $L(A) \cup L(B) \subseteq L(C)$. Let $w \in L(A)$. Then $\delta_A(q_{0,A},w) \in F_A$. Since we have $q_{0,A} \in \delta_C(q_{0,C},\varepsilon)$, we have a path $$ q_{0,C} \xrightarrow{\varepsilon} q_{0,A} \xrightarrow{w} \delta_A(q_{0,A},w) \in F_A \subseteq F_C.$$
If $w \in L(B)$, the proof is similar, so we can conclude that $L(A) \cup L(B) \subseteq L(C)$.
Now, we show that $L(C) \subseteq L(A) \cup L(B)$. If $w \in L(C)$, we have that $\delta_C(q_{0,c},w) \cap (F_A \cup F_B) \neq \emptyset$. Then since the only transition defined on $q_{0,C}$ is $\delta_C(q_{0,C},\varepsilon)$, we have either $\delta_A(q_{0,A},w) \in F_A$ or $\delta_B(q_{0,B},w) \in F_B$. Thus, $w \in L(A)$ or $w \in L(B)$ and we have $L(C) \subseteq L(A) \cup L(B)$. Thus, we have shown that $L(C) = L(A) \cup L(B)$.