Here is another special type of graph. Recall that showing a graph is 2-colourable amounted to dividing the vertices up into two sets (or a partition) so that all of the edges of the graph only travel between these two sets. This gives us another special type of graph.
A graph $G = (V,E)$ is bipartite if $V$ is the disjoint union of two sets $V_1$ and $V_2$ such that all edges in $E$ connect a vertex in $V_1$ with a vertex in $V_2$. We say that $(V_1, V_2)$ is a bipartition of $V$.
We get the following characterization of bipartite graphs for free from the definition of 2-colourability.
A graph $G$ is bipartite if it is 2-colourable.
Similar to the idea of complete graphs, we can define complete bipartite graphs.
The complete bipartite graph on $m$ and $n$ vertices is the graph $K_{m,n} = (V,E)$, where $(V_m,V_n)$ is a bipartition of $V$ with $|V_m| = m$ and $|V_n| = n$, and $$E = \{(u,v) \mid u \in V_m, v \in V_n \}.$$
So with all of these different kinds of structural properties, what we would like is some easy to compute graph invariants that tell us that we do have an isomorphism, so we don't have to search over $n!$ different possible mappings. Unfortunately, we don't know of any that exist, so graph isomorphism remains difficult to solve. The question of exactly how difficult of a problem it is is also still an open question. First, let's define the notion of a subgraph.
A graph $G' = (V',E')$ is a subgraph of a graph $G = (V,E)$ if $V' \subseteq V$ and $E' \subseteq E$. The subgraph induced by a subset $V' \subseteq V$ is the largest subgraph of $G$ with vertex set $V'$. We say that $G'$ is a spanning subgraph if $V' = V$.
Consider the graphs from Example 7.35:
One graph contains $K_3$ as a subgraph (or alternatively contains a subgraph isomorphic to $K_3$), while the other does not.
The subgraph isomorphism problem asks whether given graphs $G$ and $H$ whether there is a subgraph of $G$ that is isomorphic to $H$. This problem is known to be hard to solve: it's NP-complete, which means that if we have a solution for the problem, we can check it efficiently, but we have no efficient algorithms for solving it. It's not hard to see that graph isomorphism is a special case of subgraph isomorphism.
A natural impulse when presented with a bunch of circles joined by lines is to see if we can get from one circle to another by following the lines. More formally, when we do this, what we're doing is checking if an object is connected to another object. It's not surprising to learn that this is a fundamental property of graphs that we'd like to work with.
A walk of length $k$ is a sequence of $k+1$ vertices $v_0, v_1, \cdots, v_k$ such that $v_{i-1}$ and $v_i$ are adjacent for $1 \leq i \leq k$. This walk has length $k$ because we traverse $k$ edges. A path is a walk without repeated vertices. A cycle or circuit of length $k$ is a path with $v_0 = v_k$.
Consider the following graphs.
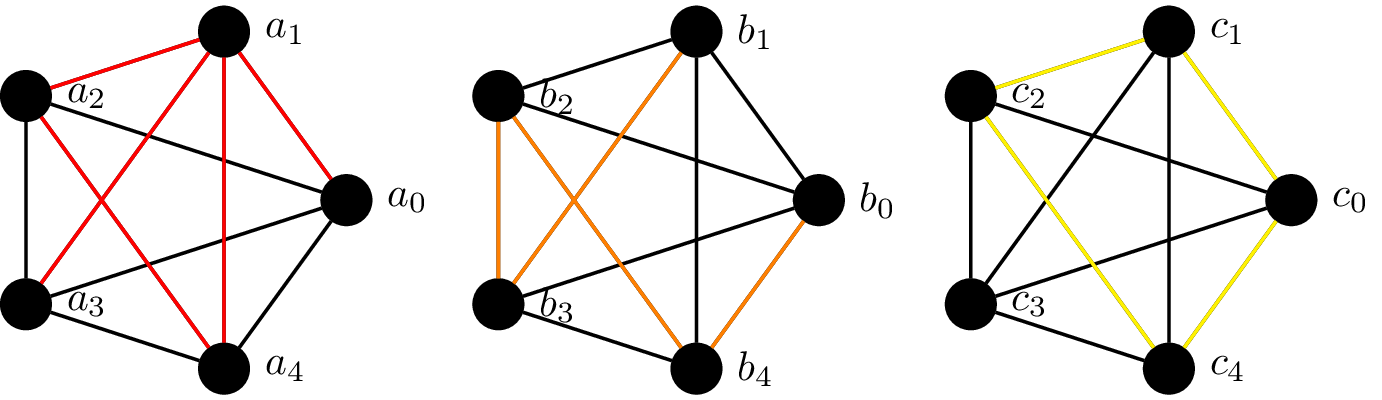
In the first, the walk $a_0 a_1 a_4 a_2 a_1 a_3$ is highlighted in red. In the second, the path $b_0 b_4 b_2 b_3 b_1$ is highlighted in orange. In the third, the cycle $c_0 c_4 c_2 c_1 c_0$ is highlighted in yellow.
Note that the above definitions are not universal and you should be very careful when consulting other materials (e.g. sometimes they use path when we mean walk).
Before we proceed, here is a simple theorem about walks and paths and how the fastest way between point $a$ and $b$ is a straight line.
Let $G$ be a graph and $u,v \in V$ be vertices. If there is a walk from $u$ to $v$, then there is a path from $u$ to $v$.
Consider the walk $u = v_0 v_1 \cdots v_k = v$ from $u$ to $v$ of minimum length $k+1$. Suppose that a vertex is repeated. In other words, there exist, $i, j$ with $i \lt j$ such that $v_i = v_j$. Then we can create a shorter walk $$u = v_0 v_1 \cdots v_{i-1} v_i v_{j+1} v_{j+2} \cdots v_k = v,$$ since $(v_i,v_{j+1}) = (v_j,v_{j+1})$. Then this contradicts the minimality of the length of our original walk. So there are no repeated vertices in our walk and therefore, it is a path by definition.
Another sort of 'common sense' theorem says that if we have two distinct paths, meaning they're not the same path, then we have a cycle in our graph. Be careful: distinct doesn't mean disjoint. In other words, the two paths can share some edges, but will contain different edges at some point.
Let $G = (V,E)$ be a graph and let $u,v \in V$. If there are two distinct paths between $u$ and $v$, then $G$ contains a cycle.
Consider two paths $P_1$ and $P_2$ between vertices $u$ and $v$. We can write $P_1 = a_0 a_1 \cdots a_m$ and $P_2 = b_0 b_1 \cdots b_n$, where $a_0 = b_0 = u$ and $a_m = b_n = v$, with $m$ not necessarily equal to $n$. Since the two paths are distinct, there is an edge that is in $P_1$ that is not in $P_2$. Let $(a_i,a_{i+1})$ be this edge.
Consider the graph $G - (a_i,a_{i+1})$. Now, consider the walk $$a_i a_{i-1} \cdots a_0 = u = b_0 b_1 \cdots b_n = v = a_n a_{n-1} \cdots a_{i+1}.$$ This is a walk from $a_i$ to $a_{i+1}$ which does not use the edge $(a_i, a_{i+1})$. Therefore, there $a_i$ and $a_{i+1}$ are in the same component and the edge $(a_i,a_{i+1})$ participates in a cycle. Therefore, $G$ contains a cycle.
What does it mean if there's a walk between two vertices? Practically speaking, it means that we can reach one from the other. This idea leads to the following definition.
A graph $G$ is connected if there is a walk between every pair of vertices.
The graphs that we've seen so far have mostly been connected. However, we're not guaranteed to work with connected graphs, especially in real-world applications. In fact, we may want to test the connectedness of a graph. For that, we'll need to talk about the parts of a graph that are connected.
A connected component of a graph $G = (V,E)$ is a connected subgraph $G'$ of $G$ that is not a proper subgraph of another connected subgraph of $G$.
Consider the following graph.
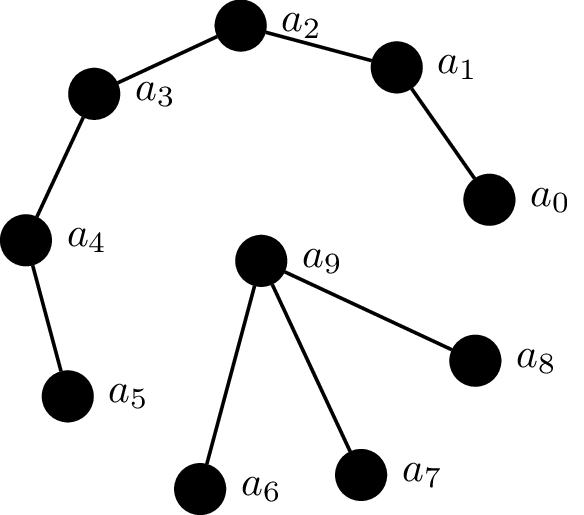
This graph has two connected components, the subgraphs induced by $a_0,\dots, a_5$ and $a_6,\dots,a_9$. No other can be considered a connected component since they would either be not connected or a proper subgraph of one of the two connected components we identified.
Another question related to connectivity that we can ask is how fragile the graph is. For instance, if we imagine some sort of network (computer, transportation, social, etc.), this is the same as asking where the points of failure are in our network. Which vertices or edges do we need to take out to disconnect our graph?
Let $G = (V,E)$ be a graph and consider a vertex $v \in V$. If removing $v$ and its incident edges increases the number of connected components, then $v$ is a cut vertex or articulation point. Similarly, consider an edge $e \in E$. If removing $e$ increases the number of connected components, then $e$ is a cut edge or bridge.
Consider the following graph $G$. There are two obvious bridges here: $(a_3,c_2)$ and $(b_2,c1)$. And the vertices incident to the bridges are the cut vertices of the graph.
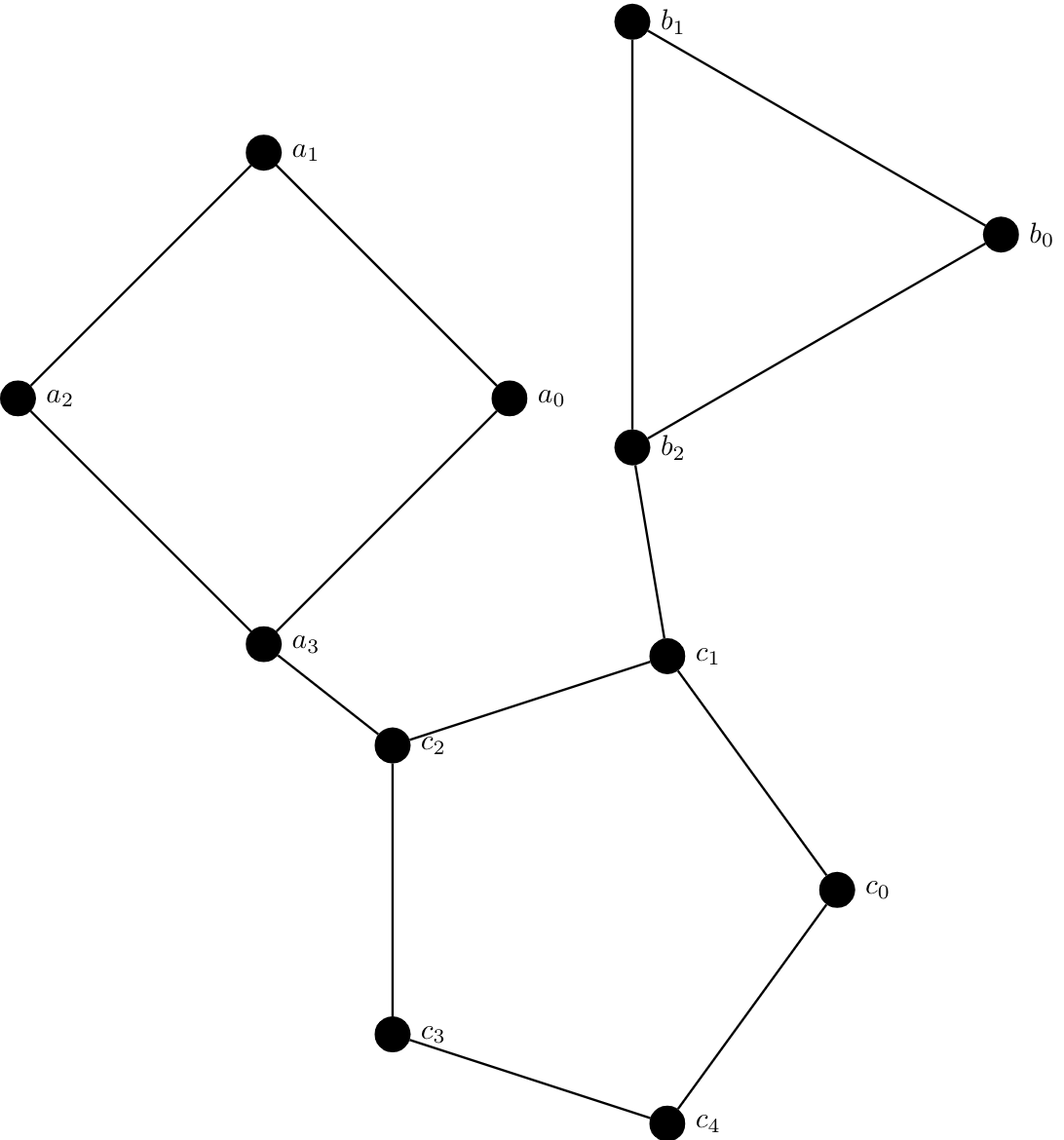
We would like to be able to identify which vertices are bridges and their properties. The following lemma is one of those results that sounds incredibly obvious based on the definitions involved and our intuition.
Let $G$ be a connected graph. If $(u,v) \in E$ is a bridge, then $G - (u,v)$ (the subgraph of $G$ with only the edge $(u,v)$ deleted) has exactly two components and $u$ and $v$ are in different components.
Since $(u,v)$ is a bridge, we know that $G - (u,v)$ has at least two components. Let $X$ be the set of vertices that in the same component as $u$. Choose some vertex $x \not \in X$. Then $x$ is not in the same component as $u$. Since $G$ was connected, $G$ contained a path between $u$ and $x$ and there are no paths in $G - (u,v)$. Thus, any path from $u$ to $x$ must have contained the edge $(u,v)$. These paths must have the form $uv v_2 v_4 \cdots v_{n-1} x$.
Then $v v_2 \cdots v_{n-1} x$ is a path in $G - (u,v)$ and therefore $v$ and $x$ are in the same component. But recall that the choice of $x \not \in X$ was arbitrary. This means that there exists a path from $u$ to every vertex $x \not \in X$. Therefore, $G - (u,v)$ has two components, and $u$ and $v$ are in different components.
We can use this to get the following important characterization of bridges which is maybe not quite as obvious.
Let $G$ be a graph. An edge $e$ of $G$ is a bridge if and only if it is not contained in any cycle of $G$.
For the forward direciton, we assume that $e = (u,v)$ is a bridge. Suppose that $e$ is in a cycle, say $u v v_2 \cdots v_{n-1} u$. Now consider $G - e$. Note that $v v_2 \cdots v_{n-1} u$ is a path between $u$ and $v$, so $u$ and $v$ are in the same component. But this contradicts Lemma 19.9. Therefore, $e$ is not in a cycle of $G$.
For the reverse direction, we assume that $e = (u,v)$ is not in a cycle. Suppose that $e$ is not a bridge. Then $u$ and $v$ are in the same component in the graph $G - e$. Therefore, there is a path between $u$ and $v$, say $u v_2 \cdots v_{n-1} v$. However, this means that $u v_2 \cdots v_{n-1} vu$ is a cycle in $G$, which is a contradiction. Therefore, $e$ is a bridge.
Now that we've identified special kinds of edges that, in a sense, must be present in order to have a connected graph, we can ask which kinds of graphs are in a sense minimally connected. We can think of such graphs as forming the backbone of a more "full" graph. These graphs are called trees.
As computer scientists, we tend to think of trees when they're organized with the root at the top and growing downwards (apparently trees grow upside-down) as in family trees or organizational charts. However, the following definition gives us something more concrete to work with and we'll see that some results we've proven about cycles will come into play.
A graph $G$ is a tree if $G$ is connected and contains no cycles. A graph $G$ with no cycles is a forest.
The following are examples of trees.
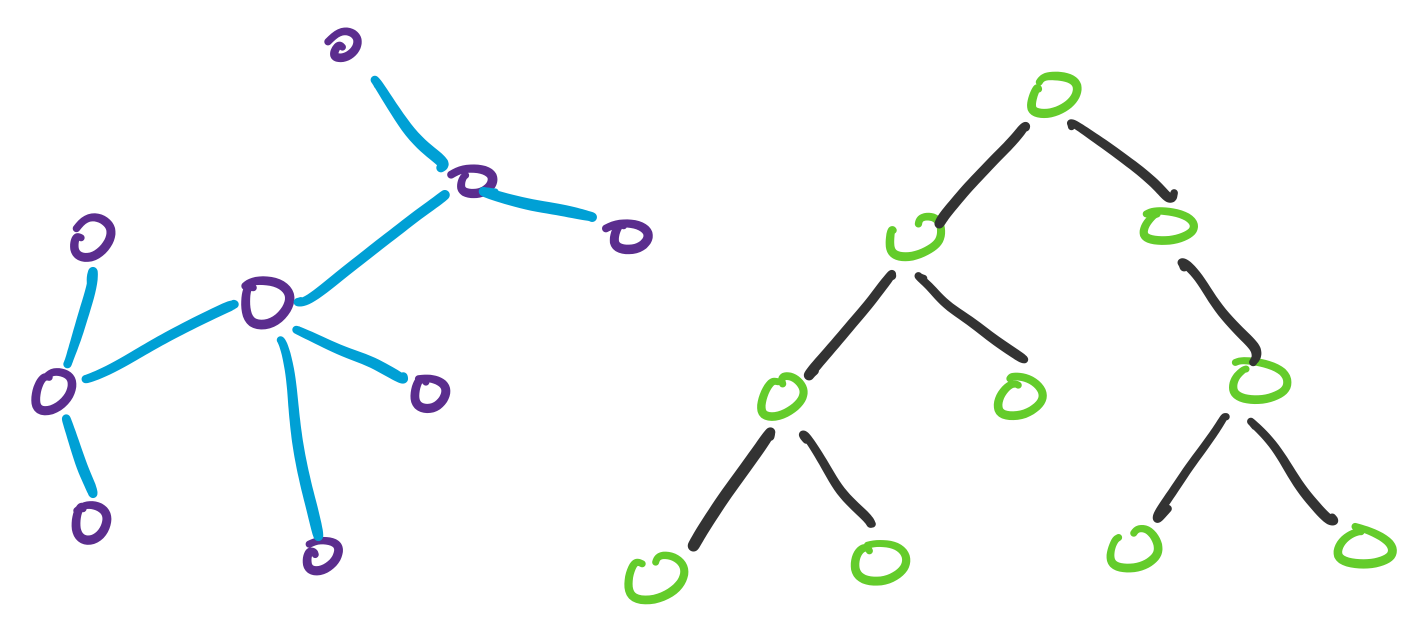
Note that the definition of a tree is quite simple, but it has a clear connection with our discussion of bridges and connectivity. Since a tree has no cycles, this means that every edge in a tree is a bridge. In other words, removing any edge in the graph will disconnect it.
A graph $G$ is a tree if and only if there is a unique path between any two vertices in $G$.
Suppose $G$ is a tree. Then $G$ is connected and has no cycles. Consider a pair of vertices $u, v$. Since $G$ is connected, there is a path between $u$ and $v$. Since $G$ contains no cycles, this path must be unique. Otherwise, if there were a second path, we can form a cycle.
Now suppose that every pair of of vertices $u$ and $v$ in $G$ has a unique path between them. Then $G$ is connected. Now, suppose for contradiction that $G$ contains a cycle and $u$ and $v$ are part of this cycle. The cycle exhibits two paths between $u$ and $v$, contradicting our assumption that there is a unique path between $u$ and $v$. Thus, $G$ does not contain any cycles. Therefore, $G$ is a tree.
If we take the idea of a tree as minimally connected, then we can also conclude that adding edges will "beef up" the connectivity of the graph.
Let $T$ be a tree. Adding an edge between any two non-adjacent vertices creates a cycle.
Consider two non-adjacent vertices $u,v$ in $T$. Since $T$ is a tree, there is a path from $u$ to $v$ in $T$. Now let $T' = T \cup (u,v)$, the graph with the edge $(u,v)$ added. There are now two distinct paths between $u$ and $v$: the original path in $T$ and the path consisting of the edge $(u,v)$. Therefore, $T'$ contains a cycle. (In fact, since $(u,v)$ is disjoint from the path, the path together with $(u,v)$ forms the unique cycle.)
How many edges does a "minimally connected" graph have? It turns out there is a definitive answer.
A tree $T$ with $n$ vertices has $n-1$ edges.
We will show this by mathematical induction on $n$.
Base case. We have $n = 1$, and therefore, our graph contains $0 = 1 - 1$ edges, so our statement holds.
Inductive case. Let $k \in \mathbb N$ and assume that every tree $T'$ with $k$ vertices has $k-1$ edges. Now, consider a tree $T = (V,E)$ with $k+1$ vertices. Choose a leaf $v$ and consider its neighbour $u$. Consider the subgraph of $S = (V \setminus \{v\}, E \setminus \{(u,v)\})$ without $v$. Then $S$ has $k$ vertices. By the inductive hypothesis, $S$ has $k-1$ edges. Since we only removed one edge from $T$ to obtain $S$, $T$ must have $k = (k+1)-1$ edges as desired.
We can apply the idea of a tree as a minimally connected graph to say something about connectivity in graphs in general. One clear application is finding a minimal connected subgraph of the graph such that every vertex is connected. One can see how this might be useful in something like road network where you're trying to figure out what the most important roads to clear after a snowfall are.
A spanning subgraph which is also a tree is called a spanning tree.
Here is a graph, with one possible spanning tree highlighted.
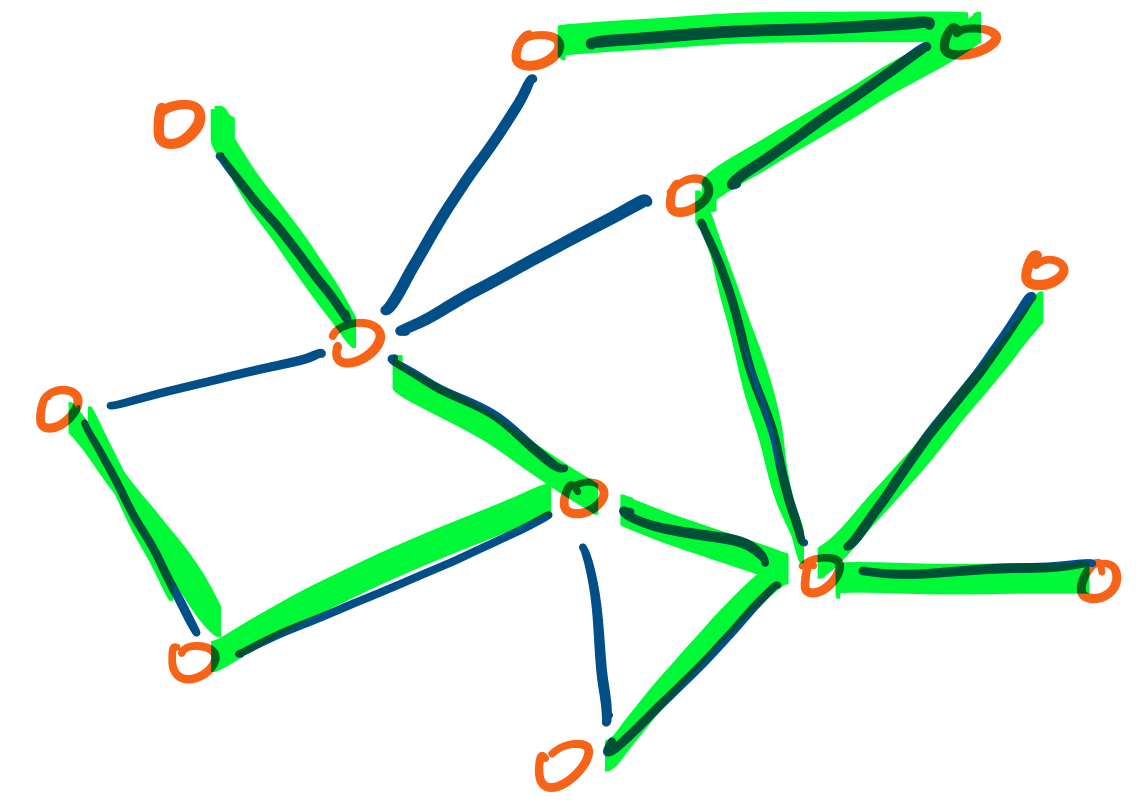
A graph $G$ is connected if and only if it has a spanning tree.
Suppose $G$ has a spanning tree $T$. Then there exists a path between every pair of vertices in $T$ and therefore, there exists a path between every pair of vertices in $G$. Then by definition, $G$ is connected.
Now, suppose $G$ is connected. Consider the connected spanning subgraph $H$ of $G$ with the minimal number of edges. Suppose $H$ contains a cycle. Then we can remove an edge from this cycle, since no edge in a cycle is a bridge. Therefore, $H$ contains no cycles and since $H$ is connected, it is a tree.
An obvious computational problem is to find or construct spanning trees in a given graph.
Very often, in computer science, we are concerned with binary trees as fundamental structures. These trees have a specific form which gives rise to even more special properties.
A rooted tree is a tree in which one vertex has been designated as the root. Let $T = (V,E)$ be a rooted tree and let $r$ be the root of $T$.
Here is a ternary or 3-ary tree. It is not a full tree. The root of the tree is highlighted in red. The leaves are highlighted in green. The yellow vertex is the parent of the cyan vertex, and the cyan vertex is its child. The magenta vertex is an ancestor of the yellow and cyan nodes, and they are its descendants. The subtree rooted at the magenta vertex is the subgraph induced by it and its descendants.
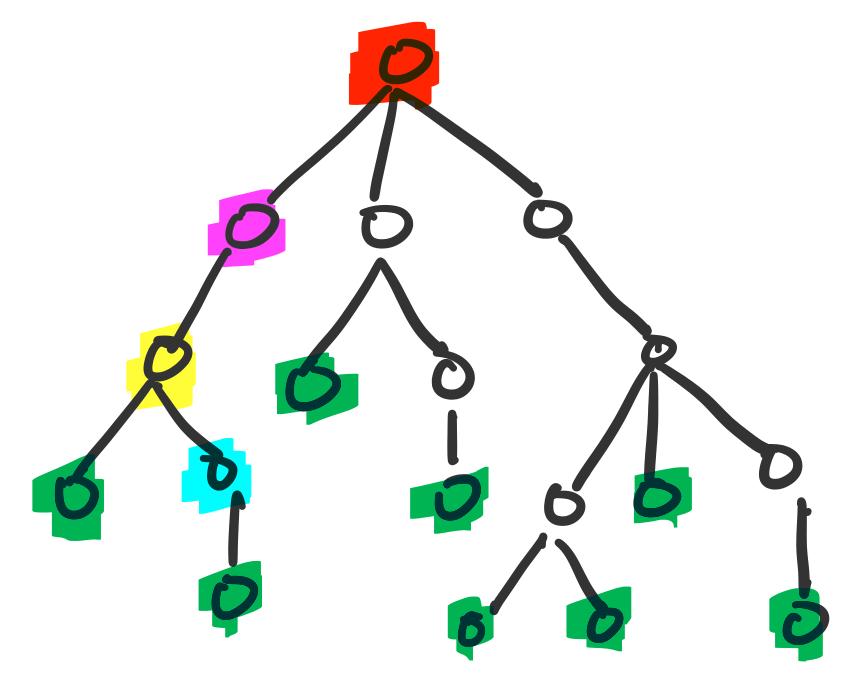
For simiplicity, we will restrict our attention to binary trees. However, many of these results can generalize quite easily to $n \gt 2$. The notion of a subtree is quite useful for proving properties of rooted trees by induction. However, this suggests something quite interesting: why not define the notion of a binary tree inductively? Here is the standard computer science definition for a binary tree.
A binary tree is
There are some notable differences with the graph theoretic notion. For one thing, trees are allowed to be empty. Also implicit in this definition is the idea of the binary tree as a data structure that is meant to store things. In this view, the node is an object that holds a value and links to the subtrees.
Just as we saw at the beginning of the quarter, these kinds of definitions translate quite nicely to programs. Well, almost. It is less nice in an imperative language like Python, so I'll demonstrate using Racket.
(define-type BinaryTree (U 'Empty Node))
(define-struct Node
([value : Integer]
[left-sub : BinaryTree]
[right-sub : BinaryTree]))Notice how the definition maps on to the definition of the type. In the first line, we have that the BinaryTree is a union of either the symbol 'Empty or a structure Node. And what is a Node? It's a structure that contains a value, of type Integer, a left subtree, and a right subtree.
Let's see how this is useful by defining something. If we reinterpret the height of a binary tree to mean "nodes" rather than "vertices", we get the following.
Let $T$ be a binary tree and let $h(T)$ denote the height of $T$. Then
Notice that the definition "works" even when the subtrees are empty. This definition gives us the following recursive algorithm.
(: tree-height (-> BinaryTree Integer))
(define (tree-height t)
(match t
['Empty 0]
[(BinaryTree _ left right)
(+ 1 (max (tree-height left) (tree-height right)))]))Here, we have defined a function tree-height which takes a BinaryTree and produces an Integer. Then t is matched (a fancy functional programming idiom): since it's a BinaryTree, it's either 'Empty or a Node. If it's 'Empty, then it has height 0.
If t is a Node, then it's a structure consisting of a value, a left subtree, and right subtree, in that order according to our definition. We can ignore the value since it's not used and we retrieve and locally name the left subtree left and the right subtree right. We recursively call tree-height on left and right, take the maximum, and add 1 and return the result.