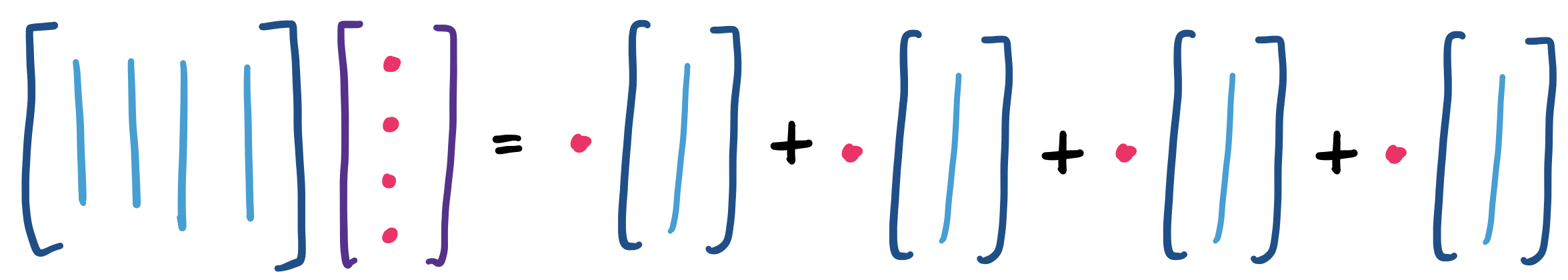
Recall that linear algebra revolves around the idea of linear combination, the act of scaling and adding vectors to create or describe other vectors. In doing so, we will often be concerned with collections of vectors. In service of this, we introduce the other big object in the study of linear algebra: the matrix. Matrices are a convenient object that puts these vectors together so we can consider them as one "thing".
An $m \times n$ matrix is a rectangle of $m \times n$ scalars. Such a matrix has $m$ rows and $n$ columns.
Here are some examples of matrices: \[\begin{bmatrix} 3 \end{bmatrix}, \begin{bmatrix} -7 \\ 6 \\ 5 \end{bmatrix}, \begin{bmatrix}3 & 1 & -5 \end{bmatrix}, \begin{bmatrix}2 & 4 \\ 3 & 4 \end{bmatrix}, \begin{bmatrix}3 & 4 & 6 \\ 9 & 6 & 1 \end{bmatrix}.\]
In NumPy, a matrix is nothing more than a 2-dimensional array. Simple enough, but there are some things to be careful about.
>>> A = np.array([[3]])
>>> B = np.array([[-7], [6], [5]])
>>> C = np.array([[3, 1, -5]])
>>> D = np.array([[2, 4], [3, 4]])
>>> E = np.array([[3, 4, 6], [9, 6, 1]])
One of the things to watch out for here is that there are some things that we treat as equivalent in mathematics that Python does not, without being explicit about it. For example, we've previously seen that a vector $\begin{bmatrix} 7 \\ 6 \\ 5 \end{bmatrix}$ is represented by a 1D array [7, 6, 5]. However, from above, we can see that this can also be represented as the 2D array [[7], [6], [5]]. But since a 1D array and 2D array are different types, these two objects aren't treated the same way. Similarly, 3, [3], and [[3]] all mean $3$ mathematically, but are different values with different types in Python.
This means that we often have to explicitly cast objects to the right shape before we can work with them. NumPy arrays have a reshape method that allows us to create a new object with the desired "shape" from the given array, under the constrant that the shape makes sense (i.e. a $2 \times 3$ matrix can't have only 5 entries in it).
>>> A = np.array([1, 3, 2])
>>> A
array([1, 3, 2])
>>> A.reshape(3,1)
array([[1],
[3],
[2]])
>>> A.reshape(2,2)
ValueError: cannot reshape array of size 3 into shape (2,2)
We refer to a particular entry of the matrix by two indices $i$ and $j$, where $i$ is the row and $j$ is the column. So if $A = \begin{bmatrix}2 & 3 \\ 4 & -1 \\ 5 & 1 \end{bmatrix}$, then $A_{3,1} = 5$ and $A_{1,2} = 3$.
Accessing entries in NumPy arrays is similar. However, since Python is 0-indexed, these indices need to begin at 0. This is important to remember if you're moving back and forth between math and code.
>>> A = np.array([[2, 3], [4, -1], [5, 1]])
>>> A[3, 1]
IndexError: index 3 is out of bounds for axis 0 with size 3
>>> A[2, 0]
5
>>> A[2][0]
5
Like vectors, the "real" formal definition of a matrix is much more general and less recognizable than what most people would consider to be a matrix. And like the formal definition of vectors, the formal definition of a matrix is not so important in our context.
First, we'll consider what we can do with a matrix. In other words, what are the operations we want to perform on it? One thing we can do is multiply a matrix by a vector to get another vector.
Let $A = \begin{bmatrix} 2 & -4 \\ -3 & 4 \end{bmatrix}$ and $\mathbf v = \begin{bmatrix} 1 \\ 5 \end{bmatrix}$. We want to compute the product \[A \mathbf v = \begin{bmatrix} 2 & -4 \\ -3 & 4 \end{bmatrix}\begin{bmatrix} 1 \\ 5 \end{bmatrix} = \begin{bmatrix} -18 \\ 17 \end{bmatrix}.\]
>>> A = np.array([[2, -4], [-3, 4]])
>>> v = np.array([1, 5])
>>> A @ v
array([-18, 17])
What does this mean? In a sense, we can view the vector $\mathbf v$ as encoding a linear combination of the vectors that form the columns of $A$. That is, \[ A \mathbf v = 1 \begin{bmatrix} 2 \\ -3 \end{bmatrix} + 5 \begin{bmatrix} -4 \\ 4 \end{bmatrix} = \begin{bmatrix} 2 \\ 3 \end{bmatrix} + \begin{bmatrix} -20 \\ 20 \end{bmatrix} = \begin{bmatrix} -18 \\ 17 \end{bmatrix}.\]
>>> A[:,0] * v[0]
array([ 2, -3])
>>> A[:,1] * v[1]
array([-20, 20])
>>> A[:,0] * v[0] + A[:,1] * v[1]
array([-18, 17])
In other words, the product of a matrix $A$ and a vector $\mathbf v$ is a linear combination of the columns of $A$!
There is an alternative view of this product. If $b_i$ is the $i$th entry of the vector $\mathbf b = A \mathbf v$, we can get this by finding \[b_i = A_{i,1} v_1 + A_{i,2} v_2 + \cdots + A_{i,n} v_n.\]
So from above, \[ A \mathbf v = \begin{bmatrix} 2 \times 1 + -4 \times 5 \\ -3 \times 1 + 4 \times 5 \end{bmatrix} = \begin{bmatrix} -18 \\ 17 \end{bmatrix}. \]
>>> A[0] @ v
-18
>>> A[1] @ v
17
>>> np.array([A[0] @ v, A[1] @ v])
array([-18, 17])
But those expressions look very familiar. Some observation can lead us to conclude that a more succinct description of this process is that we consider each row of the matrix as a vector and take its dot product with $\mathbf v$ to get the corresponding entry. A lot of people like this definition because it's very computational: it tells us how each entry is computed.
These two approaches highlight a key difference in how we view the objects that we're studying. A traditional approach will focus on computation: what are the numbers that we get out of a procedure? But what we want to do is understand the structure of the objects and the way to do this is to see how they're formed by the operations that we're interested in.
Let's generalize this.
Let $A = \begin{bmatrix}\mathbf u & \mathbf v & \mathbf w\end{bmatrix}$ be a matrix with column vectors $\mathbf u, \mathbf v, \mathbf w$. Let $\mathbf x = \begin{bmatrix}x_1 \\ x_2 \\ x_3 \end{bmatrix}$. Then \[A\mathbf x = \begin{bmatrix}\mathbf u & \mathbf v & \mathbf w\end{bmatrix} \begin{bmatrix}x_1 \\ x_2 \\ x_3 \end{bmatrix} = x_1 \mathbf u + x_2 \mathbf v + x_3 \mathbf w.\] And, \[x_1 \mathbf u + x_2 \mathbf v + x_3 \mathbf w = x_1 \begin{bmatrix}u_1 \\ u_2 \\ u_3 \end{bmatrix} + x_2 \begin{bmatrix} v_1 \\ v_2 \\ v_3 \end{bmatrix} + x_3 \begin{bmatrix} w_1 \\ w_2 \\ w_3 \end{bmatrix} = \begin{bmatrix} x_1 u_1 + x_2 v_1 + x_3 w_1 \\ x_1 u_2 + x_2 v_2 + x_3 w_2 \\ x_1 u_3 + x_2 v_3 + x_3 w_3 \end{bmatrix}.\]
We can think about this visually. First, if we view the matrix-vector product as a linear combination of the columns of the matrix, we see something like
And if we think about the product as entries that are formed from dot products of the vector with the rows of the matrix, we have
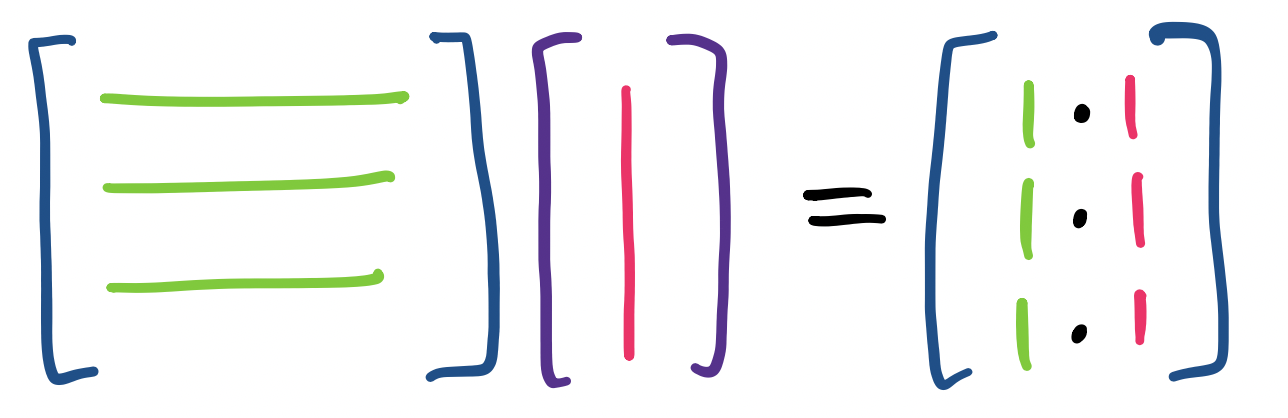
So now, it's worth thinking about what a matrix means or represents. That a matrix has rows and columns provides two immediate interpretations. One is to view the matrix as a collection of rows. This is the view that one would arrive at directly from algebra. The rows correspond to linear equations and so the matrix represents a system of linear equations.
The second is to view the matrix as a description for a collection of vectors. These vectors are linear combinations of the columns of the matrix. Of course, the system of linear equations describes the exact same set of vectors. But this is a very useful trick in math—certain problems make more sense from a particular perspective.
This idea is so important that it has a name. The linear combinations of the columns of a matrix $A$ is called the column space of $A$.
Why is this important? This view of a matrix as a description of vectors provides a window into some of the things that we try to accomplish in machine learning and data science. It's not hard to see that we can envision a matrix very plainly as a table of data, where a column represents an object and a row represents a particular attribute. This matrix is likely to be very large, so what we really want is a way to describe what's special about the matrix succinctly.
If we consider this question from the perspective of linear algebra, what we're really looking to do is find a simpler way to describe the space of vectors represented by this matrix. Equivalently, this means trying to come up with a smaller matrix that captures a lot of the same patterns as our original matrix of data.
The promise of linear algebra is that because these are all matrices, the functions or operators are all linear. Because linear algebra is pretty well understood, this means we can play around with the tools of linear algebra to come up with such an approximation instead of trying to invent all sorts of new math.
This fact is actually kind of amazing. After all, why should linear methods be sufficient for working with large data? Why is it that we don't have to stretch ourselves and go do something more complicated like use fancier polynomials? It's a good thing we don't, because it's much harder to work with more complicated mathematics, both for the people working on this stuff and in terms of the computational power required.
In this sense, we can think of $A$ as a function on vectors. Here, $A$ takes a vector $\mathbf x$ as input and produces another vector as output. Then we can think of $A$ as a description of a particular set of vectors. This is the perspective that machine learning tries to take: the learning in machine learning is about "learning" a function, or trying to come up with a good approximation of the original function.
When thinking about the linear combinations of the columns of a matrix, something we might wonder is whether we really need all of them.
Let $A = \begin{bmatrix} 1 & 2 & 4 \\ 3 & -2 & 4 \\ 2 & 3 & 7 \end{bmatrix}$. If we label the columns of $A$ by $\mathbf a_1, \mathbf a_2, \mathbf a_3$, then we observe that $\mathbf a_3 = 2\mathbf a_1 + \mathbf a_2$.
>>> A = np.array([[1, 2, 4], [3, -2, 4], [2, 3, 7]])
>>> 2 * A[:,0] + A[:,1]
array([4, 4, 7])
In other words we have a column in our matrix that is a linear combination of the others. If we view $A$ as a description or function that produces matrices, what this tells us that we could remove that column and we would still be able to get all the vectors we had before. How?
Suppose we have $\mathbf v = \begin{bmatrix} 3 \\ -1 \\ 5 \end{bmatrix}$. Then by definition, $A \mathbf v = 3 \begin{bmatrix} 1 \\ 3 \\ 2 \end{bmatrix} + -1 \begin{bmatrix} 2 \\ -2 \\ 3 \end{bmatrix} + 5 \begin{bmatrix} 4 \\ 4 \\ 7 \end{bmatrix}$. But remember that we can write the final column of $A$ in terms of the other two, so we have \[A \mathbf v = 3 \begin{bmatrix} 1 \\ 3 \\ 2 \end{bmatrix} + -1 \begin{bmatrix} 2 \\ -2 \\ 3 \end{bmatrix} + 5 \left(2\begin{bmatrix}1 \\ 3 \\ 2\end{bmatrix} + \begin{bmatrix} 2 \\ -2 \\ 3 \end{bmatrix} \right) = 13\begin{bmatrix}1 \\ 3 \\ 2\end{bmatrix} + 4 \begin{bmatrix} 2 \\ -2 \\ 3 \end{bmatrix} \]
>>> v = np.array([3, -1, 5])
>>> A @ v
array([21, 31, 38])
>>> 3 * A[:,0] - A[:,1] + 5 * (2 * A[:,0] + A[:,1])
array([21, 31, 38])
>>> 13 * A[:,0] + 4 * A[:,1]
array([21, 31, 38])
This is the idea of linear independence. While we thought about this in terms of the columns of a matrix, independence is really something about a set of vectors.
A set of vectors $\mathbf v_1, \mathbf v_2, \dots, \mathbf v_n$ is linearly independent if no vector $\mathbf v_i$ can be written as a linear combination of the other vectors in the set. Otherwise, such a set of vectors is said to be dependent.
Above, we saw the math: we can write a vector as a linear combination of the others. But what does this say intuitively about all of the vectors we get from linear combinations of our columns (i.e. the column space)?
If we have two linearly dependent vectors, then they're multiples of each other. What are all the linear combinations? If we add an independent vector, what happens to the space of vectors we can describe?
In other words, adding a vector that is independent from the ones we already have gives us a new direction or dimension and a whole bunch of other vectors we can describe using linear combinations.
There are some fairly obvious consequences from this. The first is observing that many matrices will contain more columns than we may need, in the sense that we can describe the same set of vectors using fewer columns. In a way, we can think of linearly dependent columns to be superfluous.
From a data perspective, this tells us something very interesting as well. It's easy to imagine a data table of, say, thousands of columns. How likely is it that even a small number of these are linearly independent? This suggests that one of the things we might want to do is to find a way to describe the same set of vectors but using far fewer columns. In doing so, we can reason that we pick out the most important vectors that say something interesting about our data.
Let's say we want a list or matrix $C$ of linearly independent columns from $A$. There's a very simple algorithm to do this:
Basically, just go through each column of $A$ and check if it's a linear combination of the vectors we've chosen to be in $C$ already. Then if we view $C$ as sticking all of the columns we chose together, we have a matrix that is made up entirely of independent columns. The trick here of course is that checking whether a column is a linear combination of some set of vectors is not quite as easy as we've made it seem.
Of course, while we've talked about identifying columns that are dependent, there's also the question of how many we "need"? Can we construct a matrix with arbitrarily many independent columns? Or is there a point where any column we add is going to be dependent, no matter what?
This leads to a suite of questions we can ask about any particular matrix:
On a final note, if we observe our example matrix from before, we recall that we could get rid of that last column. We have \[A \mathbf v = \begin{bmatrix} 1 & 2 & 4 \\ 3 & -2 & 4 \\ 2 & 3 & 7 \end{bmatrix} \begin{bmatrix} 3 \\ -1 \\ 5 \end{bmatrix} = \begin{bmatrix}1 & 2 \\ 3 & -2 \\ 2 & 3 \end{bmatrix} \begin{bmatrix} 13 \\ 4 \end{bmatrix} = C \mathbf x.\]
>>> A @ v
array([21, 31, 38])
>>> A[:,[0,1]]
array([[ 1, 2],
[ 3, -2],
[ 2, 3]])
>>> A[:,[0,1]] @ np.array([13, 4])
array([21, 31, 38])
Something to note here is that although we don't need that extra column, this does change what our vector needs to be to get the same vector, since (naturally) the exact nature of the linear combination changes. This suggests that there's some information somewhere that the extra column represents that we need to account for somehow.
Observe that we didn't really talk about what sizes our matrices and vectors need to be when we multiply them together. Instead, we can probably piece together that our vector needs to have as many components as there are columns of the matrix, since this is supposed to represent a particular linear combination. We can generalize this idea.
Let's return to this example from above. We have \[A \mathbf v = \begin{bmatrix} 1 & 2 & 4 \\ 3 & -2 & 4 \\ 2 & 3 & 7 \end{bmatrix} \begin{bmatrix} 3 \\ -1 \\ 5 \end{bmatrix} = \begin{bmatrix}1 & 2 \\ 3 & -2 \\ 2 & 3 \end{bmatrix} \begin{bmatrix} 13 \\ 4 \end{bmatrix} = C \mathbf x.\] Clearly, the vectors $\mathbf v$ and $\mathbf x$ are different. How do we account for this difference, especially if we're interested in reconstructing $A$ based on $C$?
Well, we know how to describe linear combinations of columns of a matrix to get one vector. And we know how to describe each column of $A$ as a linear combination of columns of $C$: \[\begin{bmatrix}1 & 2 \\ 3 & -2 \\ 2 & 3 \end{bmatrix} \begin{bmatrix} 1 \\ 0 \end{bmatrix} = \begin{bmatrix} 1 \\ 3 \\ 2 \end{bmatrix}, \quad \begin{bmatrix}1 & 2 \\ 3 & -2 \\ 2 & 3 \end{bmatrix} \begin{bmatrix} 0 \\ 1 \end{bmatrix} = \begin{bmatrix} 2 \\ -2 \\ 3 \end{bmatrix}, \quad \begin{bmatrix}1 & 2 \\ 3 & -2 \\ 2 & 3 \end{bmatrix} \begin{bmatrix} 2 \\ 1 \end{bmatrix} = \begin{bmatrix} 4 \\ 4 \\ 7 \end{bmatrix}.\]
But since a matrix is a collection of vectors, why not make use of this and write: \[\begin{bmatrix}1 & 2 \\ 3 & -2 \\ 2 & 3 \end{bmatrix} \begin{bmatrix} 1 & 0 & 2 \\ 0 & 1 & 1 \end{bmatrix} = \begin{bmatrix} 1 & 2 & 4 \\ 3 & -2 & 4 \\ 2 & 3 & 7 \end{bmatrix} = A.\]
And so we have invented matrix multiplication: the product of two matrices $C$ and $R$ is nothing more than a description of combinations of columns of $C$ as defined by columns of $R$.
>>> A[:,[0,1]]
array([[ 1, 2],
[ 3, -2],
[ 2, 3]])
>>> A[:,[0,1]] @ np.array([[1,0,2],[0,1,1]])
array([[ 1, 2, 4],
[ 3, -2, 4],
[ 2, 3, 7]])
Notice that this allows us to combine columns in any order we wish. For instance, suppose instead we had $B = \begin{bmatrix} 1 & 4 & 2 \\ 3 & 4 & -2 \\ 2 & 7 & 3 \end{bmatrix}$. In this case, we can keep $C$ the same and change $R$ so we have \[B = \begin{bmatrix}1 & 2 \\ 3 & -2 \\ 2 & 3 \end{bmatrix} \begin{bmatrix} 1 & 2 & 0 \\ 0 & 1 & 1 \end{bmatrix} = CR.\]
>>> A[:,[0,1]] @ np.array([[1,2,0],[0,1,1]])
array([[ 1, 4, 2],
[ 3, 4, -2],
[ 2, 7, 3]])
In other words, we can think of matrix multiplication as computing the matrix-vector products for each column and sticking them together to form the desired matrix product.
Let $A$ and $B$ be matrices. If $B = \begin{bmatrix}\mathbf u & \mathbf v & \mathbf w\end{bmatrix}$ with column vectors $\mathbf u, \mathbf v, \mathbf w$, then \[AB = \begin{bmatrix} A\mathbf u & A \mathbf v & A \mathbf w\end{bmatrix}.\]
Let $A = \begin{bmatrix} 2 & 4 \\ -3 & 4 \\ 1 & -2 \end{bmatrix}$ and $B = \begin{bmatrix} 3 & -1 & 5 \\ 9 & 3 & -1\end{bmatrix}$ Then \begin{align*} AB &= \begin{bmatrix} A\begin{bmatrix} 3 \\ 9 \end{bmatrix} & A \begin{bmatrix} -1 \\ 3 \end{bmatrix} & A \begin{bmatrix} 5 \\ -1 \end{bmatrix} \end{bmatrix} \\ &= \begin{bmatrix} 3 \begin{bmatrix} 2 \\ -3 \\ 1 \end{bmatrix} + 9 \begin{bmatrix} 4 \\ 4 \\ -2 \end{bmatrix} & -1 \begin{bmatrix} 2 \\ -3 \\ 1 \end{bmatrix} + 3 \begin{bmatrix} 4 \\ 4 \\ -2 \end{bmatrix} & 5 \begin{bmatrix} 2 \\ -3 \\ 1 \end{bmatrix} + -1 \begin{bmatrix} 4 \\ 4 \\ -2 \end{bmatrix} \end{bmatrix} \\ &= \begin{bmatrix} 42 & 10 & 6 \\ 27 & 15 & -19 \\ -15 & -7 & 7 \end{bmatrix} \end{align*}
>>> A = np.array([[2, 4], [-3, 4], [1, -2]])
>>> B = np.array([[3, -1, 5], [9, 3, -1]])
>>> A @ B
array([[ 42, 10, 6],
[ 27, 15, -19],
[-15, -7, 7]])
>>> A @ B[:,0]
array([ 42, 27, -15])
>>> A @ B[:,1]
array([10, 15, -7])
>>> A @ B[:,2]
array([ 6, -19, 7])
Of course, this is the way to view matrix multiplication when viewed via columns. We could just as well adapt the row/dot product view of matrix multiplication: \[ AB = \begin{bmatrix} 3 \cdot 2 + 9 \cdot 4 & -1 \cdot 2 + 3 \cdot 4 & 5 \cdot 2 + -1 \cdot 4 \\ 3 \cdot -3 + 9 \cdot 4 & -1 \cdot -3 + 3 \cdot 4 & 5 \cdot -3 + -1 \cdot 4 \\ 3 \cdot 1 + 9 \cdot 2 & -1 \cdot 1 + 3 \cdot -3 & 5 \cdot 1 + -1 \cdot -2 \end{bmatrix} = \begin{bmatrix} 42 & 10 & 6 \\ 27 & 15 & -19 \\ -15 & -7 & 7 \end{bmatrix}. \]
>>> A[1] @ B[:,0]
27
>>> A[0] @ B[:,2]
6
It's important to note here that not every pair of matrices can be multiplied together. There's a very big restriction: $A$ must have the same number of columns as $B$ has rows. This makes sense: matrix multiplication is about linear combinations of columns of $A$, so we need to specify a value for each column.
This actually tells us another important thing about matrix multiplication: it's not commutative. In other words, $AB$ is not necessarily the same as $BA$, if such a product even exists at all.
An interesting question that arises from this definition is how many multiplications we need to perform in order to compute a matrix multiplication. That is, suppose that I have two matrices $A$ and $B$, where $A$ is an $m \times p$ matrix and $B$ is a $p \times n$ matrix. The resulting matrix $AB$ is then an $m \times n$ matrix.
To simplify things a bit, let's consider the case where we have $n \times n$ square matrices. Then it's clear that we need something like $n^3$ multiplication operations. Is this the best we can do?
One of the earliest surprises of computer science was showing that we can get away with far fewer multiplications! By slicing and dicing your matrices appropriately and making a few clever observations, we can construct our desired matrix with only $n^{2.373}$ or so multiplications. This was a result from 1970, due to Strassen, which followed a similar breakthrough about multiplying ordinary numbers. The question of whether we can get down to closer to $n^2$ has been open since the late 1980s. Progress on this question was stalled until the 2010s and we've seen a burst of activity around it since.