The most famous recent application of this idea is Google's PageRank algorithm, which was defined by Brin, Page, Motwani, and Winograd in 1998. At the time, the dominant paradigm of search was keyword-based. Search engines would try to retrieve results based on how well pages matched keywords. However, there was a problem—what separates, say, the CDC website from some guy's Geocities site (maybe the modern equivalent is some guy's Medium post)?
In other words, simply matching based on keywords is not good enough—we need a way to determine the importance or reputation of a website. This seems subjective, but it was understood to be a problem that needed solving—at the same time, there were "directories" that were keyword or topic-based lists of websites that were curated by humans.
PageRank is an algorithm that attempts to solve this "page ranking" problem (though the algorithm is really named for Larry Page). There are two pieces here to set up.
How are scores computed? The idea is based on the idea of citation counts: roughly speaking, a more important page is likely to receive more inbound links. But this assumes that every inbound link is equally important. In fact, if an inbound link comes from a highly reputable source, it should have a higher score. So an originating webpage's score contributes to the score of a page that it links to.
There is one possible pitfall here: that this score can be gamed. One immediate thing we can do is discard any self-links. Even then, one can imagine a scenario where someone tries to "trade favours" by running a large website that becomes reputable by promising links to other pages. To counter this, the amount that a page contributes to outgoing links is scaled by the total number of its outgoing links. That is, if page $i$ has score $x_i$ and has $n_i$ outgoing links, then each link provides $\frac{x_i}{n_i}$ to the receiving page. This leads us to the following setup.
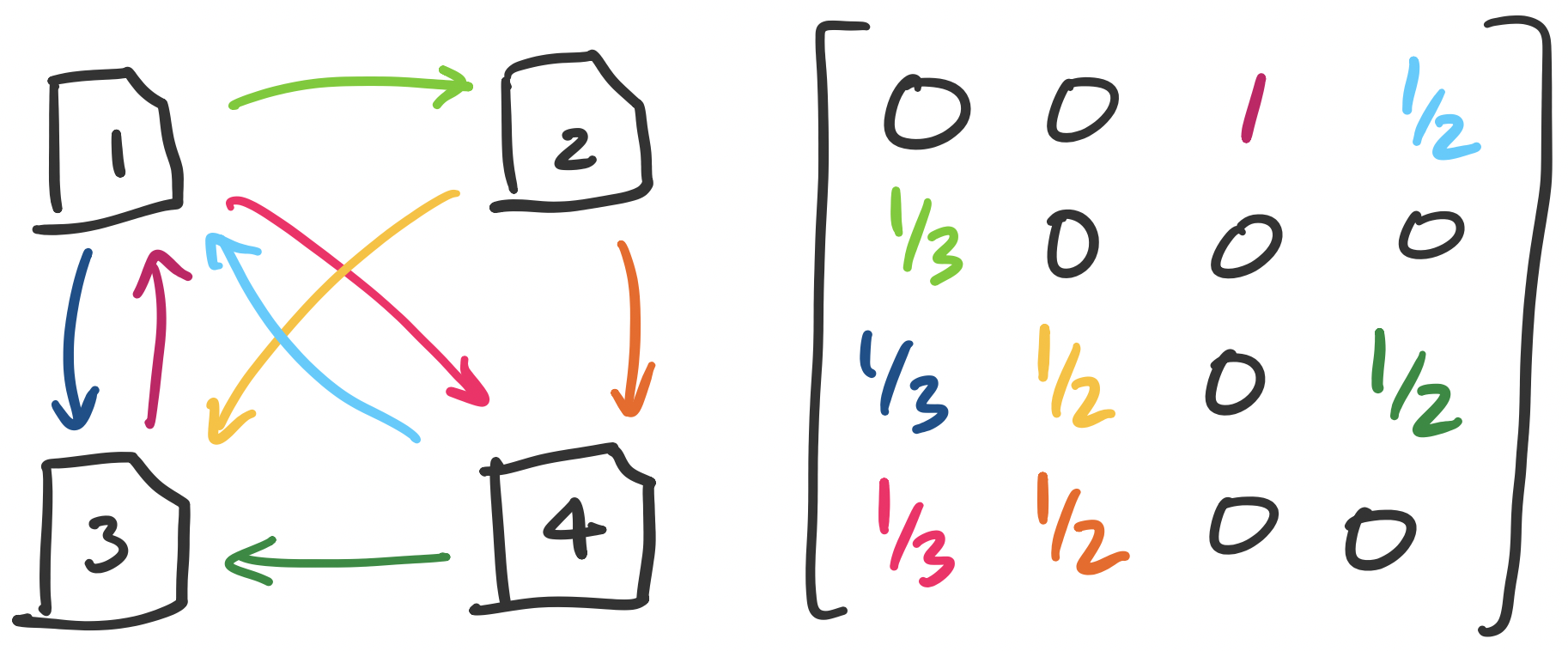
This seems to produce a bit of a chicken-and-egg scenario: in order to compute $x_1$, we need to know $x_3$ and $x_4$, but to compute both of those we would need to know $x_1$. However, what we have is really just a system of linear equations and we would like to solve for the $x_i$'s. Our example gives us the system \begin{align*} 1 x_3 + \frac 1 2 x_4 &= x_1 \\ \frac 1 3 x_1 &= x_2 \\ \frac 1 3 x_1 + \frac 1 2 x_2 +\frac 1 2 x_4 &= x_3 \\ \frac 1 3 x_1 + \frac 1 2 x_2 &= x_4 \end{align*} When viewed in matrix-vector form, we have the equation \[\begin{bmatrix} 0 & 0 & 1 & \frac 1 2 \\ \frac 1 3 & 0 & 0 & 0 \\ \frac 1 3 & \frac 1 2 & 0 & \frac 1 2 \\ \frac 1 3 & \frac 1 2 & 0 & 0 \end{bmatrix} \begin{bmatrix} x_1 \\ x_2 \\ x_3 \\ x_4 \end{bmatrix} = \begin{bmatrix} x_1 \\ x_2 \\ x_3 \\ x_4 \end{bmatrix}. \]
Disentangling this, we see that we have what amounts to an adjacency matrix weighted by the number of outgoing edges in each vertex. The equation then describes something intriguing: we would like our score vector to be an eigenvector for our adjacency matrix—specifically, one with eigenvalue 1.
The question we are then faced with is whether there exists a vector $\mathbf x^*$ such that $A \mathbf x^* = \mathbf x^*$—in other words, $A$ have 1 as an eigenvalue? One helpful observation we can make is that $A$ is really a column-stochastic matrix (i.e. Markov matrix). We know this because each entry contains $\frac 1 n$ for $n$ outgoing links. As it turns out, every column-stochastic matrix has an eigenvalue of 1.
Every stochastic matrix has 1 as an eigenvalue.
Let $A$ be an $n \times n$ stochastic matrix and let $\mathbf 1 = \begin{bmatrix} 1 \\ \vdots \\ 1 \end{bmatrix}$ be a vector of all 1s in $\mathbb R^n$. We have $A^T \mathbf 1 = \mathbf 1$, since all columns of $A$ add up to 1. This means that $\mathbf 1$ is an eigenvector for $A^T$ with eigenvalue 1. Since $A$ and $A^T$ have the same eigenvalues, this means that 1 is an eigenvalue for $A$.
Solving for $\lambda = 1$, we get $\mathbf x^* = \begin{bmatrix} 12 \\ 4 \\ 9 \\ 6 \end{bmatrix}$. Typically, we would normalize this so that the vector adds up to 1, but we notice from this that the most highly ranked page is 1, even though only two pages link to it, compared to page 3, which has three incoming links.
This provides another interesting interpretation for the link matrix: it's really a Markov chain where a web "surfer" (as they were called in the 90s) decides to follow outgoing links on each page with uniform probability.
There are two remaining technical challenges that we can discuss briefly: one computational and one algebraic.
The computational challenge is in computing the eigenvector for this matrix. This gets at a dirty secret at the heart of many linear algebra classes: the methods we use in these classes are almost never used in practice. This is for two reasons:
This is to reiterate something important to keep in mind: this class and the methods we use are intended to develop your understanding of the structures rather than as something to use directly in computation.
In this case, we use an algorithm called the power method, which amounts to iteratively computing $\mathbf x$ and normalizing it until it converges to $\mathbf x^*$. Many numerical linear algebra algorithms work the same way, by iterating until convergence.
The final algebraic challenge relates to the question of eigenspaces. Namely: how do we know that there is one unique score vector $\mathbf x^*$? We can of course take care of the obvious issue by considering only the normalized version of this vector. But the remaining question is how we know that the eigenspace for eigenvalue 1 always has dimension 1.
In fact, we do not have this guarantee for our definition of $A$. We require that our web graph is strongly connected—that every vertex is reachable from every other vertex. This is known not to be true for the real web. The requirement that our graph is strongly connected is not something we'll prove, but let's see why it intuitively makes sense.
Consider the scenario where our web has two distinct components. We can view the adjacency matrix as $\begin{bmatrix} W_1 & 0 \\ 0 & W_2 \end{bmatrix}$, where $W_1$ and $W_2$ are our two components that are not reachable from each other. From this, we can see at least two possible linearly independent eigenvectors: the vectors $\begin{bmatrix} \mathbf x_1^* \\ \mathbf 0 \end{bmatrix}$ and $\begin{bmatrix} \mathbf 0 \\ \mathbf x_2^* \end{bmatrix}$. Since these two vectors are linearly independent, any linear combination of them is also an eigenvector. This is a problem if we want a definitive set of scores.
How can we fix this? We return to the interpretation of the link matrix as a Markov matrix that describes the behaviour of a random web surfer. As you know, people do not just follow links from page to page when they are on the web—sometimes they go to totally different websites directly. So why not incorporate that probability into our link matrix?
Choose some probability $p$ with which someone will go to a completely random page. The original paper sets $p = 0.15$. Then construct an $n \times n$ matrix $S$ with all entries $\frac 1 n$: this represents a uniform probability that any page is selected. Then we put our matrices together into the final link matrix $M$: \[M = (1-p)A + p S.\] This says that our final matrix represents a surfer who 85% of the time browses the web by following links on the page and 15% of the time will go to a completely different page. This matrix ix clearly strongly connected (because of the $S$ component). It's also not too hard to work out that this matrix is column-stochastic. So this matrix will have eigenvalue 1 with eigenspace of dimension 1.