What we've accomplished so far works for projections onto subspaces. That is, if all we want to do was take a subspace and we know its basis, we can transform that basis into an orthogonal basis and then go to town with the result. However, things get trickier when we want to solve or approximate a specific linear equation $A \mathbf x = \mathbf b$—we can't just transform $A$ into $Q$ and call it a day.
We have to remember that, as with any transformation to our matrix $A$ that we make, whether it is $A = CR$ or $A = LU$, transforming $A$ to $Q$ means that there will be another matrix involved, with information that we "lose" when going from $A$ to $Q$. This matrix is $R$ (confusingly, not the same $R$ that we've been using).
The QR factorization of an $m \times n$ matrix $A$ is given by $A = QR$, where $Q$ is an orthogonal matrix and $R$ is an upper triangular matrix, defined by \[A = \begin{bmatrix} \\ \mathbf a_1 & \mathbf a_2 & \cdots & \mathbf a_n \\ \\ \end{bmatrix} = \begin{bmatrix} \\ \mathbf q_1 & \mathbf q_2 & \cdots & \mathbf q_n \\ \\ \end{bmatrix} \begin{bmatrix} \mathbf q_1^T \mathbf a_1 & \mathbf q_1^T \mathbf a_2 & \mathbf q_1^T \mathbf a_3 & \cdots & \mathbf q_n^T \mathbf a_n \\ 0 & \mathbf q_2^T \mathbf a_2 & \mathbf q_2^T \mathbf a_3 & \cdots & \mathbf q_2^T \mathbf a_n \\ 0 & 0 & \mathbf q_3^T \mathbf a_3 & \cdots & \mathbf q_3^T \mathbf a_n \\ \vdots & \vdots & & \ddots & \vdots \\ 0 & 0 & \cdots & 0 & \mathbf q_n^T \mathbf a_n \end{bmatrix} = QR.\]
It is clear that $Q$ contains the orthonormal basis of the column space spanned by columns of $A$. But what about $R$? If we examine closely, we see that each entry of the matrix $R$ is defined as follows, \[r_{ij} = \begin{cases} \mathbf q_i^T \mathbf a_j & \text{if $i \leq j$,} \\ 0 & \text{otherwise.} \end{cases}\]
The result is that $\mathbf a_i$ can be written as a linear combination of $\mathbf q_i$'s. The matrix $R$ tells us exactly how: \[\mathbf a_i = \mathbf q_1 (\mathbf q_1^T \mathbf a_i) + \cdots + \mathbf q_i (\mathbf q_i^T \mathbf a_i).\]
What does this mean? Recall that in order to get our orthogonal basis, we had to break up every one of our basis vectors into orthogonal pieces. When computing $\mathbf q_i$, we first acquired $\mathbf b_i$, the vector orthogonal to the projection of $\mathbf a_i$ onto $\mathbf q_1, \dots, \mathbf q_{i-1}$. That is, \[\mathbf b_i = \mathbf a_i - (\mathbf q_1 \mathbf q_1^T \mathbf a_i + \cdots \mathbf q_{i-1} \mathbf q_{i-1}^T \mathbf a_i).\] Substituting this into our equation, we have \[\mathbf b_i = \mathbf q_i (\mathbf q_i^T \mathbf a_i).\] This tells us that $\mathbf b_i$, the $i$th basis vector that we computed based on $\mathbf a_i$ and its projection onto the other vectors, is really the projection of $\mathbf a_i$ onto $\mathbf q_i$. This makes sense, because $\mathbf q_i$ is nothing but $\mathbf b_i$ scaled down to unit length.
This is a nice decomposition for a few reasons:
Let's return to $A = \begin{bmatrix}-1 & -1 & 0\\-1 & 0 & 1\\0 & -2 & -1\end{bmatrix}$. We got $Q = \begin{bmatrix}- \frac{\sqrt{2}}{2} & - \frac{\sqrt{2}}{6} & - \frac{2}{3}\\- \frac{\sqrt{2}}{2} & \frac{\sqrt{2}}{6} & \frac{2}{3}\\0 & - \frac{2 \sqrt{2}}{3} & \frac{1}{3}\end{bmatrix}$ from the Gram–Schmidt process. But what is the associated $R$? We simply go through each entry and take the appropriate dot products.
This gives us $R = \begin{bmatrix}\sqrt{2} & \frac{\sqrt{2}}{2} & - \frac{\sqrt{2}}{2}\\0 & \frac{3 \sqrt{2}}{2} & \frac{5 \sqrt{2}}{6}\\0 & 0 & \frac{1}{3}\end{bmatrix}$.
We saw that using $Q$ improved our least squares computation, but we don't always have a perfectly orthonormal basis $Q$. We do always have $A = QR$, though. The question is whether $A = QR$ improves the situation at all. First, let's consider $A^TA$: \[A^TA = (QR)^T QR = R^TQ^TQR = R^TR.\] If we substitute this into our least squares equation, we get \begin{align*} R^TR\mathbf{\hat x} &= R^TQ^T\mathbf b \\ R\mathbf{\hat x} &= Q^T\mathbf b \end{align*} At this point, it looks like we haven't gained anything—we still need to move $R$ to the other side, so we compute $R^{-1}$. However, that omits a very crucial property of $R$. First, remember that we can compute $Q^T \mathbf b = \mathbf d$, so let's rewrite our equation: \[R \mathbf{\hat x} = \mathbf d.\] We are back to solving a linear equation. But recall that $R$ is upper triangular! This means that we can just use substitution to solve this equation and avoid the expensive computation for the inverse.
We'll now step back into the world of $n \times n$ matrices to discuss eigenvectors. As we mentioned before, it's unlikely that we'll encounter data matrices that are square. However, they still play an important role in representing certain kinds of data (for example, graphs) and are particularly important from the point of view as transformations.
First, let's look at transformations on their own.
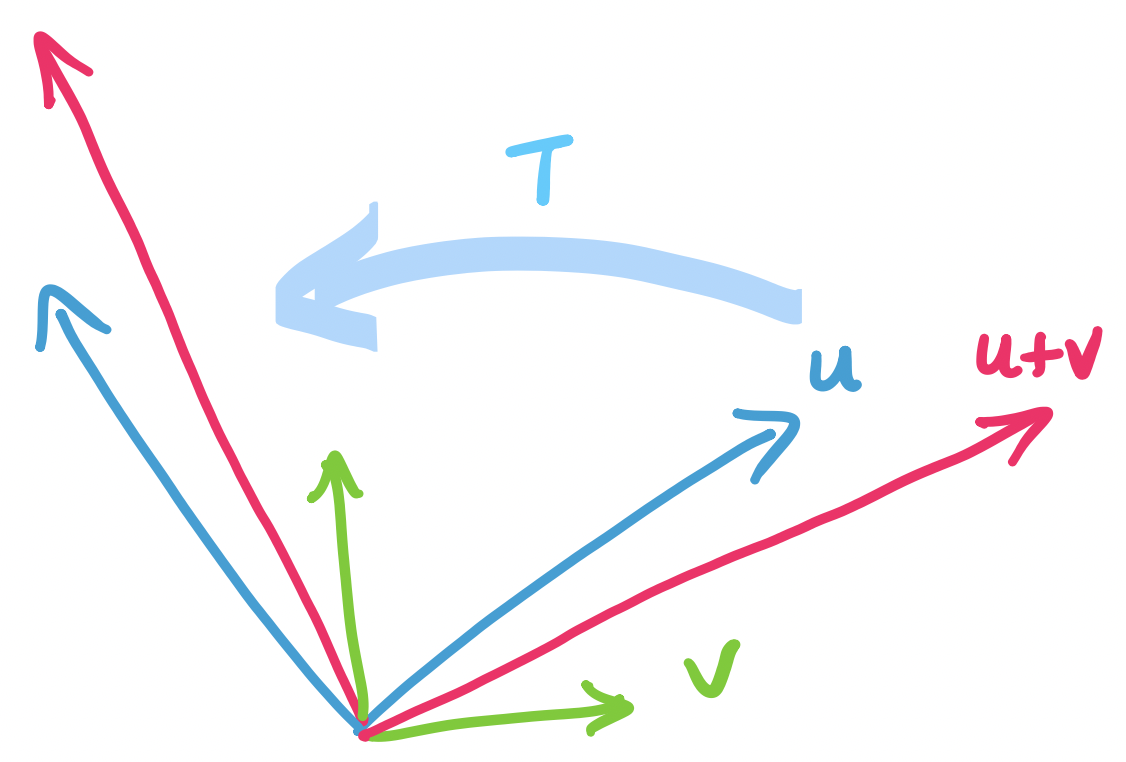
A linear transformation $T : \mathbf U \to \mathbf V$ is a function that takes a vector in vector space $\mathbf U$ and produces a vector in vector space $\mathbf V$ such that for all vectors $\mathbf u$ and $\mathbf v$,
Notice that this definition doesn't involve matrices yet—though, obviously, like everything else in the course, it will. But the plainest reading of this definition is that it is a definition about functions, not matrices.
Here's an example that doesn't involve vectors at all: expectation of random variables. Recall that the expectation of a random variable $X$ can be thought of as the average of $X$ weighted by probabilities. It turns out that there is a theorem called "linearity of expectation" which says that $E(c_1X_1 + c_2 X_2) = c_1 E(X_1) + c_2 E(X_2)$.
Let $T$ be a transformation that rotates a vector clockwise by $\theta$. We can test the two properties of linear transformations: If we add and scale the input then rotate it, do we end up with the same vector as if we rotated the inputs, then combined them? The answer turns out to be yes:
One of the consequences (conveniences) of the definition for linear transformations is that if we know that $\mathbf u = a_1 \mathbf v_1 + \cdots + a_n \mathbf v_n$, then it must be the case that $T(\mathbf u) = a_1 T(\mathbf v_1) + \cdots + a_n T(\mathbf v_n)$. This is important, because what it says is that in order to compute a transformation, all we really need to know is how the transformation affects the basis.
We want to come up with a matrix that describes our rotation in $\mathbb R^2$ by some angle $\theta$. We know from geometry that rotating $\begin{bmatrix} 1 \\ 0 \end{bmatrix}$ by $\theta$ results in a vector $\begin{bmatrix} \cos \theta \\ \sin \theta \end{bmatrix}$ and rotating $\begin{bmatrix} 0 \\ 1 \end{bmatrix}$ by $\theta$ results in a vector $\begin{bmatrix} -\sin \theta \\ \cos \theta \end{bmatrix}$.
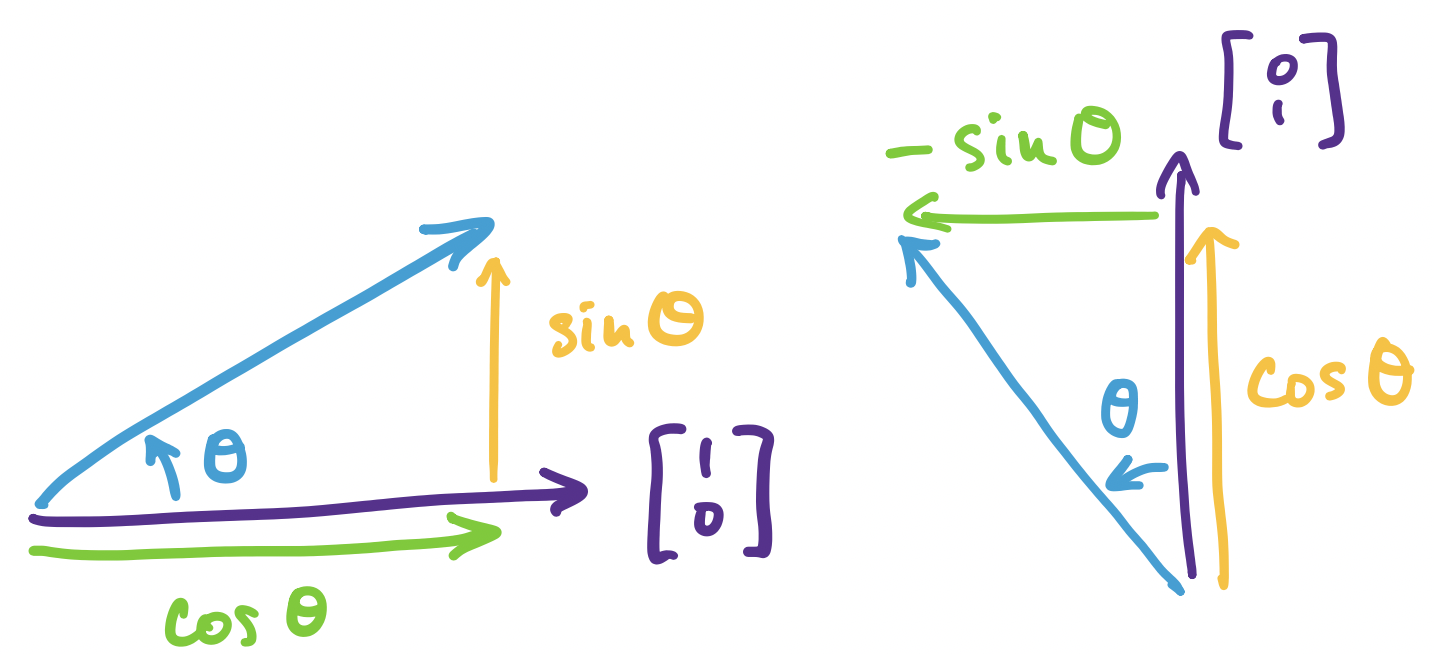
What if we have an arbitrary vector $\mathbf v = \begin{bmatrix}v_1 \\ v_2 \end{bmatrix}$? We know we can write this vector in terms of the standard basis as \(\mathbf v = v_1 \begin{bmatrix} 1 \\ 0 \end{bmatrix} + v_2 \begin{bmatrix} 0 \\ 1 \end{bmatrix}\). Then our rules about linear transformations say that the rotation of $\mathbf v$ can be described as \[v_1 \begin{bmatrix} \cos \theta \\ \sin \theta \end{bmatrix} + v_2 \begin{bmatrix} -\sin \theta \\ \cos \theta \end{bmatrix} = \begin{bmatrix} \cos \theta & - \sin \theta \\ \sin \theta & \cos \theta \end{bmatrix} \begin{bmatrix} v_1 \\ v_2 \end{bmatrix}.\]
So we've recovered a matrix that describes our transformation. We can play the same trick to arrive at the fact that every linear transformation can be described via a matrix. And since every matrix is a linear transformation, by virtue of matrix multiplication obeying the rules of linear transformations, we can say that the two things are basically the same thing.
Notice that every matrix ends up defining some linear transformation, even those that are not square. These ones take a vector from $\mathbb R^m$ as input and produce a vector in $\mathbb R^n$. But first, we'll focus on $n \times n$ matrices and then see how to generalize to $m \times n$ matrices.
In the case of a square matrix, we are taking a vector in $\mathbb R^n$ and mapping it to some other vector in $\mathbb R^n$. This amounts to moving it around, squishing and stretching it into some other vector in the same space. Intuitively, this tells us that there must be some vectors that stay roughly the same under such transformations—these vectors are the eigenvectors of the matrix.
What do eigenvectors tell us? Consider some data set that looks like the following.
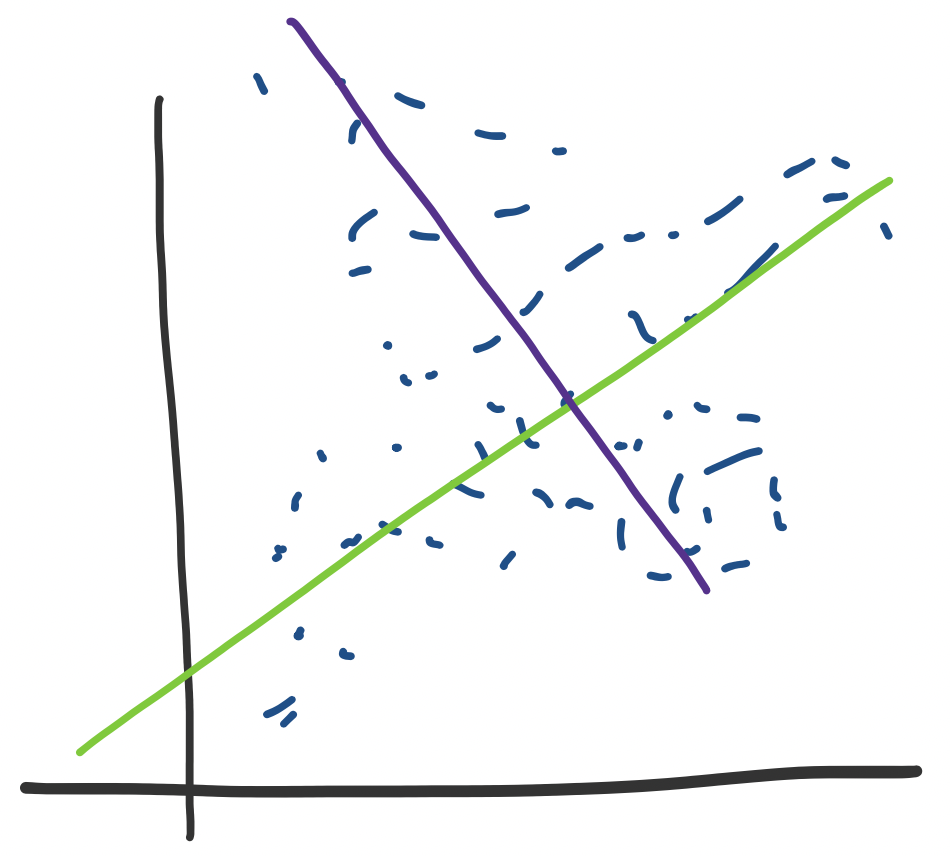
We see this kind of thing and think that we would really like to draw a line of best fit through it. Luckily, we've seen how to do exactly that. But this assumes that we've organized our data enough to know that we want to compute a regression on a specific variable. What happens if we don't know this? Perhaps we have several dimensions and we need to find one such axis or direction.
If we think of our data from the point of view of transformation, we can see that what we're trying to do is predict where to map data based on our data set—in the language of machine learning, this transformation is really the function that we're trying to "learn". One way to think about this visually is that it means that there will be some "directions" in which we send certain vectors that are more likely or that are a heavier influence. These are the directions or vectors that we are trying to find.
Intuitively, we expect that these are associated with vectors that are "stable" or don't change direction when we apply our transformation. These are exactly the eigenvectors of the matrix.
So instead of simply decomposing a matrix to find its independent pieces, we are about to take one step further and identify the importance of the pieces.