
Continuing from our DFA construction for concatenation from last class,
From this construction, our state set has $m2^n$ states. However, we can make the observation that whenever we're in a final state of $A_1$, the initial state of $A_2$ must be in our set of current states of $A_2$. This means that any states in $F_1 \times 2^{Q_2 \setminus \{q_{0,2}\}}$ will never be reached and we can remove these from our machine. If $A_1$ has $k$ final states, then this is exactly $k 2^{n-1}$ states. This means we have as many as $m2^n - k2^{n-1}$ states. This number grows when $A_1$ has fewer final states, so it's maximized when $A_1$ has only a single final state, giving us our bound of $m2^n - 2^{n-1}$. $\tag*{$\Box$}$
So we've shown how several operations preserve regularity by showing how to construct the equivalent finite automata.
Now, we'll be revisiting the idea of languages as sets and define another way to describe a language. Recall that languages are sets and that we can perform all the usual set operations on these sets to describe new languages. We also extended some string operations to languages. We will now define a specific set of these operations to be regular operations.
Definition 7.1. Let $\Sigma$ be an alphabet and let $L,M \subseteq \Sigma^*$ be languages. The following operations are the regular operations:
So what's so special about these particular operations? These operations define what we call the class of regular languages
Definition 7.2. A language $L$ is regular if it satisfies the following:
Let $L_1$ and $L_2$ be regular languages.
This gives us a definition for the regular languages in terms of language operations and not finite automata, which is a related but slightly disconnected notion. But why are these called regular languages? It's mostly because Kleene called them this when he first defined them and no one bothered to come up with a better name.
That's not actually entirely true, because there is a better name that's derived from the monoid perspective of formal languages. So recall that we can view our alphabet together with concatenation as a monoid and the free monoid on our alphabet is just the set of strings over that alphabet. If we forget about focusing on free monoids and just consider arbitrary monoids, then the rational subsets of a monoid are those subsets that are closed under the rational operations: $\cup$, $\cdot$, and $*$ (here, $\cdot$ and $*$ refer to the binary operation for the monoid, not necessarily concatenation).
From this, it makes a lot of sense to call regular languages rational languages instead, and there are many who do, particularly algebraic automata theorists and French mathematicians. But the prevailing terminology, especially among computer scientists, is going to be regular languages. There will be other neat things that we can glean from the algebraic perspective.
Based on this definition, we can show that some very simple languages are regular.
Theorem 7.3. If $|L| = 1$, then $L$ is regular.
Proof. Let $L = \{w\}$. We will prove this by induction on $|w|$. If $|w| = 0$, we have $L = \{\varepsilon\}$, which is regular by definition.
Now, we consider $w = xa$ for a string $x \in \Sigma^*$ and $a \in \Sigma$ and assume that $\{x\}$ is regular. Let $L_1 = \{x\}$ and $L_2 = \{a\}$. Then $L_1$ is regular by our inductive hypothesis and $L_2$ is regular by definition. Since they are both regular, we can concatenate them to get $L_1 L_2 = \{w\}$ which is regular by definition. $$\tag*{$\Box$}$$
Theorem 7.4. If $|L|$ is finite, then $L$ is regular.
Proof. We will prove this by induction on $|L|$. If $|L| = 0$, we have $L = \emptyset$, which is regular by definition.
Now, assume that if $|L'| = k$ for some $k \in \mathbb N$, then $L'$ is regular. Consider $|L| = k+1$. Since $L$ is finite, we can write $L = \{w_1, w_2, \dots, w_{k+1} \}$. Then $L = \{w_1, w_2, \dots, w_k\} \cup \{w_{k+1}\}$. But $\{w_1, w_2, \dots, w_k\}$ has size $k$ and therefore, by our inductive hypothesis, it is regular, while $\{w_k\}$ is regular by the previous theorem. Since $\cup$ is a regular operation, we can conclude that $L$ is regular. $$\tag*{$\Box$}$$
Up to now, we've only considered finite automata as a way to describe a language. However, using finite automata as a description has its limitations, particularly for humans. While all of the finite automata we've seen so far are reasonably understandable, they are relatively small. Finite automata as used in practical applications can contain hundreds or thousands or more states. Luckily, our definition of regular languages will give us a more succinct and friendlier way to describe a regular language, via regular expressions.
Definition 7.5. We say $R$ is a regular expression over an alphabet $\Sigma$, and $L(R)$ is the language of the regular expression $R$, if $R$ satisfies one of the following conditions:
and for regular expressions $R_1$ and $R_2$,
Furthermore, we establish an order of operations, like for typical arithmetic expressions:
and as usual, we can explicitly define an order for a particular expression by using parentheses.
We can see that this definition mirrors that of the definition for regular languages and we can pretty easily conclude that the regular expressions describe exactly the class of regular languages. It's also important to note that we should separate the notion of a regular expression and the language of the regular expression. Specifically, a regular expression $R$ is just a string, while $L(R)$ is the set of words described by the regular expression $R$.
The term regular expression may sounds familiar to many of you, particularly if you've ever needed to do a bunch of pattern matching. And your guess is correct: these are (mostly) the same thing. For the most part, the regular expressions as used in Unix and various programming languages are based on our theoretically defined regular expressions. This leads to a few points of interest.
The first is that this implies a non-theoretical application for all of the stuff that we've been doing so far: pattern matching. If you want to search for some text, or more generally a pattern, then regular expressions are your tool of choice. But, and I hinted at this earlier, regular expressions are for us to read, while the computer turns it into a finite automaton and uses that for text processing.
Now, that may have been obvious because the name gave it away. However, there's a second classical application of regular languages that is similar: lexical analysis. Lexical analysis is the phase of the compiler that is responsible for breaking up strings of symbols into a sequence of tokens (which is why this is also sometimes called tokenization).
Tokens are discrete units that have some meaning. For instance, the string
if ( x > 2 ) {could be tokenized as
[(KEYWORD, "if"), (SEPARATOR, "("), (IDENTIFIER, "x"), (OPERATOR, ">"), (LITERAL, "2"), (SEPARATOR, ")"), (SEPARATOR, "{")]Now, what's important to keep in mind is that tokenization only gives meaning to the parts of the string, but it doesn't check whether the sequence of tokens actually makes "grammatical" sense. This is a sign of things to come.
Of course, there's an obvious analogy to natural language. In computational linguistics, regular languages provide a simple first approach to tokenizing natural language sentences, by identifying discrete words and possibly the kinds of words (nouns, verbs, etc.) they are. Again, such processing only attempts to provide meanings to chunks of strings, but doesn't enforce any particular rules about how these chunks should be arranged.
Example 7.6. Here are some examples of some regular expressions and the languages they describe.
One of the first things about finite automata that I mentioned in passing is that finite automata recognize the class of regular languages. Now that we have another definition for regular languages, we should show that finite automata really can accept any regular language. In fact, this will give us a way to construct a regular expression, given a finite automaton.
Theorem 7.7. Let $L \subseteq \Sigma^*$ be a regular language. Then there exists a DFA $M$ with $L(M) = L$.
Proof. We will show this by structural induction. Since we've already shown that they're equivalent to DFAs, we will actually just construct $\varepsilon$-NFAs for convenience.
First, for our base case, we can construct the following $\varepsilon$-NFAs for each of conditions (1–3):

Since these are pretty simple, we won't formally prove that they're correct, but you can try on your own if you wish.
Now, we will show that we can construct an $\varepsilon$-NFA for each of conditions (4–6). For our inductive hypothesis, we let $L_A$ and $L_B$ be regular languages and assume that they can be accepted by DFAs $A$ and $B$, respectively.
Luckily, we've done a lot of the work up to this point.
First, we'll consider $L_A \cup L_B$. We've already seen how to construct a DFA for the union of the two languages by modifying the product construction. Here, we'll take the opportunity to describe an $\varepsilon$-NFA that does the same thing. Informally, we can make an NFA that looks like this:
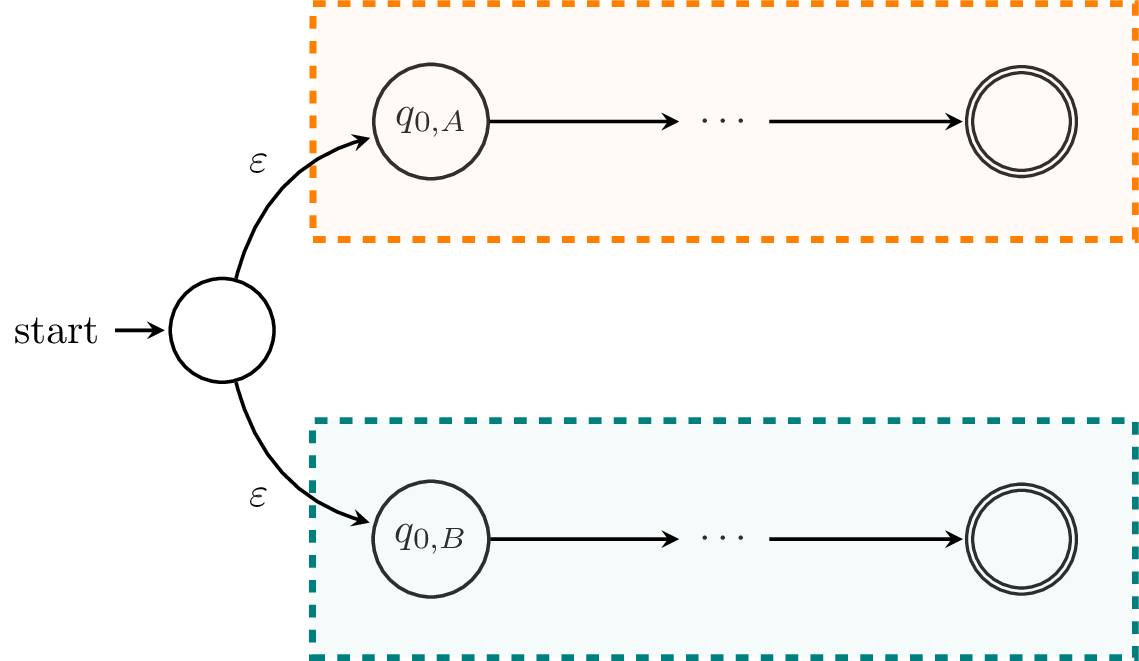
Basically, we take our idea about running two finite automata in parallel literally. We start in the initial states of each machine and run them. If one of them accepts, then we accept.
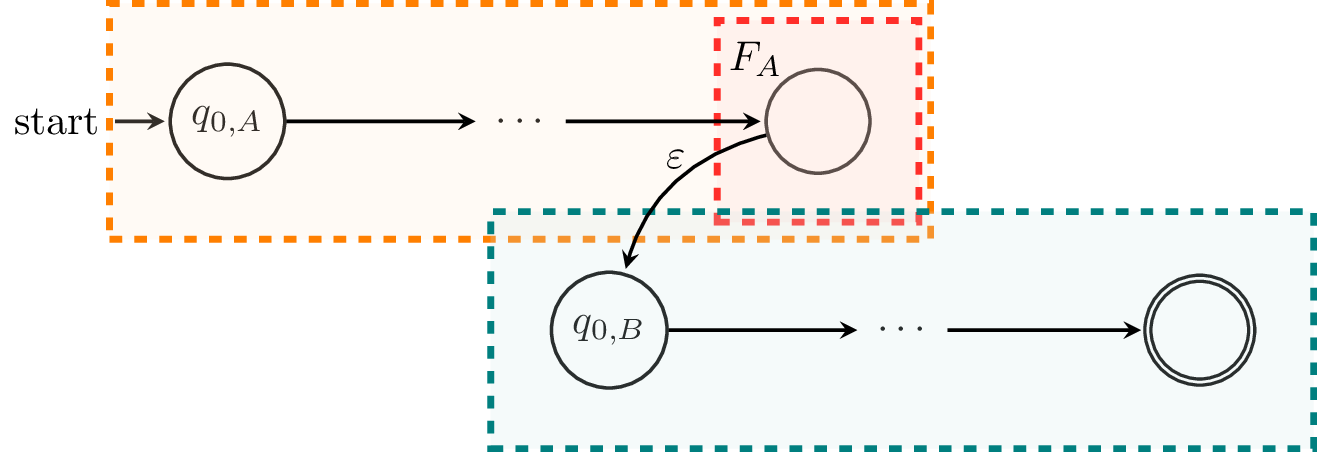
Next, we'll consider $L_A L_B$. This is the construction that we used in Theorem 6.4.
Finally, we consider $L_A^*$. For this, let's break out and prove it as it's own theorem.
Theorem 7.8. The class of regular languages is closed under Kleene star.
Proof. Let $A = (Q_A,\Sigma,\delta,q_{0,A},F_A)$ be a DFA. We can construct an $\varepsilon$-NFA that looks like this:
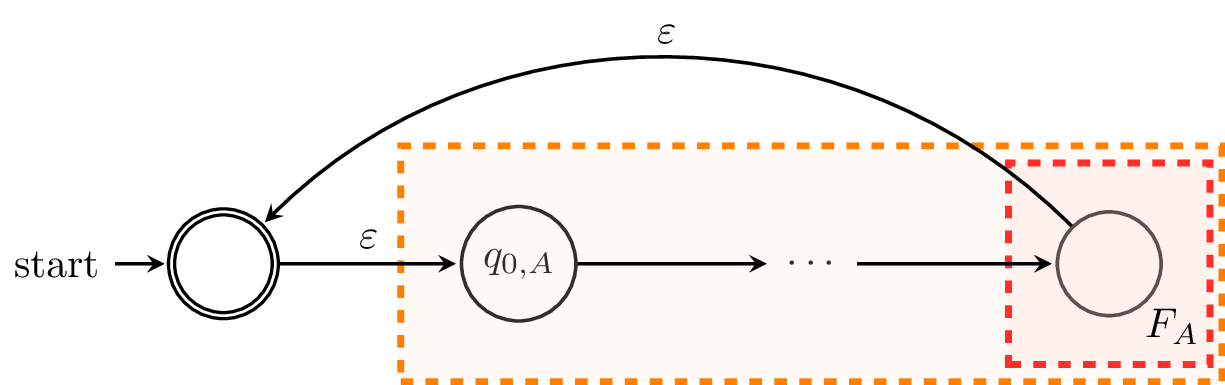
We define $A'$ by $A' = (Q_A \cup \{q_0',\}, \Sigma, \delta', \{q_0'\}, \{q_0'\})$, where the transition function $\delta' : Q_A \times (\Sigma \cup \{\varepsilon\}) \to 2^{Q_A \cup \{q_0'\}}$ is defined by
We modify $A$ to get $A'$ as follows. First, we need to create a new initial state and make it an initial state, in case $\varepsilon \not \in L_A$. Secondly, for each state in $F_A$, instead of adding it to the set of final states in $A'$, we add $\varepsilon$-transitions to the sole final state of $A'$, $q_0'$. While this is mostly cosmetic, it makes the construction clearer. Each word that is accepted by $A'$ must begin at $q_0'$ and must end at $q_0'$, making zero or more traversals through $A$, and each traversal of $A$ must be a word accepted by $A$. Hence, each word accepted by $A'$ is a concatenation of multiple words accepted by $A$ and thus, a word that belongs to $L_A^*$. $\tag*{$\Box$}$
Thus, we have shown that we can construct $\varepsilon$-NFAs for $L_A \cup L_B$, $L_A L_B$, and $L_A^*$ and therefore, we can construct a DFA that accepts any given regular language. $$\tag*{$\Box$}$$
This specific construction is due to Ken Thompson in 1968 and is most commonly called the Thompson construction. Thompson, was one of the early figures working on Unix and was, among other things, responsible for the inclusion of regular expressions in a lot of early Unix software like ed, making regexes ubiquitous among programmers. More recent work of his you may be familiar with include UTF-8 and the Go programming language.