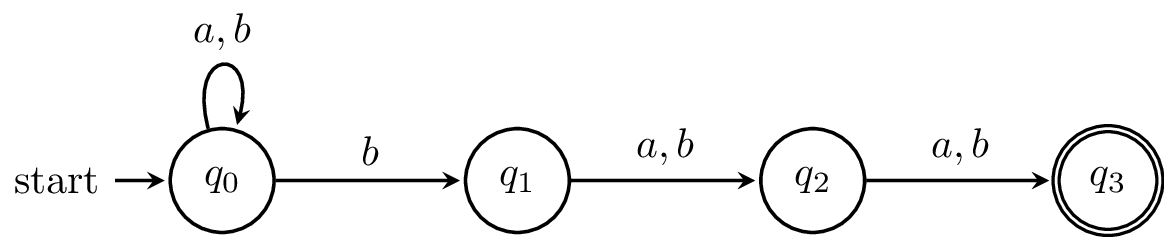
Here is our definition from last class.
Definition 4.1. A nondeterministic finite automaton (NFA) is a 5-tuple $A = (Q,\Sigma,\delta,I,F)$, where
This looks basically the same as the DFA, except for one important difference: the transition function $\delta$ is now a function from a state and a symbol to a set of states. This explains why we don't require that $\delta$ is defined explicitly for all states and symbols. Since the image of $\delta$ is sets of $Q$, we implicitly define "missing" transitions as going to the empty set $\emptyset$.
This also means that we will need to formally redefine acceptance of a word with nondeterminism. Again, we will extend our transition function to a function $\hat \delta: Q \times \Sigma^* \to 2^Q$. We define $\hat \delta(q,\varepsilon) = \{q\}$ and for $w = xa$ with $x \in \Sigma^*$ and $a \in \Sigma$, we have $$ \hat \delta(q,xa) = \bigcup_{p \in \hat \delta(q,x)} \delta(p,a).$$
However, just like how we eventually give up and abuse notation by using $\delta$ for $\hat \delta$, we also do this for subsets of state $P \subseteq Q$ and often write $$\delta(P,a) = \bigcup_{q \in P} \delta(q,a)$$ when the context is clear.
Let's take a moment to see how this definition fits with our intution about how nondeterminism behaves. It is easy to see that by taking the union of these sets, we really do get all possible transitions. However, note that this definition also handles transitions that are missing: if $\delta(p,a) = \emptyset$, then for any set $S$, we have $S \cup \emptyset = S$, and so $\hat \delta$ remains well-defined.
Now, we can define acceptance under the nondeterministic model.
Definition 5.1. We say that an NFA $A$ accepts a word $w$ if $\hat \delta(i,w) \cap F \neq \emptyset$ for some initial state $i \in I$. Then the language of an NFA $A = (Q,\Sigma,\delta,I,F)$ is defined by $$ L(A) = \left\{w \in \Sigma^* \mid \hat \delta(I,w) \cap F \neq \emptyset \right\}.$$
So now, the obvious question to ask is: does nondeterminism really give us more power? That is, can NFAs recognize languages that DFAs can't? It turns out the answer is no.
But how? We'll show that given any NFA $N$, we can construct a DFA $M$ that accepts the same language. The key observation is in examining what exactly is happening with our nondeterministic transition function. Remember that for each state and symbol, the transition function gives a set of states rather than a single state as a deterministic finite automaton.
So how many sets are there? If there are $n$ states, then there are $2^n$ possible subsets of $Q$. This is a large number which we've been trained as computer scientists to be alarmed at, but the important thing is that it is finite. This gives us a way to "simulate" the nondeterminism of an NFA using a DFA: just make each subset of $Q$ its own state!
Example 5.2. Let's try this with the example from last class. Here's the NFA again.
And here is the transition table with all the subsets.
| $a$ | $b$ | |
|---|---|---|
| $\emptyset$ | $\emptyset$ | $\emptyset$ |
| $\{q_0\}$ | $\{q_0\}$ | $\{q_0,q_1\}$ |
| $\{q_1\}$ | $\{q_2\}$ | $\{q_2\}$ |
| $\{q_2\}$ | $\{q_3\}$ | $\{q_3\}$ |
| $\{q_3\}$ | $\emptyset$ | $\emptyset$ |
| $\{q_0,q_1\}$ | $\{q_0,q_2\}$ | $\{q_0,q_1,q_2\}$ |
| $\{q_0,q_2\}$ | $\{q_0,q_3\}$ | $\{q_0,q_1,q_3\}$ |
| $\{q_0,q_3\}$ | $\{q_0\}$ | $\{q_0,q_1\}$ |
| $\{q_1,q_2\}$ | $\{q_2,q_3\}$ | $\{q_2,q_3\}$ |
| $\{q_1,q_3\}$ | $\{q_2\}$ | $\{q_2\}$ |
| $\{q_2,q_3\}$ | $\{q_3\}$ | $\{q_3\}$ |
| $\{q_0,q_1,q_2\}$ | $\{q_0,q_2,q_3\}$ | $\{q_0,q_1,q_2,q_3\}$ |
| $\{q_0,q_1,q_3\}$ | $\{q_0,q_2\}$ | $\{q_0,q_1,q_2\}$ |
| $\{q_0,q_2,q_3\}$ | $\{q_0,q_3\}$ | $\{q_0,q_1,q_3\}$ |
| $\{q_1,q_2,q_3\}$ | $\{q_2,q_3\}$ | $\{q_2,q_3\}$ |
| $\{q_0,q_1,q_2,q_3\}$ | $\{q_0,q_2,q_3\}$ | $\{q_0,q_1,q_2,q_3\}$ |
Note that all the subsets in red cannot be reached from the initial state $\{q_0\}$. Now, here is the state diagram for the DFA.
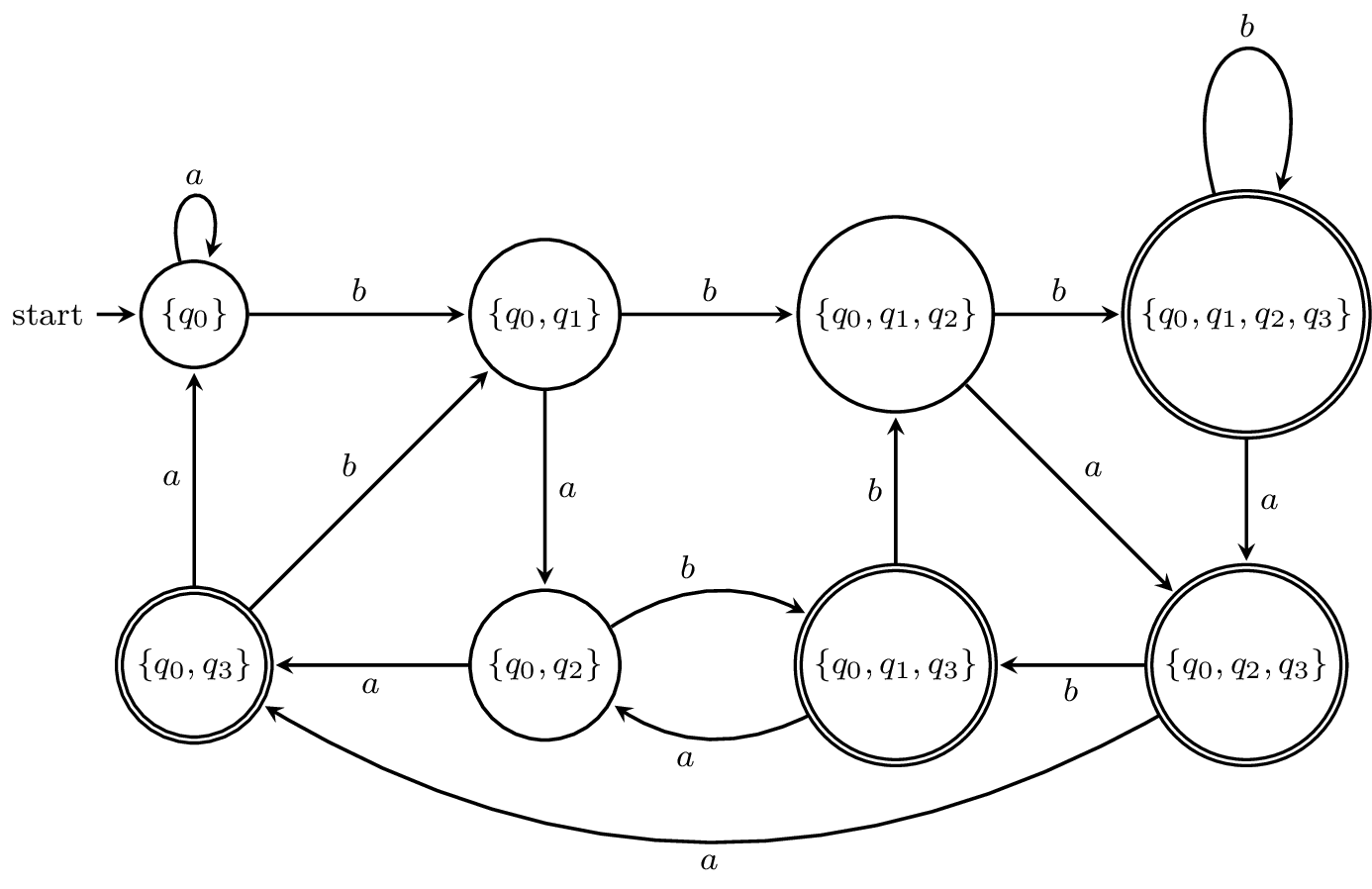
I've omitted all the subsets that can't be reached, but this is still a large DFA relative to the size of the NFA. In fact, one can show that the language $\{a,b\}^* b \{a,b\}^{n-1}$ can be recognized by an NFA with $n+1$ states but requires a DFA with $2^n$ states.
This construction is called the subset construction and was due to Rabin and Scott in 1959. An interesting question that one can consider is when the worst case of $2^n$ states comes up. Similar questions about the worst-case growth in the number of states of a DFA or NFA can be asked for other transformations or language operations in a line of research in automata theory called state complexity.
Now, let's define the subset construction formally.
Definition 5.3. Let $N = (Q,\Sigma,\delta,I,F)$ be an NFA. We will construct a DFA $\mathcal D(N) = (Q',\Sigma,\delta',q_0',F')$ such that $L(\mathcal D(N)) = L(N)$. We will define each component of $\mathcal D(N)$:
Now, we need to show that $\mathcal D(N)$ and $N$ recognize exactly the same language.
Theorem 5.4. Let $N$ be an NFA. Then $L(N) = L(\mathcal D(N))$.
Proof. We want to show that $w \in L(N)$ if and only if $w \in L(\mathcal D(N))$. This means that by definition, $\hat \delta(I,w) \cap F \neq \emptyset$ if and only if $\hat \delta'(I,w) \cap F \neq \emptyset$. So, we will show that $\hat \delta(q,w) = \hat \delta'(\{q\},w)$. We will show this by induction on $|w|$.
First, we have $w = \varepsilon$. Then $\hat \delta(q,\varepsilon) = \{q\} = \hat \delta'(\{q\},\varepsilon)$.
Now, suppose for some string $u \in \Sigma^*$, we have $\hat \delta(q,u) = \hat \delta'(\{q\},u)$. Let $w = ua$ with $a \in \Sigma$. Then we have \begin{align*} \hat \delta'(\{q\},ua) &= \delta'(\hat\delta'(\{q\},u),a) &\text{(by definition of $\hat \delta'$)}\\ &= \delta'(\hat \delta(q,u),a) &\text{(by inductive hypothesis)}\\ &= \bigcup_{p \in \hat\delta(q,u)} \delta(p,a) &\text{(by definition of $\hat \delta'$)}\\ &= \hat \delta(q,ua). &\text{(by definition of $\hat \delta$)} \end{align*} Thus, we have shown that $\hat \delta(q,w) = \hat \delta'(\{q\},w)$ for all $q \in Q$ and $w \in \Sigma^*$, and we can conclude that $L(N) = L(\mathcal D(N))$. $$\tag*{$\Box$}$$
Of course, this only gives us half of what we need, although what remains is fairly simple. We can just state the following.
Theorem 5.5. A language $L$ is accepted by a DFA if and only if $L$ is accepted by an NFA.
We have already shown the only if direction of this theorem in Theorem 5.4. What's left to show is the if direction, which involves taking a DFA and constructing an equivalent NFA. This should be fairly simple to define and prove correctness for, so we won't go through it.
With what we've defined so far, we can show that the regular languages are closed under concatenation. However, let's take a few more diversions before doing that.
To play around with nondeterminism a bit, let's think back to one of the more exotic language operations from last class, the proportional removal $\frac 1 2 L$. Proportional removals were shown to preserve regularity by Stearns and Hartmanis in the early 60s.
Theorem 5.6. If $L$ is a regular language, then $$\frac 1 2 L = \{y \in \Sigma^* \mid xy \in L, |x| = |y|\}$$ is a regular language.
Proof. Let $L$ be recognized by a DFA $A = (Q,\Sigma,\delta,q_0,F)$. We will construct an NFA $A' = (Q',\Sigma,\delta',I',F')$, where
We need to check if our input word $y$ is the latter half of some word in our language. This means that there's some state $p$ from which we can reach a final state on $y$. We can also check that $y$ is the correct length (half of a word) by checking that there's a path of length $|y|$ from the initial state to $p$.
This is tough to do with a DFA, but if we use an NFA, we can simply guess all the possibilities. First, we guess what $p$ could've been. Then, we run our machine in parallel, by starting to process $y$ from the state $p$ that we guessed, and by guessing a path starting from the initial state $q_0$. If we reach a final state on $y$ and find a path from $q_0$ to $p$ of the same length, then we accept.
Here's how our machine does this: we use triples of states $\langle p,q,r \rangle$. We guess $p$ at the beginning and it doesn't change, so we remember which one we guessed. The state $q$ is the state that we end up in by guessing a prefix starting from the initial state $q_0$. The state $r$ is the state that we end up in by processing $y$ and starting on $p$.
To prove this formally we can show that $\langle p,q,r \rangle \in \delta'(I',x)$ if and only if there exists $x \in \Sigma^*$ with $|x| = |y|$ such that $\delta(q_0,x) = q$ and $\delta(p,y) = r$ by induction on $|y|$. Then we have \begin{align*} \delta'(I',y) \cap F' \neq \emptyset &\iff \exists x \in \Sigma^*, |x| = |y|, \delta(q_0,x) = p, \delta(p,y) \in F \\ &\iff \exists x \in \Sigma^*, |x| = |y|, \delta(q_0,xy) \in F \\ &\iff \exists x \in \Sigma^*, |x| = |y|, xy \in L \end{align*} $\tag*{$\Box$}$
This gives us an NFA, so a natural question to ask is how big an equivalent DFA must be. Since the states of our NFA is the set of 3-tuples of states of our original machine, if we started with an $n$-state DFA, we'd construct an NFA that has $n^3$ states. Taking the subset construction of this means that we could end up with $2^{n^3}$ states in an equivalent DFA. It turns out if you come up with a clever enough construction, Mike Domaratzki showed in 2001 that a DFA recognizing $\frac 1 2 L$ only requires at most $n e^{\Theta(\sqrt{n \log n})}$ states.