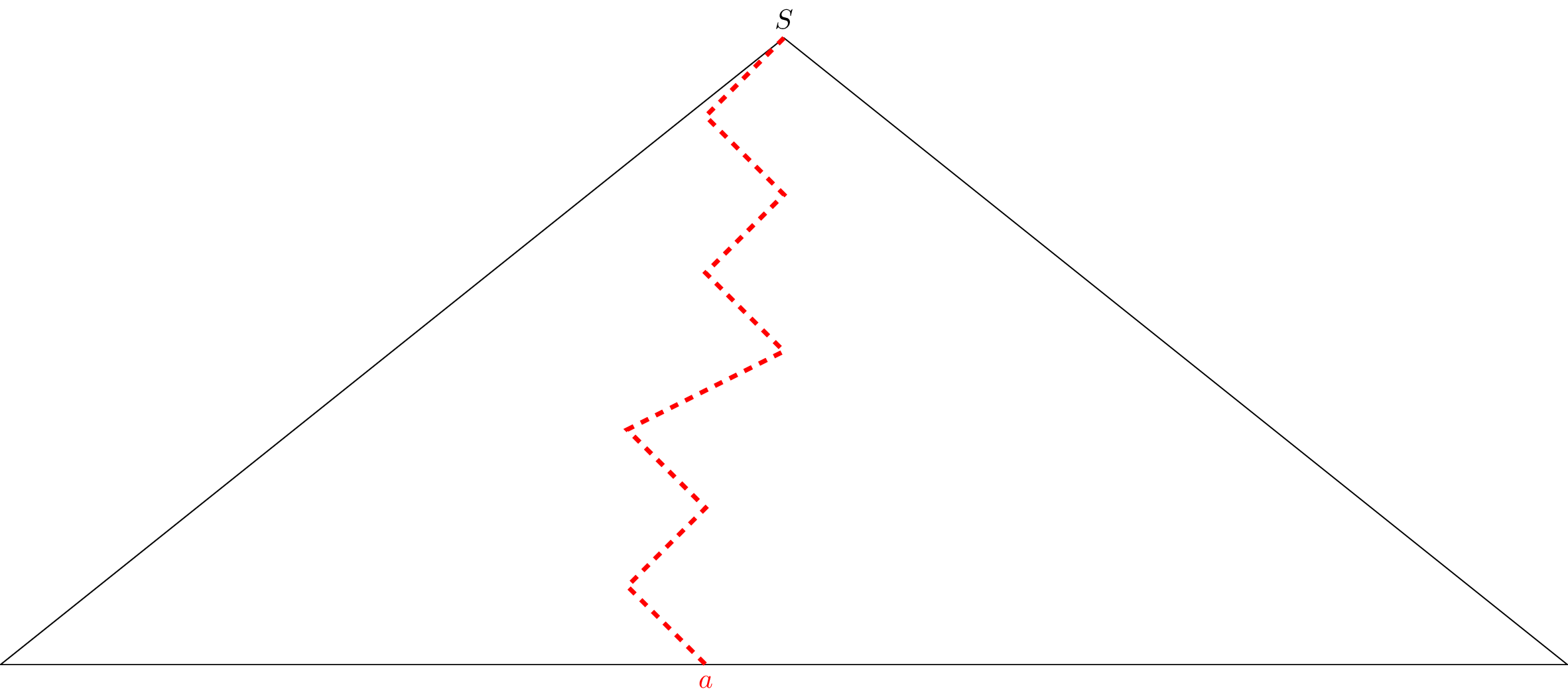
Now, we discover why, several weeks ago, when we discussed the pumping lemma, I wrote "pumping lemma for regular languages". Yes, it is because we are going to be talking about the pumping lemma for context-free languages today and have our first taste of the world beyond context-free languages.
Lemma 18.1 (Pumping lemma for context-free languages). Let $L \subseteq \Sigma^*$ be a context-free language. Then there exists a positive integer $n$ such that for every word $w \in L$ with $|w| \geq n$, there exists a factorization $w = uvxyz$ with $u,v,x,y,z \in \Sigma^*$ such that
This pumping lemma is due to Bar-Hillel, Perles, and Shamir in 1961. As it turns out, there are a lot of language classes for which there are pumping lemmas (deterministic context-free languages, indexed languages, regular tree languages).
The reasoning behind the pumping lemma for context-free languages is in the same vein as the one for regular languages. Since the description of any context-free grammar is finite, for a sufficiently long word, some aspect of its derivation must be repeated. For regular languages, this is analogous to the fact that a state will show up more than once on a path in a DFA. For context-free languages, this will be the fact that a variable appears more than once on a path in a parse tree.
Proof. Since $L$ is context-free, there must be a CFG $G$ in Chomsky normal form that generates it. Let $m$ be the number of variables in $G$. Then the pumping length for $L$ will be $n = 2^m$.
Consider a word $w \in L$ with $|w| \geq n = 2^m$. Since $G$ is in CNF, every parse tree for $w$ has exactly $2|w| - 1$ internal nodes and $|w|$ leaf nodes. We can choose any one of these parse trees, so let $T$ be the parse tree that we choose and fix it.
Note that $T$ has at least $2^m$ internal nodes, since $2|w| - 1 = 2 \cdot 2^m - 1 \geq 2^m$. Then there must be a path in $T$ from the root to a leaf with at least $m+1$ internal nodes. Otherwise, there could only be at most $2^m - 1$ internal nodes.
Pick a longest such path. Since there are at least $m+1$ internal nodes along this path and only $m$ variables, there must be a variable that appears twice in the path. Suppose this variable is $X$ and we have that there must be an occurrence of $X$ that is closest to the leaf on our chosen path.
Let $T_1$ and $T_2$ be two subtrees of $T$ that are rooted at the two occurrences of $X$ on the path closest to the leaf. Let $T_2$ be the tree rooted at the closest occurrence of $X$ so $T_2$ must be a proper subtree of $T_1$. Furthermore, every path from the root of $T_1$ to a leaf has at most $m+1$ internal nodes and therefore $T_1$ has at most $2^m = n$ leaf nodes.
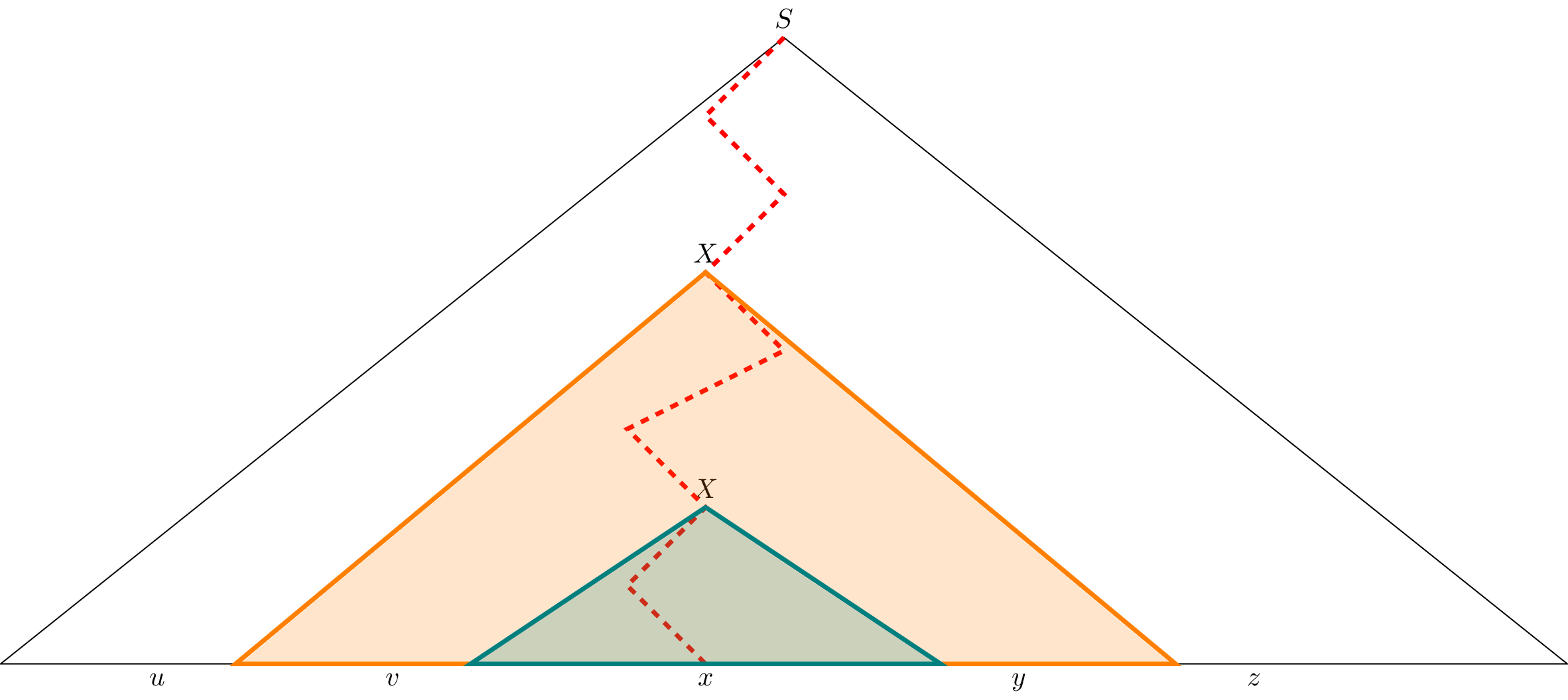
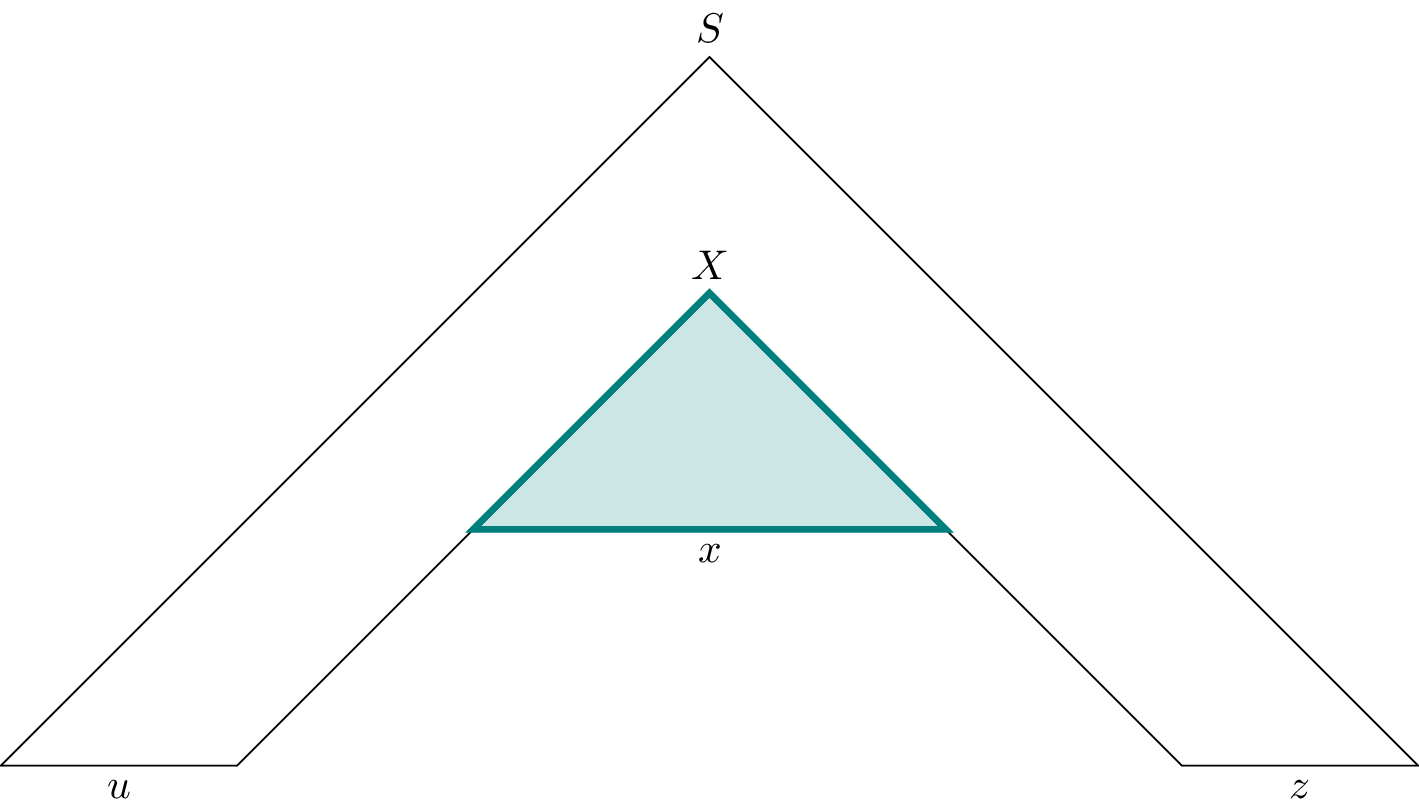
Let $x$ be the word for which $T_2$ is the parse tree rooted at $X$ and let $v$ and $y$ be the words formed by the leaves of the parse tree $T_1$ rooted at $X$ around $T_2$ such that $T_1$ is a parse tree for the word $vxy$. Then we let $u$ and $z$ be the words formed by the leaves of $T$ around $T_1$ such that $T$ is a parse tree for the word $w = uvxyz$.
Now we need to show that $uvxyz$ is a factorization for $w$ such that the conditions of the pumping lemma hold. First, to see that $|vxy| \leq n$, we just observe that $T_1$ can have at most $2^m = n$ leaf nodes.
Next, to see that $vy \neq \varepsilon$, we note that since both $T_1$ and $T_2$ are rooted at $X$, we can construct a parse tree in which $T_1$ is removed and replaced by $T_2$. This would then be a parse tree for $uxz$. However, recall that every parse tree for a word in a grammar in CNF must have exactly the same size. Since $T_2$ was already shown to be smaller than $T_1$ we must have that $uxz \neq uvxyz$ and therefore $vy \neq \varepsilon$.
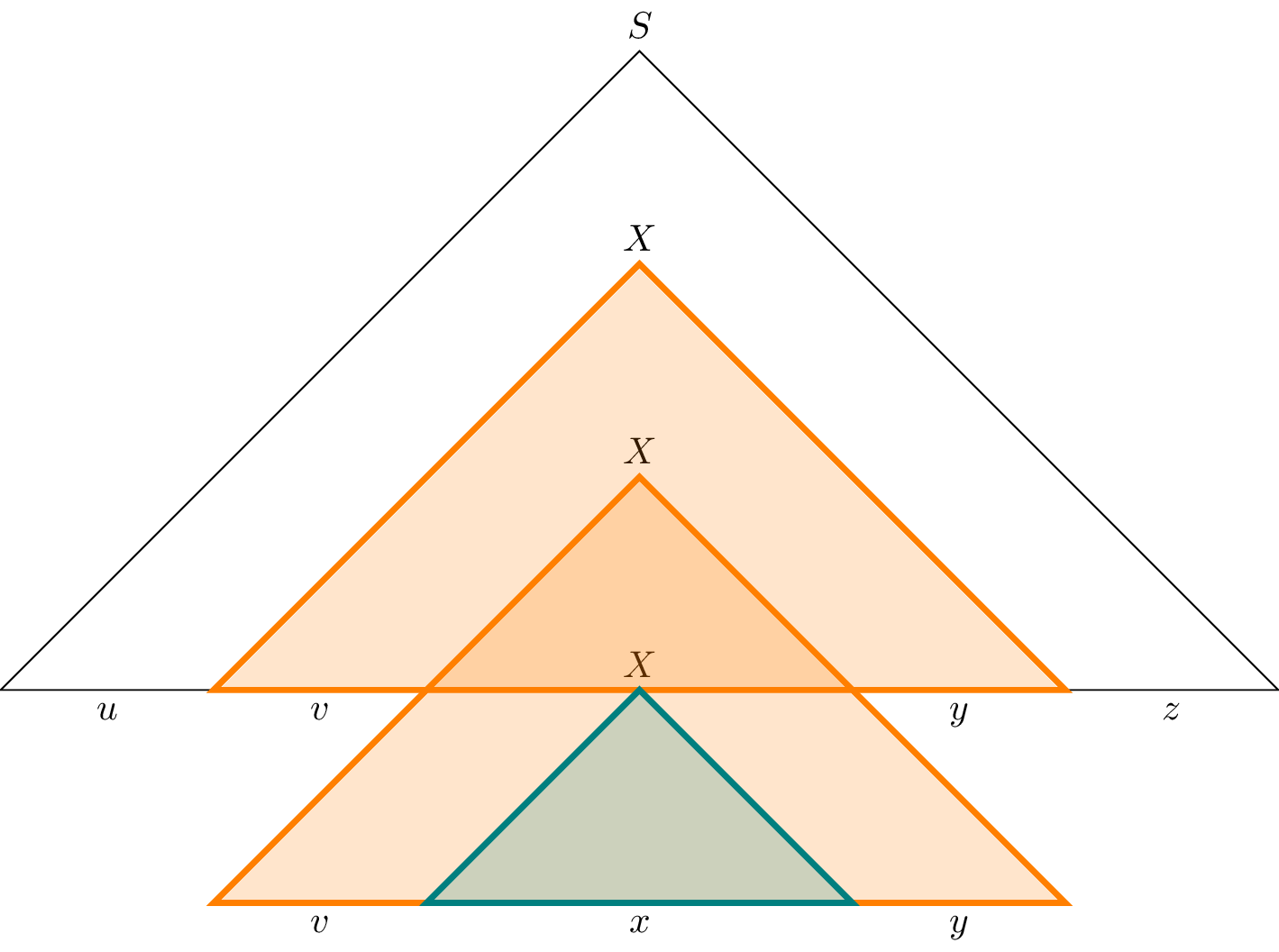
Finally, to see that $uv^ixy^iz \in L$ for all $i \in \mathbb N$, we first note that we have already shown $uv^0 xy^0 z \in L$ above. To see that this holds for $i > 1$, we can perform a similar substitution by replacing $T_2$ with $T_1$ to give us a parse tree for $uv^2xy^2$. We can then repeat this process any number of times to obtain a parse tree for $uv^ixy^iz$. $$\tag*{$\Box$}$$
Our strategy is very similar to the one we employed for regular languages. We assume that our language is context-free, then show that we are able to find a string that is unable to satisfy the conditions of the pumping lemma by following our template from before.
Then we win if $uv^ixy^iz \not \in L$.
However, there are a few more things to be mindful of when carrying out these proofs for context-free languages. The main difference between proofs using the pumping lemma for CFLs and the pumping lemma for regular languages is there is much more we have to do to ensure that we've considered all possible decompositions. The other difference is that the factorization into five factors rather than just three makes explicitly defining the factors much more of a hassle.
Proposition 18.2. Let $L = \{a^m b^m c^m \mid m \geq 0\}$. Then $L$ is not context-free.
Proof. Suppose that $L$ is context-free and let $n$ be the pumping length for $L$. Let $w = a^n b^n c^n$. Clearly, $w \in L$ and $|w| = 3n \geq n$. Now, we must consider all factorizations of $w = uvxyz$ such that $|vxy| \leq n$ and $vy \neq \varepsilon$. There are two cases to consider.
Thus, every factorization of $w = uvxyz$ fails to satisfy the pumping lemma and therefore $L$ is not context-free as assumed. $$\tag*{$\Box$}$$
Note that if we wanted to be more specific, we would have to list five different cases in the above proof. Luckily, each of these cases folds nicely into just two broad cases. All of this makes choosing the word $w$ to be pumped much more important in avoiding a lot of work.
Proposition 18.3.. Let $L = \{ww \mid w \in \{a,b\}^* \}$. Then $L$ is not context-free.
Proof. Suppose $L$ is context-free and let $n$ be the pumping length for $L$. Let $w = a^n b^n a^n b^n$. Then $w = (a^n b^n)^2 \in L$ and $|w| = 4n \geq n$. Now, we must consider factorizations $w = uvxyz$ with $|vxy| \leq n$ and $vy \neq \varepsilon$. There are two cases.
Thus, every factorization of $w = uvxyz$ fails to satisfy the pumping lemma and therefore $L$ is not context-free as assumed. $$\tag*{$\Box$}$$
This is the "copy" language that we saw when we were discussing "real" regular expressions vs "theoretical" regular expressions. Being able to identify "copies" within a word is something that we can do with POSIX regular expressions via backreferences. We can see here that backreferences actually take us even beyond the context-free languages. The Câmpeanu, Salomaa, and Yu paper that I mentioned earlier shows us that the class of languages that can be matched POSIX regular expressions is actually incomparable with the context-free languages: there are CFLs that can't be matched by POSIX regular expressions and there are POSIX regular expression languages that aren't context-free.
Again, note that in the above proof, if we were to write out each case exhaustively, we would end up with as many as seven cases to consider. Part of understanding how to go about these proofs will be understanding the process well enough to identify all of the different cases and understanding which ones can be grouped together.
Proposition 18.4. Let $L = \{ a^p \mid \text{$p$ is a prime number} \}$. Then $L$ is not context-free.
Proof. Suppose $L$ is context-free and let $n$ be the pumping length for $L$. Since there are infinitely many prime numbers, for any choice of $n$, we can always choose $p$ such that $p > n$. Let $w = a^p$ with $p \geq n$. We consider a factorization $w = uvxyz$ where $|vxy| \leq n$ and $vy \neq \varepsilon$.
Now consider for $i \in \mathbb N$ the word $uv^i x y^iz$. We can write $uv^ixy^iz = a^{p+(i-1)\cdot k}$ for $|vy| = k \leq n$ since $w$ is unary. Observe that choosing $i = p+1$ gives us $p+p\cdot k = (k+1)p$, which is not a prime number. Thus, $uv^ixy^iz \not \in P$ for $i = p+1$ and $w$ fails to satisfy the pumping lemma. Thus, $L$ is not context-free as assumed. $$\tag*{$\Box$}$$
For this problem, life is a lot simpler since being a unary language means that where the factors lie in the word is not quite as important. In fact, this proof is almost the same as the one for regular languages.
The pumping lemma for regular languages (and various other results) pointed to the idea that when we think about regular languages, we should think about finiteness and the property that regular languages are characterized by only being able remember or keep track of finitely many things. Then what's the analogous idea to keep in mind to determine whether something is context-free?
The hint is in our discussions about the Chomsky-Schützenberger theorem and properly nested brackets. One of the key ideas behind context-free languages is symmetry. Consider the following two examples.
Example 18.5. Consider the language $$L_1 = \{x\$x \mid x \in \{a,b\}^*\}.$$ It's not hard to show that $L_1$ is not context-free; the proof is almost the same as for the language of squares $ww$. However, the following language is almost the same, but is context-free, $$L_2 = \{x\$x^R \mid x \in \{a,b\}^*\}.$$ Again, this is similar to something we've seen before, and it's not hard to see how we could construct a CFG or PDA for $L_2$.
Example 18.6. Consider the language $$L_3 = \{a^m b^n c^m d^n \mid m,n \geq 0\}.$$ One can show via the pumping lemma that $L_3$ is not context-free. It's also helpful to think about why this might not work by trying to construct a PDA: if we keep track of the number of $a$'s and $b$'s we see, then once we see a $c$, we have to dig too far into the stack to get to the information we need about how many $a$'s we saw. However, the following similar looking language turns out to be context-free, $$L_3 = \{a^m b^n c^n d^m \mid m,n \geq 0\}.$$ Here, we see how making things more "symmetric" allows us to build a PDA or CFG for this language. I can keep track of the number of $a$'s and $b$'s we've seen on the stack and, conveniently, we can just pop everything off the stack in the correct order to process the $c$'s and $d$'s.
Here, we run into our first problem: we haven't shown yet that the CFLs are not closed under complementation. One immediate consequence of this is that we are not able to prove that the CFLs are closed under intersection using De Morgan's laws like we did for regular languages. Perhaps there is some other way of doing this? But first, we'll have a look at something easier.
Here, we'll show that CFLs are closed under intersection with a regular language. This might seem strange at first, but it turns out to be quite handy. We'll also get to make use of the fact that CFLs are recognized by PDAs.
Theorem 18.7. Let $L \subseteq \Sigma$ be a context-free language and let $R \subseteq \Sigma^*$ be a regular language. Then $L \cap R$ is a context-free language.
Proof. Let $A = (Q_A,\Sigma,\Gamma,\delta_A,s_A,Z_0,F_A)$ be a PDA that accepts $L$ and let $B = (Q_B, \Sigma, \delta_B, s_B, F_B)$ be a DFA that recognizes $R$. We will construct a PDA $C = (Q_C, \Sigma, \Gamma, \delta_C, s_C, Z_0, F_C)$ that recognizes $L \cap R$. We have
The PDA $C$ works by simultaneously moving through a computation of $A$ and $B$. When a transition is made, $C$ will keep track of the current state of $A$ via the first component of each state of $C$ and by using the stack as normal. The current state of $B$ is kept track of as the second component of the states of $C$. In addition, when $A$ makes $\varepsilon$-transitions, the state of $B$ does not change.
It is not too difficult to see that in this way, $C$ can move simultanenously through $A$ and $B$. Then, the set of accepting states of $C$ is defined to be pairs of states in $F_A$ and $F_B$. In other words, a word accepted by $C$ must have a computation that ends in a state $\langle p,q \rangle$ with $p \in F_A$ and $q \in F_B$. In other words, there is a computation for $w$ on $A$ that ends in a final state and there is a computation for $w$ on $B$ that ends in a final state. Thus, $C$ accepts $w$ if and only if $w$ is accepted by both $A$ and $B$ and this is only the case if and only if $w \in L \cap R$. Thus, $C$ is a PDA that accepts $L \cap R$ and $L \cap R$ is a context-free language. $$\tag*{$\Box$}$$
So how can we deploy this result? We can use it in much the same way that we used intersection with regular languages.
Proposition 18.8. Let $L = \{ w \in \{a,b,c\}^* \mid |w|_a = |w|_b = |w|_c \}$. Then $L$ is not context-free.
Proof. Suppose $L$ is a context-free language. Then it is closed under intersection with regular languages. However, consider the regular language $L(a^* b^* c^*)$ and $$L \cap L(a^* b^* c^*) = \{a^m b^m c^m \mid m \in \mathbb N \}.$$ This language is known to be not context-free. Therefore $L$ must not be context-free. $$\tag*{$\Box$}$$
Unfortunately, we can't use the cross product construction to build a PDA for the intersection of two CFLs. A similar construction would require keeping track of two different stacks and it is unclear how one would manage this with only one stack. The answer is that you can't, because context-free languages are not closed under intersection.
Theorem 18.9. There exist context-free languages $L_1, L_2 \subseteq \Sigma$ such that $L_1 \cap L_2$ is not a context-free language.
Proof. Let $L_1 = \{a^i b^i c^j \mid i,j \geq 0\}$ and let $L_2 = \{a^i b^j c^j \mid i,j \geq 0\}$. It is easy to see that $L_1$ and $L_2$ are both context-free. Consider for $\sigma_1, \sigma_2 \in \Sigma$ the languages \begin{align*} L_{\sigma_1,\sigma_2} = \{\sigma_1^m \sigma_2^m \mid m \geq 0 \}, \\ K_{\sigma_1} = \{\sigma_1^i \mid i \geq 0\}. \end{align*} We have already seen that $L_{\sigma_1,\sigma_2}$ is context-free and $K_{\sigma_1}$ is just $\sigma_1^*$, which is regular (and therefore, context-free). Since context-free languages are closed under concatenation, we have $L_1 = L_{a,b} K_c$ and $L_2 = K_a L_{b,c}$. Thus, $L_1$ and $L_2$ are context-free languages. Then, we have $$L_1 \cap L_2 = \{a^i b^i c^i \mid i \geq 0\}.$$ We have already shown that this language is not context-free. $$\tag*{$\Box$}$$
Thus, the class of context-free languages is not closed under intersection.
Now, we will show that the class of context-free languages is not closed under complementation.
Theorem 18.10. There exists a context-free languages $L$ such that $\overline L = \Sigma^* \setminus L$ is not a context-free language.
Proof. Let $L_1 = \{ a^i b^j c^k \mid i \neq j\} \cup \{a^i b^j c^k \mid j \neq k\}$ and let $L_2 = \overline{L(a^* b^* c^*})$. It is clear that $L_2$ is regular. To see that $L_1$ is context-free, we observe that we can write $$\{a^i b^j c^k \mid i \neq j\} = \left(\{ a^i b^j \mid i < j\} \cup \{a^i b^j \mid i > j\} \right) \{c^k \mid k \geq 0\}$$ and similarly, we have $$\{a^i b^j c^k \mid j \neq k\} = \{a^i \mid i \geq 0\} \left(\{ b^j c^k \mid j < k\} \cup \{b^j c^k \mid j > k\} \right).$$
Then $L = L_1 \cup L_2$ is a context-free language. However, observe that by DeMorgan's laws, we have $$\overline L = \overline{L_1 \cup L_2} = \overline{L_1} \cap \overline{L_2}.$$ First, we observe that $\overline L_2 = L(a^* b^* c^*)$ and therefore words of $\overline L$ must be of this form. Next, we recall that $\overline{L_1}$ consists of words that are not of the form $a^i b^j c^k$ with $i \neq j$ or $j \neq k$. In other words, if words of $L_1$ are of the form $a^i b^j c^k$, we must have $i = j = k$. But this means that $$\overline L = \overline{L_1} \cap \overline{L_2} = \{a^m b^m c^m \mid m \geq 0\}.$$ Of course, we have already seen that this language is not context-free. $$\tag*{$\Box$}$$