Unlike the pumping lemma, the Myhill-Nerode theorem does give us a way to show that a language is regular: simply show that the Myhill-Nerode equivalence for the language has finite index. Just like the previous examples, the equivalence classes of the Myhill-Nerode relation essentially tell us what the states of our automaton should be. For instance, recall that transforming an NFA into a DFA can result in a DFA with as many as $2^n$ states. Do we need all of those states? The Myhill-Nerode theorem gives us a way to figure this out.
Example 11.1. Let $L_n = \{a,b\}^* b \{a,b\}^{n-1}$. We claim that the equivalence classes of $\equiv_{L_n}$ are $$\{w \in \{a,b\}^* \mid |w| = n\}.$$ That is, each string of length exactly $n$ is in its own equivalence class. To see this, choose any two strings of length $n$, say $u = c_1 c_2 \dots c_n$ and $v = d_1 d_2 \cdots d_n$. Since $u \neq v$, there exists $i$, $1 \leq i \leq n$ such that $c_i \neq d_i$. Without loss of generality, say $c_i = b$ and $d_i = a$. Let $w = a^i$. Then $uw \in L$ and $vw \not \in L$.
So we've shown that each string of length $n$ defines its own equivalence class, so we need at least $2^n$ equivalence classes for $\equiv_{L_n}$. Could there be more? Suppose there is and let $x$ be a string from that equivalence class. If $|x| \gt n$, we can write $x = yz$ where $z$ is some suffix of length $n$. But then $xu \in L_n \iff zu \in L_n$ for every $u \in \Sigma^*$ and therefore, $x \equiv_{L_n} z$. If $|x| \lt n$, it's easy to see that $x \in [a^{n-|x|}x]$. Thus, we've shown that there are exactly $2^n$ Myhill-Nerode equivalence classes for $L_n$.
This tells us that any DFA that accepts $L_n$ will need to be able to distinguish all prefixes of length $n$ for any input string, and so it must contain at least $2^n$ states.
We can also use this idea to find lower bounds on the number of states required for the DFA recognizing the result of language operations. For example, recall that we showed that we can use the product construction to obtain a DFA that recognizes the intersection of two regular languages. If the two languages have DFAs of size $m$ and $n$, then the product construction gives a DFA with up to $mn$ states. But do we really need that many? We can show that there exist languages for which we do need all of those states.
Example 11.2. Let $\Sigma = \{0,1\}$ and let $L_m = \{w \in \Sigma^* \mid |w|_0 = 0 \pmod m\}$ and $L_n = \{w \in \Sigma^* \mid |w|_1 = 0 \pmod n\}$. Then $L_m$ can be recognized by a DFA with $m$ states and $L_n$ can be recognized by a DFA with $n$ states (you can try to find the DFAs yourselves as an easy exercise). Then $$L_m \cap L_n = \{w \in \Sigma^* \mid |w|_0 = 0 \pmod m, |w|_1 = 0 \pmod n\}.$$ So we need to consider the equivalence classes of $\equiv_{L_m \cap L_n}$.
We will consider strings $0^i 1^j$ with $0 \leq i \lt m$ and $0 \leq j \lt n$ to be our representatives for the equivalence classes. To show that these are all distinct, we consider two words $x = 0^i 1^j$ and $y = 0^k 1^\ell$ with $0 \leq i, k \lt m$, $0 \leq j, \ell \lt n$, and $x \neq y$. This means that $i \neq k$ or $j \neq \ell$ (or both). We suppose $i \neq k$; the $j \neq \ell$ case follows a similar argument.
We choose the word $z = 0^{m-i} 1^{n-\ell}$. Then $xz \in L_m \cap L_n$ but $yz \not \in L_m \cap L_n$. To see this, the number of $0$s in $xz$ is $i + m - i = 0 \pmod m$ and the number of $1$s in $xz$ is $j + n - j = 0 \pmod n$. But the number of $0$s in $yz$ is $k + m - i \neq 0 \pmod m$ if $k \neq i$. So $z$ distinguishes $x$ and $y$.
This means that there are at least $mn$ pairwise distinguishable Myhill-Nerode equivalence classes ($i$ can range from 0 to $m-1$ and $j$ can range from 0 to $n-1$). Since we know that the product construction has at most $mn$ states, we've shown that the product automaton for $L_m \cap L_n$ must have exactly $mn$ states.
The proof of the Myhill-Nerode theorem defines a DFA $A_{\equiv_L}$ for a regular language $L$. If we recall that the Myhill-Nerode equivalence classes are about distinguishable prefixes with respect to $L$, this suggests that a DFA recognizing $L$ will need at least as many states as $L$ has Myhill-Nerode equivalence classes. But these equivalence classes correspond to the states of $A_{\equiv_L}$, which means that any DFA that recognizes $L$ must have at least as many states as $A_{\equiv_L}$. This leads to the notion of a minimal DFA, in terms of the number of states it has, for a language. So it's clear from this that any minimal DFA will have as many states as there are Myhill-Nerode equivalence classes for its language, but we can actually say something stronger than that: the Myhill-Nerode DFA is the only minimal DFA for its language.
Theorem 11.3. Let $L$ be a regular language. The DFA $A_{\equiv_L}$ is the unique minimal DFA for $L$ up to isomorphism.
Proof. Let $A = (Q,\Sigma,\delta,q_0,F)$ be a minimal DFA for $L$. Recall that the equivalence classes of the relation $\sim_A$ correspond to states of $A$. By Lemma 10.11, $\sim_A$ refines $\equiv_L$ and therefore, the index of $\sim_A$ must be at least the index of $\equiv_L$. Since we assumed $A$ was minimal, this means that $A$ has exactly as many states as $A_{\equiv_L}$.
Now, we need to show that there is a correspondence between states of $A$ and states of $A_{\equiv_L}$. Let $q \in Q$. Then $q$ must be reachable from the initial state $q_0$, since otherwise, we can remove it. This means there exists a word $w \in \Sigma^*$ such that $\delta(q_0,w) = q$. Then $q$ corresponds to the equivalence class for $[w]$. $\tag*{$\Box$}$
Before getting to how to actually compute this, it is worth noting that the existence of a minimal DFA and the fact that a regular language has a unique minimal DFA gives us a way to test whether two DFAs or NFAs or regular expressions correspond to the same language: just turn the two objects into a minimal DFA and if they're the same, then they accept the same language.
This brings us to the question of how to compute the minimal DFA. Theorem 11.1 gives us the basic idea. Consider a DFA $A = (Q,\Sigma,\delta,q_0,F)$ and two states $p,q \in Q$. If for all $w \in \Sigma^*$, $\delta(p,w) \in F \iff \delta(q,w) \in F$, then $p$ and $q$ must correspond to the same Myhill-Nerode equivalence class and we can replace both states with a single state.
Algorithm 11.4 (DFA minimization).
The automaton that we get out of this is called the quotient automaton, because if you think about our automaton as an algebraic object (which it is), then we're essentially performing a quotient construction on it. Generally speaking, we could refer to any equivalence relation, but the one that matters the most in our case is $\equiv_L$, the Myhill-Nerode relation for the language of the machine. And so we can refer to this as $A/\equiv_L$ if we want.
If you don't care about algebra, don't read this. Algebraists... hello. As I've mentioned offhandedly at various points in class, we can think of languages as subsets of the free monoid on $\Sigma$. Now, we have these notions of equivalence classes of words and quotient constructions on automata so you may be wondering how these are all related.
Back when we defined regular languages in terms of regular operations, I mentioned that the same operations (union, concatenation/product, star) were called rational operations when applied to general monoids, not just free monoids, that can be used to define the rational subsets of a monoid. In fact, there is another notion that we can apply that has suspiciously similar terminology, called recognizable subsets of a monoid.
We use recognizable in the same way as we do acceptance when thinking about the finite automaton as a machine, but again, there is a more general monoid definition for this. A subset $X \subseteq M$ of a monoid $M$ is recognizable if there exist a finite monoid $N$, morphism $\varphi:M \to N$ and a subset $P \subseteq N$ such that $X = \varphi^{-1}(P)$.
So if we have $M = \Sigma^*$, then $X$ would be a language. The requirement that $N$ is a finite monoid should get your spidey-senses tingling and that it probably has to do with the Myhill-Nerode equivalence classes somehow. Using that assumption for now, the rest of the definition falls into place: our language $X$ is just the preimage of words that map, via our monoid homomorphism $\varphi$, to $P$, which we think should be the subset of the Myhill-Nerode equivalence classes we want.
Our intuition gets us most of the way there, but falls short, since the Myhill-Nerode equivalence is only concerned with right-sided syntactic equivalence ($u \equiv_L v$ iff for all $x \in \Sigma^*, ux \in L \iff vx \in L$). There's also a left-sided version of this: $u \approx_L v$ if and only if $\forall x \in \Sigma^*, xu \in L \iff xv \in L$. If we combine the two, we get what is the Myhill relation or syntactic relation, $$u \approx_L v \iff (\forall s,t \in \Sigma^*, sut \in L \iff svt \in L).$$ Then our finite monoid $N$ from the definition is exactly the quotient monoid $\Sigma^*/\approx_L$. This is called the syntactic monoid of $L$.
So it's probably still not clear how this is useful, so let's consider yet another monoid. This time, let's take our language $L$ and some DFA $A$ that accepts it. It would probably not surprise you that we can also map the structure of the DFA onto a monoid. Instead of thinking of the transition function as a function $\delta:Q \times \Sigma \to Q$, we can create a set of functions $\delta_a : Q \to Q$, that for each symbol $a \in \Sigma$ map $Q$ to itself. Then, we can compose functions to get transition functions on words $\delta_w = \delta_x \circ \delta_a$ for $w = xa$ with $x \in \Sigma^*$ and $a \in \Sigma$. Then the transition monoid of $A$ is the monoid of our set of functions $\delta_a$ together with function composition as the binary operation. This gives us an obvious monoid morphism from $\Sigma^*$ to the transition monoid.
The big connection is this: the transition monoid of the minimal DFA of $L$ is isomorphic to the syntactic monoid of $L$. And with this, Kleene's theorem can be restated as a theorem about monoids. Recall that Kleene's theorem says that if a language is regular (can be described using regular operations), then it is accepted by a DFA. But we know that regular languages are just rational subsets of $\Sigma^*$, which are those subsets that can be described using rational operations, which are just regular operations. We also know that languages that are accepted by DFAs are just recognizable subsets of $\Sigma^*$, which are those subsets that are recognized by a finite syntactic monoid, which is isomorphic to the transition monoid of a finite automaton. So we have
Theorem (Kleene). If $\Sigma$ is a finite alphabet and $L \subseteq \Sigma^*$, then $L$ is rational if and only if $L$ is recognizable.
Very cool. Everyone else can start reading again.
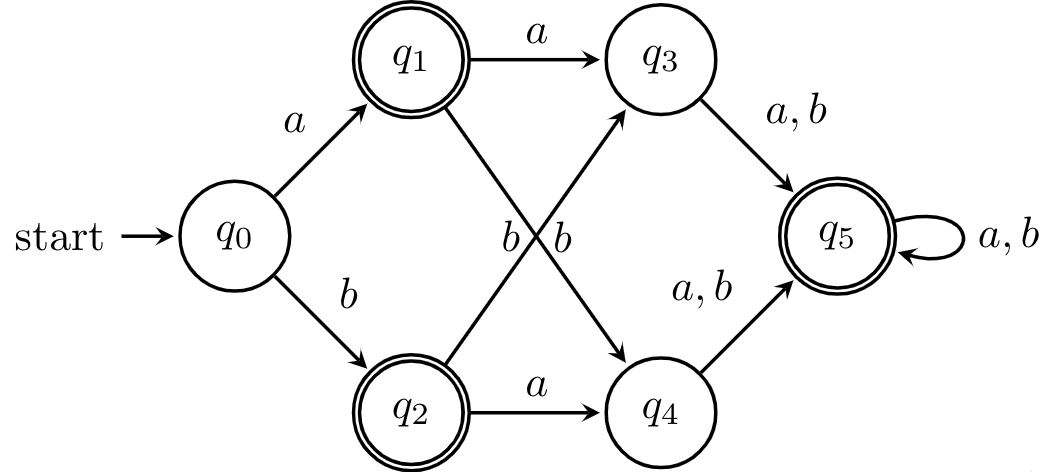
Example 11.5. Let's try an example. We have the following DFA.
First, we set up our table and consider the first iteration of our algorithms. Note that since pairs are unordered, we only fill half the table, so to distinguish unmarked cells from empty cells, we use -. Marked pairs of states are marked by which round of iteration they were marked in, for demonstrative purposes.
| $q_1$ | $q_2$ | $q_3$ | $q_4$ | $q_5$ | |
|---|---|---|---|---|---|
| $q_0$ | 1 | 1 | - | - | 1 |
| $q_1$ | - | 1 | 1 | - | |
| $q_2$ | 1 | 1 | - | ||
| $q_3$ | - | 1 | |||
| $q_4$ | 1 |
Next, we consider each pair of unmarked states and determine whether each pair reaches a marked pair. We have that $(q_1,q_5)$ and $(q_2,q_5)$ get marked in this phase, because $(\delta(q_1,a), \delta(q_5,a)) = (q_3,q_5)$ and $(\delta(q_2,a), \delta(q_5,a)) = (q_4,q_5)$, which have been marked distinguishable.
The reasoning here is simple: suppose that a pair wasn't distinguishable. Then, because the reaching a state relation $\sim_A$ is right-invariant, reading any word from the two states should get us to indistinguishable states. But clearly, this isn't the case, since reading $a$ brings us to a pair of distinguishable states. It's not too hard to see that we can extend this argument inductively.
| $q_1$ | $q_2$ | $q_3$ | $q_4$ | $q_5$ | |
|---|---|---|---|---|---|
| $q_0$ | 1 | 1 | - | - | 1 |
| $q_1$ | - | 1 | 1 | 2 | |
| $q_2$ | 1 | 1 | 2 | ||
| $q_3$ | - | 1 | |||
| $q_4$ | 1 |
We do another round of this, taking into account the new pairs of distinguishable states.
| $q_1$ | $q_2$ | $q_3$ | $q_4$ | $q_5$ | |
|---|---|---|---|---|---|
| $q_0$ | 1 | 1 | 3 | 3 | 1 |
| $q_1$ | - | 1 | 1 | 2 | |
| $q_2$ | 1 | 1 | 2 | ||
| $q_3$ | - | 1 | |||
| $q_4$ | 1 |
At this point, we're finished because and we have two pairs of states that are indistinguishable. We can merge these states safely to get the following DFA.
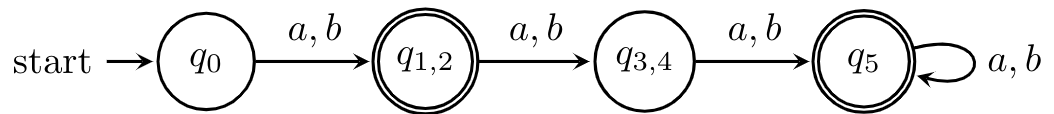
This algorithm is something like $O(|\Sigma| n^3)$ worst-case time complexity, where $n$ is the number of states in your DFA. If you are slightly more clever, we can get this down to $O(|\Sigma| n^2)$, by maintaining a list of pairs $\{p',q'\}$ for each pair $\{p,q\}$, with $p' = \delta(p,a)$ and $q' = \delta(q',a)$ for some $a \in \Sigma$. Then, once the lists are built, we can mark pairs by going through the list in one go.
By virtue of being a polynomial-time algorithm, we've shown that we can consider DFA minimization to be "efficient". So we can take for granted that we can efficiently determine whether two DFAs recognize the same language. For NFAs and regular expressions, things are a bit harder because the determinization process can lead to exponential state blowups.
However, there are algorithms that arguably do better. The algorithm with the best worst-case time complexity is Hopcroft's partition refinement algorithm which has $O(n \log n)$ time complexity. The other candidate for a better algorithm is an algorithm due to Janusz Brzozowski, and while it has worst-case exponential time, it seems to work as well as Hopcroft's algorithm in practice in many cases and is surprisingly simple to describe.
Theorem 11.6 (Brzozowski). The DFA $\mathcal D((\mathcal D(A^R))^R)$ is a minimal DFA equivalent to $A$.
This gives us the algorithm: take your DFA $A$, reverse it, then determinize the result, reverse the determinized machine, then determinize the result of that. But why does this work?