
So far, we have been focused on languages as problems to be solved by some model of computation. In particular, we’ve been giving our attention to finite automata, whether they’re deterministic or not (and as we saw, the distinction doesn’t matter when thinking about power), and what kinds of languages are recognizable using finite automata. Though we have a partial answer to the question of power via the pumping lemma, the property that it gives us still seems to be tied to the machine model, via the “pumping constant” which we understand to be the number of states of a finite automaton.
That is, this still doesn’t quite answer the question of what makes a language simple enough that it can be recognized by a DFA. Since this doesn’t seem like something that we can answer by looking only at the model of computation, we’ll step back and investigate other properties of these languages.
Are there other ways to describe and represent languages? Recall that languages are sets and that we can perform all the usual set operations on these sets to describe or construct new languages. We also extended some string operations to languages. We will now define a specific set of these operations to be regular operations.
Let $\Sigma$ be an alphabet and let $L,M \subseteq \Sigma^*$ be languages. The following operations are the regular operations:
So what’s so special about these particular operations? In some sense, we can think of these as the minimal set of operations needed to describe “interesting” things.
These operations define what we call the class of regular languages.
The class of regular languages over $\Sigma$ is the smallest family of languages over $\Sigma^*$ that contains the closure of the finite languages under the regular operations union, concatenation, and star. The class of regular languages over $\Sigma$ may be denoted $\operatorname{\mathsf{Reg}} \Sigma^*$.
In other words, the regular languages are any language that we can get by starting with a finite set and combining them by using union, concatenation, and star as much as we like.
This definition for a class of languages is very different from the classes related to DFAs and NFAs. The machine-based definitions tell us how to recognize a language, whereas the operational/closure-based definition gives us more of an idea of how to construct the language.
But why are these called regular languages? These definitions come from Kleene in 1951. Kleene arbitrarily gave them this name, leaving the door open to some other better name, and no one bothered to come up with a better name since.
That’s not actually entirely true, because there is another name that shows up in the algebraic/French literature. There, they refer to rational operations and languages. This tends to be more prevalent among algebraic automata theorists and French mathematicians. But the prevailing terminology, especially among computer scientists, is going to be regular languages.
Up to now, we’ve only considered finite automata as a way to describe a language. However, using finite automata as a description has its limitations, particularly for humans. While all of the finite automata we’ve seen so far are reasonably understandable, they are relatively small. Finite automata as used in practical applications can contain hundreds or thousands or more states.
In contrast, our definition of regular languages lays out the pieces and operations we are allowed to use to describe a language. This has the feel of algebra: we have a set of base elements and a set of operations that we can use on these elements. This leads us to the algebraic constructs that are called regular expressions.
A regular expression over an alphabet $\Sigma$ is defined inductively by
For convenience (i.e. to avoid putting parentheses everywhere), we establish an order of operations, like for typical arithmetic expressions:
and as usual, we can explicitly define an order for a particular expression by using parentheses.
Here are some examples of how to interpret the different combinations of operators according to our established rules for precedence.
So far, we’ve just dealt with the syntax of regular expressions. Now, we’ll define what these expressions actually mean. Since regular expressions were defined inductively, we will do the same here.
The language of a regular expression over an alphabet $\Sigma$ is defined inductively by \begin{align*} L(\varnothing) &= \emptyset, & L(\mathtt \epsilon) &= \{\varepsilon\}, & L(\mathtt a) &= \{a\} \text{ for $a \in \Sigma$}, \end{align*}
and if $\mathbf r_1$ and $\mathbf r_2$ are regular expressions, then \begin{align*} L(\mathbf r_1 + \mathbf r_2) &= L(\mathbf r_1) \cup L(\mathbf r_2), & L(\mathbf r_1 \mathbf r_2) &= L(\mathbf r_1) L(\mathbf r_2), & L(\mathbf r_1^*) &= L(\mathbf r_1)^*. \end{align*}
We say that the regular expression $\mathbf r$ matches the language $L(\mathbf r)$.
Consider the regular expression $\mathbf r = \mathtt{(a+b)^* b (a+b)(a+b)}$. The language of $\mathbf r$ is $L(\mathbf r)$, the language of strings over the alphabet $\{a,b\}$ with $b$ in the third from last position. So, $abbb \in L(\mathbf r)$. If we want to describe $L(\mathbf r)$ using the regular operations, we would have something like: \[L(\mathbf r) = (\{a\} \cup \{b\})^* \{b\} (\{a\} \cup \{b\}) (\{a\} \cup \{b\}).\]
I want to highlight another bit of notation here. I use $\mathbf{boldface}$ to denote regular expressions and $\mathtt{monospace}$ to denote the symbols used in the regular expression. Notice also that the symbols $\varnothing$ and $\epsilon$ are used in regular expressions while $\emptyset$ and $\varepsilon$ are used when talking about strings and languages.
This is because there’s often confusion about the difference between the regular expression itself and the language of the regular expression. A regular expression $\mathbf r$ over an alphabet $\Sigma$ should be considered a string over the alphabet $\{\mathtt a \mid a \in \Sigma\} \cup \{\mathtt (,\mathtt ),\mathtt \varnothing,\mathtt *,\mathtt +,\mathtt \epsilon\}$, while the language of $\mathbf r$, $L(\mathbf r)$ is a set of words over $\Sigma$.
Jacques Sakarovitch, in Elements of Automata Theory, refers to this distinction as a bit of “tetrapyloctomy” but proceeds to point out that what we’re dealing with is really the distinction between a syntactic object (the expression) and the semantic object (the language). As computer scientists, we are constantly having to navigate this distinction—we’ve already seen this before when trying to prove that a DFA works correctly.
How does the definition of regular expressions line up with the definition of regular languages? It’s not too hard to see how we the inductive case lines up with the notion of closure under the regular operations. What is left is to observe that the finite languages are all just unions of singleton sets of strings and strings are just concatenations of single symbols. In other words, we can always start with just the empty set, the empty string, and symbols of the alphabet and combine them using the regular operations to get all of the regular languages.
This is convincing enough, but we can formalize this into a proof.
A language over $\Sigma$ is regular if and only if there is a regular expression over $\Sigma$ that matches it.
First, consider the class of languages matched by regular expressions. Regular expressions can match the language $\emptyset$, and the singleton languages for $\varepsilon$ and each symbol $a \in \Sigma$. The languages matched by regular expressions are also closed under union, concatenation, and star, since by definition, these are the only operations used in regular expressions. So the regular languages are contained in the class of languages matched by regular expressions.
Now, consider an arbitrary regular expression $\mathbf r$. We will show that $L(\mathbf r)$ is a regular language by induction on $\mathbf r$.
For our base cases, we have $\mathbf r = \varnothing, \epsilon, \mathtt a$ for $a \in \Sigma$. We have $L(\mathbf r) = \emptyset, \{\varepsilon\}, \{a\}$, respectively, which are all regular by definition.
Now, let $\mathbf r_1$ and $\mathbf r_2$ be regular expressions. We assume that $L(\mathbf r_1)$ and $L(\mathbf r_2)$ are regular languages. Then
So each the language matched by any regular expression is a regular language. Therefore, the class of languages matched by regular expressions is contained in the class of regular languages.
Therefore, the class of regular languages is exactly the class of languages matched by regular expressions.
Again, this is possibly a bit fussy. Indeed, in many textbooks, the definition of the regular languages is either just inductive with the same form as the regular expressions, or simply “the languages that are described by regular expressions”. But we can consider some of the reasons why these definitions can be unsatisfying.
Although it seems like regular languages are just the languages that can be described using regular expressions, the reality is that regular expressions are a formalism that were derived in order to describe the regular languages. So we really should be describing these things in terms of the operations.
Then why don’t we simply define the regular languages inductively to begin with? Technically speaking, it’s not the languages themselves that are necesarily inductive but rather a particular construction or description. So we can’t really inductively define languages, but we can inductively define a particular way of constructing them. These correspond to regular expressions.
Regular expressions are a way for us to use the idea of regular operations to describe languages algebraically, both informally and formally. By informal, I simply mean that regular expressions “look like math” and that they work kind of how you might expect algebra to work intuitively.
This is not a coincidence, because regular expressions really are algebraic in the formal sense. The regular expressions form what is called a semiring. A semiring is a set equipped with two operations, which we refer to as “addition” and “multiplication” with the condition that both addition and multiplication have identity elements. The regular expressions are a semiring because we take union to be addition with the identity element $\varnothing$ (i.e. $\mathbf r + \varnothing = \mathbf r$) and concatenation as multiplication with the identity element $\epsilon$ (i.e. $\mathbf r \cdot \epsilon = \mathbf r$).
So if these are semirings, then what makes a ring? It is the requirement that every element has an additive inverse, i.e. for all $n$, there exists an element $-n$ such that $n + (-n) = 0$. An example of a ring that we are all familiar with is the integers. Now, notice that the additive inverse is missing for regular expressions: there’s no inverse for union.
Why does this matter? As with finite automata, one language can have multiple representations or descriptions. And since regular expressions form a semiring, this means that many of the algebraic identities we might be used to from arithmetic also apply to them.
Two regular expressions $\mathbf r$ and $\mathbf s$ over $\Sigma$ are equivalent if they describe the same language. That is, $\mathbf r \equiv \mathbf s$ if $L(\mathbf r) = L(\mathbf s)$.
This is the same kind of idea that you may have seen with logical equivalence—two logical formulas are said to be equivalent because they mean the same thing but we don’t say they’re equal because they are not literally the same.
Here are some basic identities for regular expressions. We let $\mathbf r, \mathbf s, \mathbf t$ be regular expressions over $\Sigma$.
| Property | Definition |
|---|---|
| Additive identity | $\mathbf r + \varnothing \equiv \varnothing + \mathbf r \equiv \mathbf r$ |
| Multiplicative identity | $\mathbf r \epsilon \equiv \epsilon \mathbf r \equiv \mathbf r$ |
| Absorption | $\mathbf r \varnothing \equiv \varnothing \mathbf r \equiv \varnothing$ |
| Associativity of addition | $(\mathbf r + \mathbf s) + \mathbf t \equiv \mathbf r + (\mathbf s + \mathbf t)$ |
| Associativity of multiplication | $(\mathbf r \mathbf s) \mathbf t \equiv \mathbf r (\mathbf s \mathbf t)$ |
| Distributivity | $\mathbf r (\mathbf s + \mathbf t) \equiv \mathbf r \mathbf s + \mathbf r \mathbf t$ |
| Commutativity of addition | $\mathbf r + \mathbf s \equiv \mathbf s + \mathbf r$ |
| Cyclicity | $\mathbf r^* \equiv \epsilon + \mathbf r \mathbf r^* \equiv \epsilon + \mathbf r^* \mathbf r$ |
The only “new” identity here that you wouldn’t guess from arithmetic is cyclicity, which involves the Kleene star. All other identities follow from regular expressions forming a semiring.
Here are a few more examples of some regular expressions and the languages they describe.
Let’s walk through an example of constructing a regular expression for a language. We’ll see that this is relatively informal compared to defining a finite automaton. Consider the language $L$, \[L = \{w \in \{a,b\}^* \mid \text{all substrings $aa$ appear before every substring $bb$ in $w$}\}.\] We will show that $L$ is regular by constructing a regular expression that matches it. One way to think about such a string is to think of it as two strings $u$ and $v$, where $u$ contains substrings of the form $aa$ but not $bb$ and $v$ contains substrings of the form $bb$ but not $aa$. So we will define subexpressions that describe the possible strings for $u$ and for $v$.
To describe a string that contains substrings of the form $aa$ but not $bb$, it is easiest to think of such a string as avoiding the substring $bb$. This means that every occurence of $b$ in such a string cannot be adjacent to another $b$. To ensure this, the only time we should ever allow a $b$ is if it is immediately preceded or followed by an $a$.
So let $\mathbf s = \mathtt{(a+ba)^*}$. This describes strings made up of two “pieces”: $a$’s and $ba$’s. This way, the only way a $b$ can be present in a string is if it is separated by $a$’s. We only need to pair the $b$ with one $a$ since the pieces ensure that any symbol that follows a $b$ is an $a$.
Then strings that contain $bb$ but not $aa$ are basically symmetric. We let $\mathbf t = \mathtt{(b+ba)^*}$. Then an expression for $L$ is $\mathbf r = \mathbf{st} = \mathtt{(a+ba)^*(b+ba)^*}$.
A few students pointed out that the order of the term $ba$ is important—if $ab$ is used in either grouping, then some strings will be incorrectly excluded. In the front, using $ab$ instead of $ba$ excludes any string that starts with a single $b$, and if used in the back, strings ending with a single $a$ will be incorrectly excluded.
The term regular expression may sounds familiar to many of you, particularly if you’ve ever needed to do a bunch of pattern matching. And your guess is correct: these are (mostly) the same thing. For the most part, the regular expressions as used in Unix and various programming languages are based on our theoretically defined regular expressions. This leads to a few points of interest.
The first is that this implies a non-theoretical application for all of the stuff that we’ve been doing so far: pattern matching. If you want to search for some text, or more generally a pattern, then regular expressions are your tool of choice. But, and I hinted at this earlier, regular expressions are for us to read, while the computer turns it into a finite automaton and uses that for text processing.
Now, that may have been obvious because the name gave it away. However, there’s a second classical application of regular languages that is similar: lexical analysis. Lexical analysis is the phase of the compiler that is responsible for breaking up strings of symbols into a sequence of tokens (which is why this is also sometimes called tokenization).
Tokens are discrete units that have some meaning. For instance, the string
if ( x > 2 ) {could be tokenized as a sequence
[(KEYWORD, "if"), (SEPARATOR, "("), (IDENTIFIER, "x"), (OPERATOR, ">"), (LITERAL, "2"), (SEPARATOR, ")"), (SEPARATOR, "{")]Now, what’s important to keep in mind is that tokenization only gives meaning to the parts of the string, but it doesn’t check whether the sequence of tokens actually makes “grammatical” sense. This is a sign of things to come.
Of course, there’s an obvious analogy to natural language. In computational linguistics, regular languages provide a simple first approach to tokenizing natural language sentences, by identifying discrete words and possibly the kinds of words (nouns, verbs, etc.) they are. Again, such processing only attempts to provide meanings to chunks of strings, but doesn’t enforce any particular rules about how these chunks should be arranged.
A surprising fact about regular languages and recognizable languages is that they happen to be exactly the same class of languages. At first glance, there’s no obvious reason why this should be the case. After all, finite automata and regular expressions are totally different formalisms that have different origins and no obvious connection.
However, Kleene showed exactly this: every regular expression could be transformed into an equivalent finite automaton and every finite automaton could be transformed into an equivalent regular expression.
We will tackle how to construct a finite automaton given a regular expression first. This turns out to be rather straightforward because we have actually done most of the work already.
Let $L$ be a regular language. Then there exists a NFA $A$ with $L(A) = L$.
Since $L$ is regular, there is a regular expression $\mathbf r$ with $L = L(\mathbf r)$. We will show that we can construct an NFA $A$ such that $L(A) = L(\mathbf r)$ by induction on $\mathbf r$.
First, for our base cases, we can construct the following NFAs for $\mathbf r = \varnothing$, $\epsilon$, and $\mathtt a$ for each $a \in \Sigma$:

Since these are pretty simple, we won’t formally prove that they’re correct, but you can try on your own if you wish.
Now, we consider the inductive case. For our inductive hypothesis, we let $\mathbf s$ and $\mathbf t$ be regular expressions and assume there exist NFAs $A$ and $B$ such that $L(A) = L(\mathbf s)$ and $L(B) = L(\mathbf t)$.
Luckily, we’ve done a lot of the work up to this point.
Therefore, we can construct a NFA that accepts any language that is matched by an arbitrary regular expression $\mathbf r$.
A more specific concrete algorithm version of this proof is due to Ken Thompson in 1968 and is most commonly called the Thompson construction. Thompson, was one of the early figures working on Unix and was, among other things, responsible for the inclusion of regular expressions in a lot of early Unix software like ed, making regexes ubiquitous among programmers. More recent work of his you may be familiar with include UTF-8 and the Go programming language.
How do we get an algorithm from this proof? Basically, if we replaced the claim that “there exists an NFA because the recognizable languages are closed under this operation” with the specific construction, like from the proofs before, then we can use those constructions to to build the desired NFA.
Consider regular expression $\mathbf r = \mathtt{(0+1)^* 000 (0+1)^*}$, which matches all binary strings that contain $000$ as a substring. To construct an NFA based on the Thompson construction, we begin with our basic NFAs for $0$ and $1$.
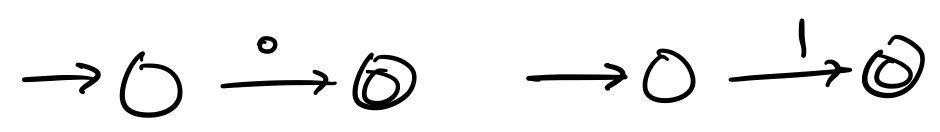
Then, we use these in the other constructions. For instance, we can construct the union, followed by the star.
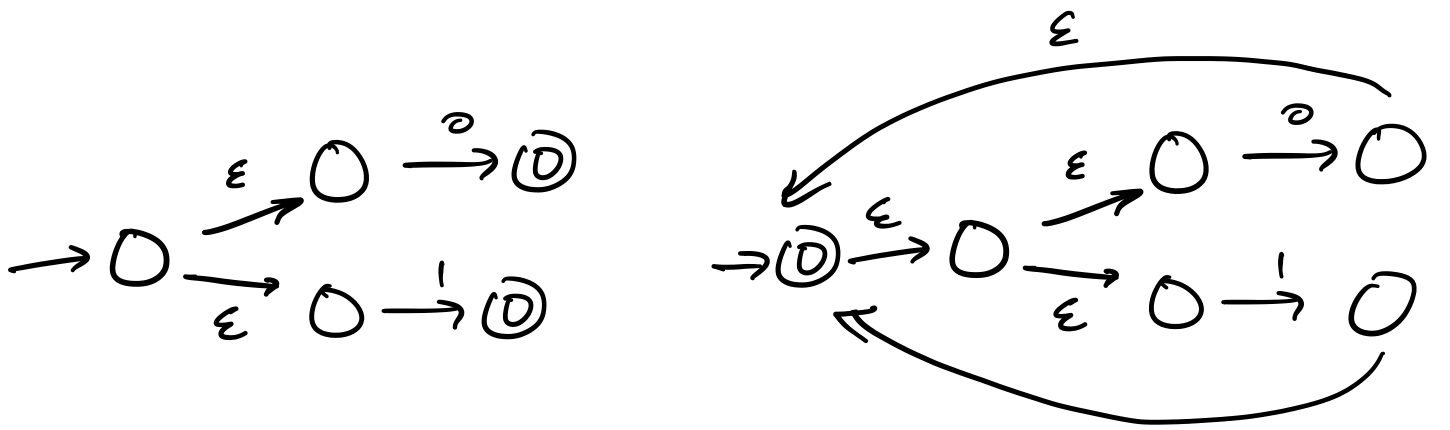
Then we can perform our concatenations.
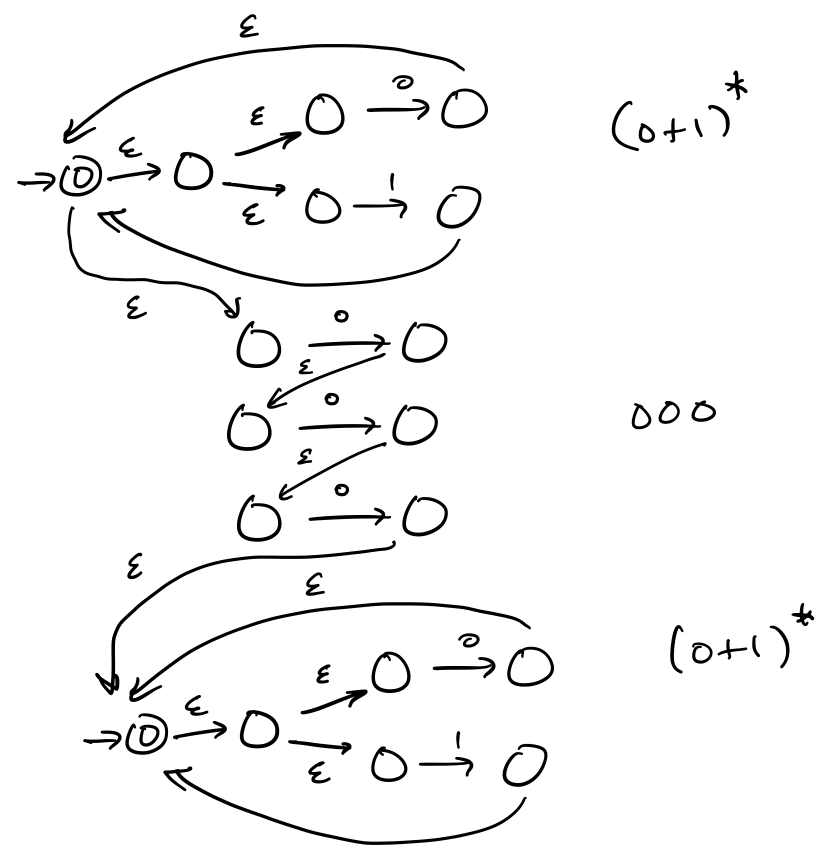
Observe that this machine is quite large and you can already see some states and transitions that are superfluous. Or, put another way, you probably could’ve come up with a smaller machine right at the start just by thinking about it for maybe half a minute.
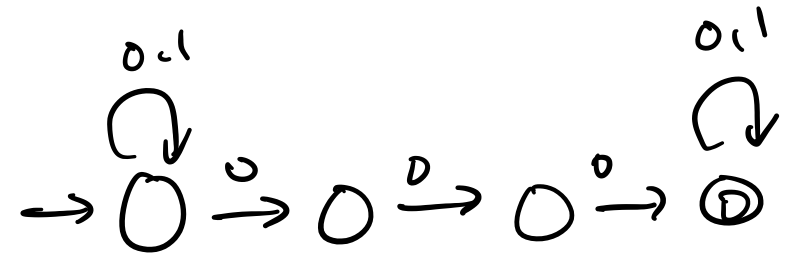
Despite this, we can observe that for a regular expression of length $n$, the Thompson construction gives us an NFA that has $O(n)$ states. To see this, we notice that each case of the construction only adds one or two states. Since each case corresponds to an atomic expression or an operation, we can see that each character in the expression is responsible for one or two states (we can also try to prove this formally).
The main downside of the Thompson construction is the use of $\varepsilon$-transitions. There are a number of algorithms that transform regular expressions without $\varepsilon$-transitions and still result in roughly $O(n)$ states.