Rabin and Scott use the product construction to show that it actually allows us to represent the result of any boolean set operation, simply by defining the appropriate set of final states. So the question of closure under boolean set operations is settled: the recognizable languages are closed under all of them. But languages are not just arbitrary sets, they are sets of strings. This means that we can define other kinds of language operations and ask the same questions about closure for recognizable languages.
Here are some examples of string and language operations.
- Overlap catenation. For two words $x,y \in \Sigma^*$,
$$x \overline \odot y = \{uwv \mid x = uw, y = wv, u,v,w \in \Sigma^*\}.$$
- Proportional removal. For a word $w \in \Sigma^*$, define $\frac 1 2 w$ to be the first half of $w$. That is, $\frac 1 2 w = x$ for $w = xy$ with $|x| = |y|$.
- Neighbourhoods. Say you have a distance measure on strings $d : \Sigma^* \times \Sigma^* \to \mathbb R$, like the edit distance. Then the neighbourhood of a word $w$ with respect to $d$ of radius $r$ is the set of strings, that are within a distance of $r$ to $w$,
$$N_d^{(r)}(w) = \{x \in \Sigma^* \mid d(w,x) \leq r\}.$$
For now, let’s consider the most basic string operation: concatenation. Is it always possible, given two DFAs, to construct a DFA that recognizes the concatenation of their languages? We can imagine that if we wanted to recognize a word $uv$, where $u \in L_1$ and $v \in L_2$, what we would want to do is check that $u$ is accepted by the DFA $A_1$ for $L_1$ and $v$ is accepted by the DFA $A_2$ for $L_2$. Then rather than running the two machines in parallel, we’d run them one after the other.
There is a problem with this approach: when we give a DFA a word $uv$, we don’t actually know where $u$ ends and $v$ begins. One idea to fix this would be to test whether a state was a final state in $A_1$, but this only gets us so far.
Let $L_1 = \{a^n \mid n \geq 1\}$ and $L_2 = \{aab\}$. These are both recognizable. The following is a DFA for $L_1$.
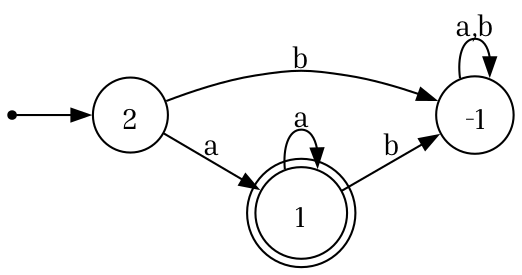
And the following is a DFA for $L_2$.
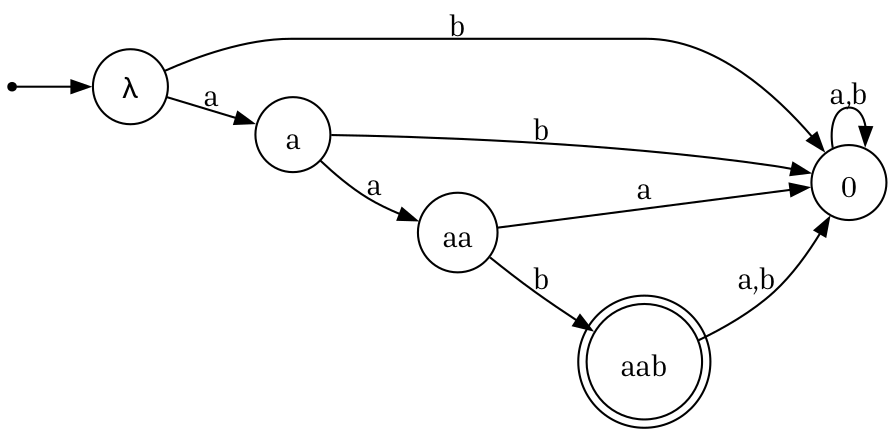
Suppose we try to build a machine that, whenever a final state of $A_1$ is entered, we “jump” to $A_2$ and continue the computation. For example, consider the string $aaab$. A hypothetical path through such a machine might look like
Now, consider a string $aaaab$. We can view this as the concatenation of the strings $aa$, which is accepted by $A_1$, and $aab$, which is accepted by $A_2$. However, we find that this string would not get accepted by our hypothetical machine.
What happened? More generally, we have a word $uvw$, where $u, uv \in L_1$ and $w \in L_2$ but $vw \not \in L_2$. In this case, our DFA could see that $u$ brings us to a final state of $A_1$ and start processing $vw$ on $A_2$, only to reject $vw$.
The big problem is that transitions in DFAs have to be uniquely determined, but we can’t go back and try something else. In other words, we have to know exactly where we’re going. And so, we seem to be hitting our first roadblock.
Nondeterminism
As DFAs are currently defined (and so named) the transition function $\delta$ is deterministic. That is, the next state is uniquely determined by the current state and input symbol, or there is exactly one state that the transition function points to. This keeps things simple for us and it accurately reflects how real computers work. However, it does seem like a bit of a stifling restriction and sometimes there are a few points where it’d be so much easier just to be able to go to multiple states.
Here, we’ll relax the condition that the transition function is deterministic by introducing nondeterminism to finite automata. We call these machines nondeterministic finite automata for obvious reasons. Informally, this means that in an NFA, for each state and transition symbol, we’ll allow transitions to multiple states.
The following is an example of an NFA, which accepts the language $\{a,b\}^* b \{a,b\}^2$. Note that on $q_0$, there are two transitions on $b$: one to $q_0$ and one to $q_1$.
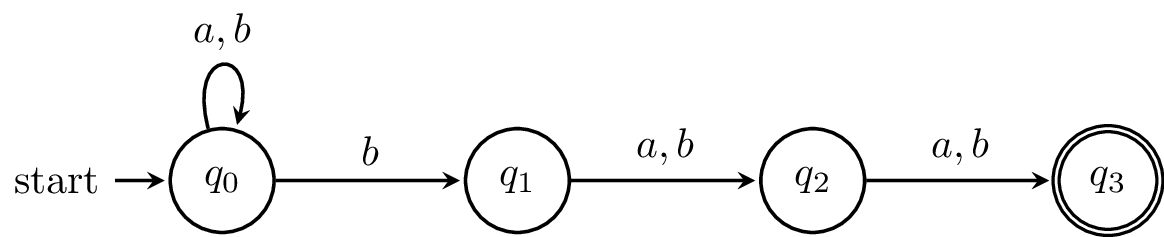
Conceptually, what does this mean? In essence, the NFA can “guess” which transition to take. While with a DFA we could represent a computation on an input word with a single path, with nondeterminism, there are multiple paths which we can represent as a tree, with branches forming at the points where there are choices to be made.
But if there are multiple possible paths, how do we define acceptance under this model? If there is at least one path which, after reading the input word, reaches an accepting state, then the NFA accepts the word. This fits with the idea that the NFA makes guesses whenever it has a choice; the existence of a path that reaches a final state means that there is a set of guesses that the NFA could make in order for the word to be accepted. Conversely, the NFA rejects $w$ if there are no paths which reach a final state upon reading $w$.
Let’s formalize what an NFA is.
A nondeterministic finite automaton (NFA) is a 5-tuple $A = (Q,\Sigma,\delta,I,F)$, where
- $Q$ is a finite set of states,
- $\Sigma$ is an alphabet,
- $\delta$ is a transition function $\delta : Q \times \Sigma \to 2^Q$,
- $q_0$ is an initial state,
- $F$ is a set of final states.
This looks basically the same as the DFA, except for one important difference: the transition function $\delta$ is now a function from a state and a symbol to a set of states. This explains why we don’t require that $\delta$ is defined explicitly for all states and symbols. Since the image of $\delta$ is sets of $Q$, we implicitly define “missing” transitions as going to the empty set $\emptyset$.
If you are following along in Kozen, this is a point where our definition diverges from his. Kozen defines NFAs to have a set of initial states, while we retain a single initial state in our model. It will turn out that this change doesn’t really matter—the two models are the same. It makes for a nice exercise to try to prove this.
Here is our NFA from above, which we claim accepts all strings with a $b$ in the third-to-last position.
\begin{tikzpicture}[node distance=2.5cm,thick,auto]
\node[state,initial] (0) {$q_0$};
\node[state] (1) [right of=0]{$q_1$};
\node[state] (2) [right of=1]{$q_2$};
\node[state,accepting] (3) [right of=2]{$q_3$};
\path[->]
(0) edge [loop above] node {$a,b$} (0)
(0) edge node {$b$} (1)
(1) edge node {$a,b$} (2)
(2) edge node {$a,b$} (3)
;
\end{tikzpicture}
The formal definition of this NFA would be $A = (Q,\Sigma,\delta,q_0,F)$ where
- $Q = \{q_0, q_1, q_2, q_3\}$,
- $\Sigma = \{a,b\}$,
- $q_0 = q_0$,
- $F = \{q_3\}$,
and the transition function $\delta$ is defined by
| $a$ | $b$
|
|---|
| $q_0$ | $\{q_0\}$ | $\{q_0, q_1\}$
|
| $q_1$ | $\{q_2\}$ | $\{q_2\}$
|
| $q_2$ | $\{q_3\}$ | $\{q_3\}$
|
| $q_3$ | $\emptyset$ | $\emptyset$
|
from automata.fa.nfa import NFA
A = NFA(
states={f'q{i}' for i in range(4)},
input_symbols=set('ab'),
transitions={
'q0': {'a': {'q0'}, 'b': {'q0', 'q1'}},
'q1': {'a': {'q2'}, 'b': {'q2'}},
'q2': {'a': {'q3'}, 'b': {'q3'}},
'q3': {}
},
initial_state='q0',
final_states={'q3'}
)
Observe that the transition function maps a state and symbol pair to a set of states.
One way to think about nondeterminism is to think of every nondeterministic transition as a possible choice. For instance, if we’re in $q_0$ and we see a $b$, our choice is between staying in $q_0$ or going to $q_1$. We would not have such a choice in a determinstic machine. What does this look like for an entire computation moving through the machine?
Consider the following run of $A$ on the input string $abbab$.
>>> list(A.read_input_stepwise("abbab"))
[frozenset({'q0'}),
frozenset({'q0'}),
frozenset({'q0', 'q1'}),
frozenset({'q0', 'q1', 'q2'}),
frozenset({'q0', 'q2', 'q3'}),
frozenset({'q0', 'q1', 'q3'})]
Notice again that, as defined, the “state” of the machine is represented as a set of states. We think of our machine as being in each of the states simultaneously.
- Reading the first $a$ takes us back to $q_0$, since that is the only transition we can take.
- However, on reading the first $b$, we have two states: $q_0$ and $q_1$. So our machine is “in” both those states at the same time.
- From this point on, we have to apply transitions to each state in the set. So reading the next $b$, we have that $q_0 \rightarrow \{q_0, q_1\}$ and $q_1 \rightarrow \{q_2\}$, which gives us $\{q_0, q_1, q_2 \}$.
- The next symbol that is read is $a$, which results in the set $\{q_0, q_2, q_3\}$, since $q_1$ does not have an incoming transition on $a$.
- After reading the final $b$, we are in the three states $\{q_0, q_1, q_3\}$.
Based on this run, should the string $abbab$ be accepted? It satisfies the criteria by having a $b$ in the third-to-last position, so it seems like it should. So let’s think about the acceptance criteria for this model.
In order to define this, we will need to extend our transition function, but this time we will do so in two ways. First, we’ll do the same thing we did for DFAs, which is to extend $\delta$ to a function $\delta^*$ on states and strings.
The function $\delta^*: Q \times \Sigma^* \to 2^Q$ is defined by
- $\delta^*(q,\varepsilon) = \{q\}$, and
- for $w = xa$ with $x \in \Sigma^*$ and $a \in \Sigma$, we have
$$ \delta^*(q,xa) = \bigcup_{p \in \delta^*(q,x)} \delta(p,a).$$
Notice how this definition takes into account that the output of $\delta$ is a set of states. As usual, we drop the star when the context is clear that we’re working with strings.
The other extension we’ll make is more of a convenience (or an abuse of notation) by treating $\delta$ as a function on subsets of states $\delta: 2^Q \times \Sigma^* \to 2^Q$. To do this, we take for $P \subseteq Q$,
$$\delta(P,a) = \bigcup_{q \in P} \delta(q,a)$$
when the context is clear.
Let’s take a moment to see how this definition fits with our intution about how nondeterminism behaves. It is easy to see that by taking the union of these sets, we really do get all possible transitions. However, note that this definition also handles transitions that are missing: if $\delta(p,a) = \emptyset$, then for any set $S$, we have $S \cup \emptyset = S$, and so $\delta^*$ remains well-defined.
Now, we can define acceptance under the nondeterministic model.
We say that an NFA $A$ accepts a word $w$ if $\delta^*(q_0,w) \cap F \neq \emptyset$. Then the language of an NFA $A = (Q,\Sigma,\delta,q_0,F)$ is defined by
$$ L(A) = \left\{w \in \Sigma^* \mid \delta^*(q_0,w) \cap F \neq \emptyset \right\}.$$
What does this definition say? For DFAs, acceptance is defined as the machine being in a final state at the moment we finish reading our input string. For NFAs, we will be in multiple possible states when we finish reading our string. This definition of acceptance says that as long as there is a final state among these states, the NFA accepts the string.
If we think of nondeterministic transitions as a choice, then a nondeterministic machine explores all possible choices we could have made. The resulting set of states that we end up with is the outcome of some sequence of choices that were made throughout the computation of the machine. One way to interpret what the acceptance condition is saying is that as long as there is at least one sequence of choices (i.e. existence) that we can make so that we’re in a final state, then our string is accepted. Rather than a single path through our machine, we can think of a computation on a nondeterministic machine as a tree.
Another way to interpret nondeterministic choices is rather than making a choice, we’re really making a guess: we don’t know which of the choices we make are the right ones. But as long as there is some choice that works, then we can guess at each step and come up with a valid accepting computation.
So the outcomes for an NFA can be interpreted in the following way:
- A string is accepted if there is at least one set of choices that results in an accepting computaiton.
- A string is rejected if there is no set of choices that results in an accepting computaiton. Equivalently, every possible set of choices is rejecting.
The ability to guess is exactly what we need in order to solve the concatenation problem: with a deterministic machine, our problem was we didn’t know when to make the jump from the first part of the string to the second part of the string. Without the ability to double back and re-read the front of the string, we need to be able to guess when the “break” happens.
Let $L_1$ and $L_2$ be recognizable languages. Then there exists an NFA that accepts $L_1L_2$.
Since $L_1$ and $L_2$ are recognizable, suppose they are recognized by the DFAs $A_1 = (Q_1, \Sigma, \delta_1, q_{0,1}, F_1)$ and $A_2 = (Q_2, \Sigma, \delta_2, q_{0,2}, F_2)$, respectively. We will construct an NFA $A' = (Q',\Sigma, \delta', q_0', F')$ to recognize $L_1 L_2$. We define
- $Q' = Q_1 \cup Q_2$,
- $q_0' = q_{0,1}$,
- $F' = F_2$,
and the transition function $\delta':(Q_1 \cup Q_2) \times (\Sigma \cup \{\varepsilon\}) \rightarrow 2^{Q_1 \cup Q_2}$ is defined
- for $q \in Q_1$ and $a \in \Sigma$,
\[\delta'(q,a) = \begin{cases}
\{\delta_1(q,a)\} & \text{if $\delta_1(q,a) \not \in F$,} \\
\{\delta_1(q,a), q_{0,2}\} & \text{if $\delta_1(q,a) \in F$,}
\end{cases}\]
and
- $\delta'(q,a) = \{\delta_2(q,a)\}$ for $q \in Q_2$ and $a \in \Sigma$.
What does this NFA do? We begin by reading our string on $A_1$. Then, whenever the machine enters a final state of $A_1$, it simultaneously enters the initial state of $A_2$. In this way, we nondeterministically “guess” that we start the second part of the string. Then this construction hinges on the observation that we can only make it into the automaton $A_2$ if we enter a final state of $A_1$.
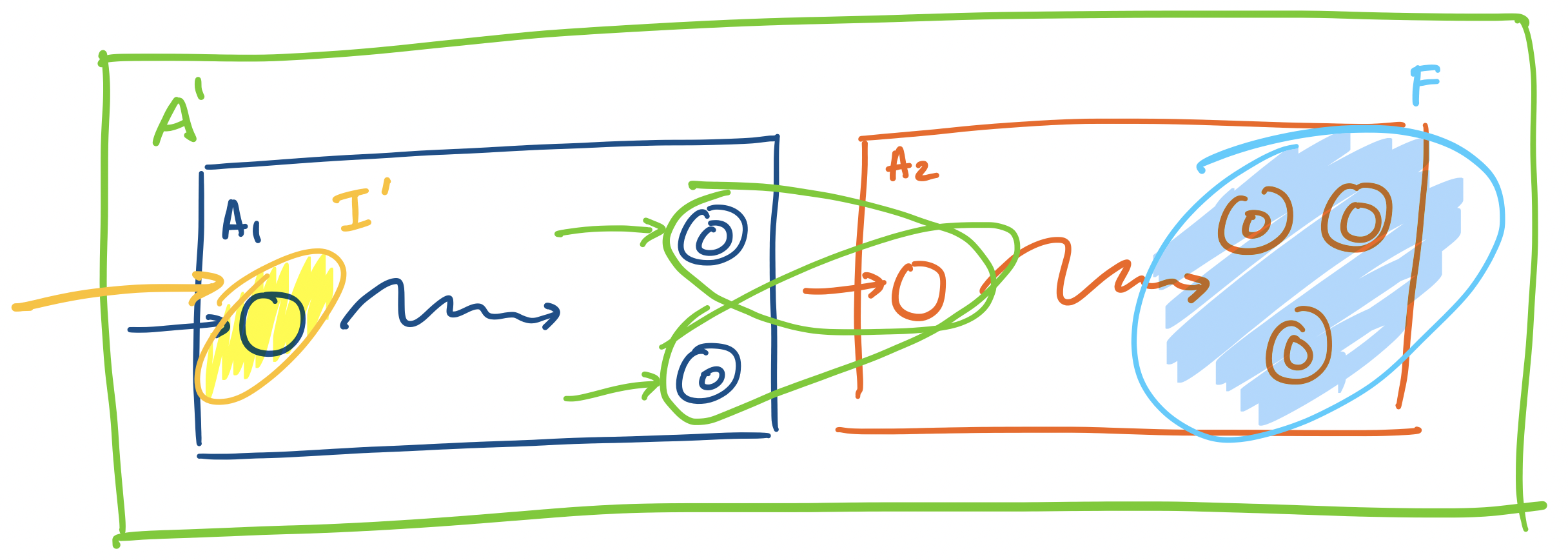
Consider a word $w \in \Sigma^*$ that’s accepted by $A'$—that is $w \in L(A')$. Then $\delta'(q_{0,1}, w) \cap F_2 \neq \emptyset$. So we can split the word up into two words $w = xy$. Since the only entry point into $A_2$ is $q_{0,2}$, we have that $\delta_2(q_{0,2},y) \in F_2$. But in order for $q_{0,2}$ to be reached, there had to be some word $x$ such that $\delta_1(q_{0,1},x) \in F_1$. Our computation path looks like
\begin{align*}
q_{0,1} \xrightarrow{x} p \in & F_1, \\& \Downarrow \\ & q_{0,2} \xrightarrow{y} q \in F_2
\end{align*}
This gives us our two words $x \in L(A_1)$ and $y \in L(A_2)$ and therefore $w = xy \in L_1L_2$.
Now, suppose that $w \in L_1L_2$. This means that $w = uv$ where $u \in L_1$ and $v \in L_2$, and since these languages are both accepted by their respective DFAs, we have $u \in L(A_1)$ and $v \in L(A_2)$. So $\delta_1(q_{0,1}, w) = q \in F_1$ and $\delta_2(q_{0,2}, v) = q' \in F_2$. Then in $A'$, we have $\{q, q_{0,2}\} \subseteq \delta'(q_{0,1}, u)$. We then have $\delta'(\{q,q_{0,2}\}, v) \subseteq \delta'(q_{0,1}, uv)$ and therefore $\delta'(q_{0,1}, uv) \cap F_2 \neq \emptyset$.
\begin{align*}
q_{0,1} \xrightarrow{u} q \in & F_1, \\ &\Downarrow \\ & q_{0,2} \xrightarrow{v} q' \in F_2
\end{align*}
So $w = uv \in L(A')$.