We want to build a DFA that recognizes the language $$ L_{\div 3} = \{w \in \{0,1\}^* \mid 3 \mid \llparen w \rrparen_2\}.$$
Let $A = (Q,\Sigma,\delta,q_0,F)$, where
| $0$ | $1$ | |
|---|---|---|
| $0$ | $0$ | $1$ |
| $1$ | $2$ | $0$ |
| $2$ | $1$ | $2$ |
The state diagram for $A$ is shown below.
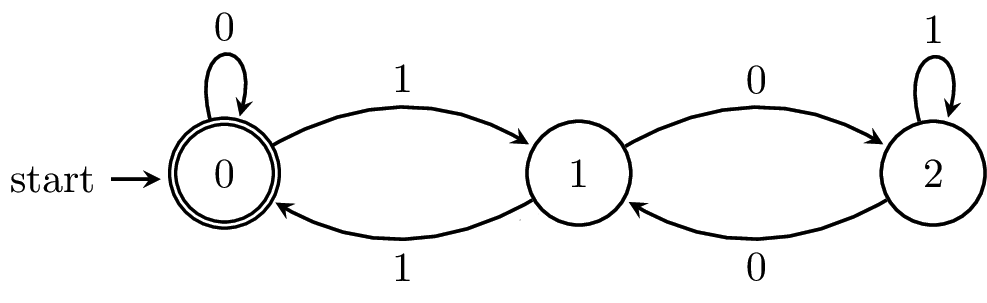
\begin{tikzpicture}[node distance=2.5cm,thick,auto]
\node[state,initial,accepting] (0) {$0$};
\node[state] (1) [right of=0]{$1$};
\node[state] (2) [right of=1]{$2$};
\path[->]
(0) edge [loop above] node {$0$} (1)
(0) edge [bend left] node {$1$} (1)
(1) edge [bend left] node {$1$} (0)
(1) edge [bend left] node {$0$} (2)
(2) edge [bend left] node {$0$} (1)
(2) edge [loop above] node {$1$} (2)
;
\end{tikzpicture}
from automata.fa.dfa import DFA
A = DFA(
states=set(range(3)),
input_symbols=set('01'),
transitions={
0: {'0': 0, '1': 1},
1: {'0': 2, '1': 0},
2: {'0': 1, '1': 2},
},
initial_state=0,
final_states={0}
)
What does it mean to prove that our DFA is correct? If we think of it as an algorithm, this is akin to showing that
This means there are two steps in every formal proof of correctness for a DFA:
Let’s begin with the first step, which is to show that our machine places each string in the “correct” state.
For all strings $w \in \{0,1\}^*$ and states $q \in \{0,1,2\}$, $\delta^*(0,w) = q$ if and only if $\llparen w \rrparen_2 = q \bmod 3$.
Let $\llparen w \rrparen_2$ denote the integer represented by the binary string $w$. We will show this by induction on $w$.
Our base case is $w = \varepsilon$. Then $\delta^*(0,\varepsilon) = 0$ by definition and we have $\llparen \varepsilon \rrparen_2 = 0 = 0 \bmod 3$.
Now let $w = xa$, with $a \in \Sigma$ and $x \in \Sigma^*$. We assume $\delta^*(0,x) = i$ if and only if $\llparen x \rrparen_2 = i \bmod 3$. We have \begin{align*} \delta^*(0,xa) &= \delta(\delta^*(0,x),a) &\text{Definition of $\delta^*$} \\ &= \delta(\llparen x \rrparen_2 \bmod 3, a) &\text{Inductive hypothesis} \\ &= (2 \cdot (\llparen x \rrparen_2 \bmod 3) +a) \bmod 3 &\text{Definition of $\delta$}\\ &= (2 \cdot \llparen x \rrparen_2 + a) \bmod 3 &\text{Reduction in $\mathbb Z_3$}\\ &= \llparen xa \rrparen_2 \bmod 3 &\text{Definition of $\llparen \cdot \rrparen_2$} \end{align*}
Thus, we have shown that $\delta^*(q_0,w) = i$ if and only if $\llparen w \rrparen_2 = i \bmod 3$.
Having proved that the meanings of each state is correct, we are now able to argue that the set of strings accepted by our machine is exactly the language we wanted to recognize.
$L_{\div 3} = L(A)$.
To argue that $L_{\div 3} = L(A)$, we observe that \begin{align*} w \in L_{\div 3} &\iff 3 \mid \llparen w \rrparen_2 & \text{Definition of $L$}\\ &\iff \llparen w \rrparen_2 = 0 \bmod 3 & \text{Definition of congruence}\\ &\iff \delta^*(q_0, w) = 0 &\text{Lemma}\\ &\iff w \in L(A) &\text{Definition of $F$} \end{align*} Therefore, we can conclude that $A$ accepts $w$ if and only if $\llparen w \rrparen_2$ is divisible by 3.
It’s important to note the structure of the argument that was made here. In order to prove that our DFA accepted the correct language, we need to show that it accepts only the strings in the target language. That is, the DFA must accept the strings in $L$ and it must reject the string not in $L$.
In order to argue this, we must argue that every string reaches the “correct” state in the DFA. This is the most common mistake that is made in these proofs—you cannot prove that $L = L(A)$ by induction on strings in $L$.
Once you have successfully shown that every string reaches the correct state, we finish the proof by arguing that a string is in $L$ if and only if it reaches a final state. This should be relatively straightforward at this point.
From this, one might ask whether it’s possible to construct a DFA that recognizes all of the binary strings that represent integers that are divisible by $n$ for any arbitrary integer $n$. The answer is yes, and it’s not hard to see why. There are only finitely many equivalence classes modulo $n$ (or rather, exactly $n$) and all we need to do is keep track of how this number changes with each additional symbol read. You can even take this approach and make it work for strings representing integers in any base $k$.
This captures the kinds of problems that finite automata can solve. The key property of finite automata is that they can only keep track of a finite amount of information. This information doesn’t scale with the size of the input—even with a finite amount of information, we’re able to describe an infinite set like the integers modulo 3. In the language of complexity theory, these are problems that have space complexity $O(1)$. What kinds of problems can we solve with only a finite amount of information?
Recall that languages are just sets of words and that we can perform set operations on languages. However, once we start thinking about computation, particularly with our simple model of computation, an important question is whether the resulting language that we get from applying these operations is still computable.
What does applying these operations allow us to do? Consider the boolean set operations. If we took one of the problems we’ve seen, like divisibility by 3 or searching for a substring, we can use the boolean set operations to express natural followup questions:
What is not necessarily clear is how these operations and transformations may change the complexity of the underlying language. For instance, if we have a language that we know is solvable using a DFA, is it always the case that we can always find a DFA that will accept its complement?
This question leads to what are called closure properties of classes of languages. This is the question of whether a language class is “closed” under a particular operation. Here is a formal definition.
We say that a class of languages is closed under an operation if whenever the arguments of the operation are in the class, the result is also.
Consider the class of finite languages. These are all languages that have finite cardinality. Observe that the class of finite languages are closed under union. Why? The union of two finite sets is also finite.
On the other hand, the finite languages are not closed under complement. Let $\Sigma = \{a,b\}$ and let $L = \{a,b,ab\}$. The language $L$ is clearly finite. Then the complement of $L$ is all strings over $\{a,b\}$ that are not $a$, $b$, or $ab$. There are infinitely many such strings, so $\overline L$ is not finite and not in the class of finite languages.
Let’s consider the class of recognizable languages (i.e. those that are accepted by DFAs). Since languages are decision problems, we can also view this as the class of all decision problems that can be solved by DFAs. If we want to show that the recognizable languages are closed under a particular operation, we have to show that the result of the operation can be recognized by a DFA. The most straightforward way of doing this is to take the input DFAs and use them to construct a DFA for the result—an algorithm.
First, let’s do a simple, but very useful, example.
The recognizable languages are closed under complement.
Let $L \subseteq \Sigma^*$ be a recognizable language. Let the DFA $A = (Q,\Sigma^*,\delta,q_0,F)$ be a DFA that accepts $L$. We will construct a DFA $A’$ that recognizes $\overline L$, the complement of $L$, as follows: let $A’ = (Q,\Sigma,\delta,q_0,Q \setminus F)$.
In other words, we take the DFA $A$ and swap the set of non-final and final states. Then we have for all strings $w \in \Sigma^*$, \begin{align*} w \in L(A') &\iff \delta(q_0,w) \in Q \setminus F \\ &\iff w \not \in L(A) \\ &\iff w \not \in L \\ &\iff w \in \overline L \end{align*}
The idea that this is an algorithm becomes even more stark if we render it as a program.
def complement(A: DFA) -> DFA:
return DFA(
states=A.states,
input_symbols=A.input_symbols,
transitions=A.transitions,
initial_state=A.initial_state,
final_states=(A.states - A.final_states)
)
If we think back to languages as decision problems, then this gives us a handy way to solve the complement of some problems. For instance, we now have a very easy way to determine whether a number isn’t divisible by 3. That is, the complement of a language is really the same as asking for the negation of the respective decision problem.
Obviously, we are very interested in the closure properties for the basic set operations (union, intersection, complement) and the basic string operations (concatenation, Kleene star). These give us ways to combine and solve problems that we already know how to solve. First, let’s consider the intersection.
Suppose we have two recognizable languages, $L_1$ and $L_2$. Then we know that they can be recognized by some DFAs, say $A_1$ and $A_2$, respectively. By definition, if $w \in L_1 \cap L_2$, then this means $w \in L_1$ and $w \in L_2$. Hypothetically, all we need to do is run $A_1$ on $w$ and run $A_2$ on $w$ and see if it’s accepted by both. This idea of running two machines in parallel leads us to the product construction.
Consider DFAs $A_1 = (Q_1, \Sigma, \delta_1, q_{0,1}, F_1)$ and $A_2 = (Q_2, \Sigma, \delta_2, q_{0,2}, F_2)$. Then the product automaton of $A_1$ and $A_2$ is the DFA $A' = (Q',\Sigma,\delta',q_0',F')$, where
In the product automaton, every state is a pair of states, with one from $A_1$ and the other from $A_2$. This way, we can keep track of the computation on the word $w$ for each of our automata. The set of accepting states for $A’$ are those pairs with an accepting state from each machine. In other words, $A’$ will accept only when $w$ reaches a final state in $A_1$ and a final state in $A_2$.
Why is this called the product automaton? Notice that the states of the automaton are the cartesian product of the state sets of the two DFAs we started out with. So we can think of the product automaton as being the cartesian product of two DFAs. Of course, we have to make sure that the transition function still makes sense.
So let’s prove formally that the product construction works. As usual, we need to first show that the transition function behaves pretty much how we’d expect it to.
For all $w \in \Sigma^*$, \[\delta'^*(\langle p,q \rangle, w) = \langle \delta_1^*(p,w), \delta_2^*(q,w) \rangle.\]
We will prove this by induction on the input string $w$.
For the base case, we have $w = \varepsilon$. Then $\delta'^*(\langle p,q \rangle, \varepsilon) = \langle p,q \rangle$ by definition of $\delta'^*$ and $\langle \delta_1^*(p,\varepsilon), \delta_2^*(q, \varepsilon) \rangle = \langle p, q \rangle$ by definition of $\delta_1^*$ and $\delta_2^*$. So we have shown \[\delta'^*(\langle p, q \rangle, \varepsilon) = \langle(\delta_1^*(p, \varepsilon), \delta_2^*(q, \varepsilon) \rangle.\]
Then for our inductive step, we let $w = xa$ for $a \in \Sigma$ and $x \in \Sigma^*$ and assume that $\delta'^*(\langle p,q \rangle, x) = \langle \delta_1^*(p,x), \delta_2^*(q,x) \rangle$. We have \begin{align*} \delta'^*(\langle p,q \rangle, xa) &= \delta'(\delta'^*(\langle p,q \rangle, x),a) &\text{Definition of $\delta'^*$}\\ &= \delta'(\langle \delta_1^*(p,x), \delta_2^*(q,x) \rangle,a) &\text{Inductive hypothesis} \\ &= \langle \delta_1(\delta_1^*(p,x),a), \delta_2(\delta_2^*(q,x),a) \rangle &\text{Definition of $\delta'$}\\ &= \langle \delta_1^*(p,xa), \delta_2^*(q,xa) \rangle &\text{Definition of $\delta_1^*$ and $\delta_2^*$} \end{align*}
Now, we’ll prove that our automaton accepts the intersection like we want.
$L(A') = L_1 \cap L_2$.
Let $w \in \Sigma^*$. Then, \begin{align*} w \in L(A') &\iff \delta'^*(q_0',w) \in F' & \text{Acceptance by $A'$}\\ &\iff \delta'^*(\langle q_{0,1}, q_{0,2} \rangle, w) \in F_1 \times F_2 & \text{Definition of $A'$}\\ &\iff \langle \delta_1^*(q_{0,1},w), \delta_2^*(q_{0,2},w) \rangle \in F_1 \times F_2 &\text{Lemma}\\ &\iff \delta_1(q_{0,1},w) \in F_1 \text{ and } \delta_2(q_{0,2},w) \in F_2 &\text{Definition of $A'$}\\ &\iff w \in L(A_1) \text{ and } w \in L(A_2) &\text{Acceptance by $A_1, A_2$}\\ &\iff w \in L_1 \text{ and } w \in L_2 &\text{Premise}\\ &\iff w \in L_1 \cap L_2 &\text{Intersection} \end{align*}
One way to think about this argument is that if $w \in L(A')$, we can recover a path as it moves through the machine $L(A')$. If we look at the states on that path, then we can pick out a path in $A_1$ from $q_{0,1}$ to a state in $F_1$ and a path in $A_2$ from $q_{0,2}$ to a state in $F_2$.
Since we can do this for any pair of DFAs, we have the following consequence.
The class of recognizable languages is closed under intersection.
The product construction is a construction due to Rabin and Scott in 1959. We will see this paper pop up again—a lot of fundamental results about finite automata come from here.
Now, let’s consider union. If we think about our approach to intersection, we can see that it’s not actually that different. Instead of accepting a word when both automata accept it, we can modify our final state set so that a word is accepted when at least one of the automata accept. Then such a DFA follows the product construction from above, with the difference being the set of final states, $$F' = (F_1 \times Q_2) \cup (Q_1 \times F_2).$$ This set consists of all pairs that contain a final state of $A_1$ or a final state of $A_2$.
However, there is another easy but slightly indirect way to show that we can always find a DFA for the union of two recognizable languages. We can make use of the closure properties we’ve already proved so far.
The class of recognizable languages is closed under union.
Let $L_1$ and $L_2$ be languages recognized by DFAs. Then $\overline{L_1}$ and $\overline{L_2}$ are also recognized by DFAs. Since recognizable languages are closed under intersection, $\overline{L_1} \cap \overline{L_2}$ is also a recognizable language. But this language is $\overline{L_1 \cup L_2}$ by De Morgan’s laws. And since recognizable languages are closed under complementation, $L_1 \cup L_2$ must also be a recognizable language.