Finite automata
Finite automata are arguably the simplest model of computation. They actually first appeared as far back as the 1940s in a different context from Turing machines: early work on neural networks. The idea was to try to represent an organism or robot of some kind responding to some stimulus, which are referred to as events. Upon the occurrence of an event, the “robot” would change its internal state in response and there would be a finite number of possible such states. Today, the use of finite automata for modelling such systems is still around in a branch of control theory in engineering under the name “discrete event systems”. But all of this has nothing to do with how we’re going to consider finite automata.
Since the machine only scans the input word to the right, it is guaranteed to stop when it reaches the end of the input string. Upon reading the entire input, the machine answers “Yes” or “No” depending on the state that the machine is in. This is essentially solves a decision problem and so we can think of the machine as describing a set of strings—those that give an answer of “Yes”.
We call these finite automata because they have only a finite number of states. Since the tape head can only move to the right, it’s not really necessary to think about the tape portion of the machine, at least for now.
We begin with the formal definition for finite automata.
A deterministic finite automaton (DFA) is a 5-tuple $A = (Q,\Sigma,\delta,q_0,F)$, where
- $Q$ is a finite set of states,
- $\Sigma$ is a finite input alphabet,
- $\delta$ is a total function $\delta:Q \times \Sigma \to Q$, called a transition function,
- $q_0$ is the start or initial state,
- $F$ is a set of final or accepting states.
Note that by our definition, $\delta$ must be defined for every state and input symbol. We call this a deterministic finite automaton because the transition function $\delta$ is uniquely determined by the state and input symbol.
We can represent finite automata by drawing the important part of the machine: the state diagram. We draw each state as a circle and label it as appropriate. Transitions are represented as arrows, leaving one state and entering another, labelled by the appropriate input symbol. We denote accepting states by a double circle and we denote the start state by an arrow that comes in from nowhere in particular.
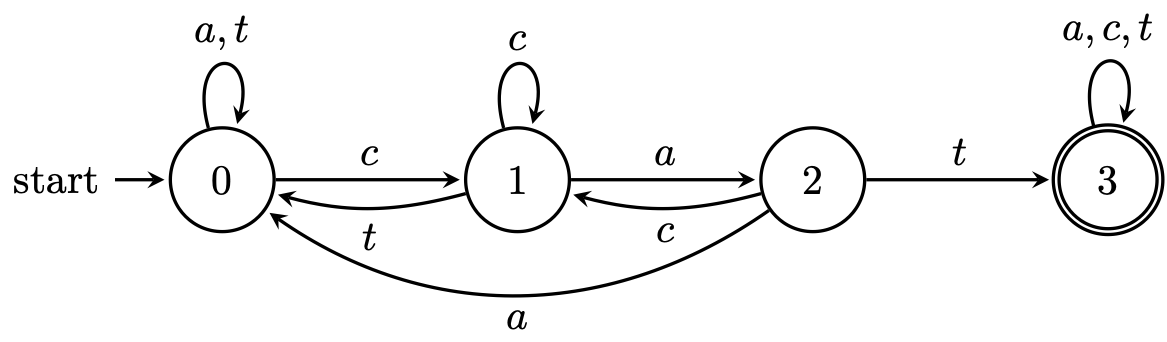
Here is our state machine more formally specified. For simplicity, we take $\Sigma = \{a,c,t\}$.
\begin{tikzpicture}[node distance=2.5cm,thick,auto]
\node[state,initial] (0) {$0$};
\node[state] (1) [right of=0]{$1$};
\node[state] (2) [right of=1]{$2$};
\node[state,accepting] (3) [right of=2]{$3$};
\path[->]
(0) edge [loop above] node {$a,t$} (0)
(0) edge node {$c$} (1)
(1) edge [bend left=15] node {$t$} (0)
(1) edge [loop above] node {$c$} (1)
(1) edge node {$a$} (2)
(2) edge node {$t$} (3)
(3) edge [loop above] node {$a,c,t$} (3)
(2) edge [bend left=15] node {$c$} (1)
(2) edge [bend left=35] node {$a$} (0)
;
\end{tikzpicture}
Suppose this DFA is $A = (Q, \Sigma, \delta, q_0, F)$. We can list all the parts that we’ve specified in our formal definition:
- $Q = \{0,1,2,3\}$,
- $\Sigma = \{a,c,t\}$,
- $F = \{3\}$,
and $\delta$ is given by
| | $a$ | $c$ | $t$
|
| $0$ | $0$ | $1$ | $0$
|
| $1$ | $2$ | $1$ | $0$
|
| $2$ | $0$ | $1$ | $3$
|
| $3$ | $3$ | $3$ | $3$
|
What does this machine do? We take a string and read it symbol by symbol and trace where we go based on the character. We can interpret each state in the following way:
- State $0$: hasn’t seen any prefix of the string $cat$.
- State $1$: the last symbol seen is the prefix $c$.
- State $2$: the last two symbols seen are the prefix $ca$.
- State $3$: has seen the string $cat$.
For example, suppose we want to run this machine on the string $accacata$. We can view a computation on this machine by
\[0 \xrightarrow{a} 0 \xrightarrow{c} 1 \xrightarrow{c} 1 \xrightarrow{a} 2 \xrightarrow{c} 1 \xrightarrow{a} 2 \xrightarrow{t} 3 \xrightarrow{a} 3.\]
Since the machine is in state 3 upon completion of the string, $accacata$ is accepted by the machine.
Here is a Python implementation for this machine.
from automata.fa.dfa import DFA
A = DFA(
states=set('0123'),
input_symbols=set('act'),
transitions={
'0': {'a': '0', 'c': '1', 't': '0'},
'1': {'a': '2', 'c': '1', 't': '0'},
'2': {'a': '0', 'c': '1', 't': '3'},
'3': {'a': '3', 'c': '3', 't': '3'}
},
initial_state='0',
final_states={'3'}
)
What is nice about this is that it gives a way to test our definitions. For example, the constructor for this object will complain if your definition is not correct. This also gives us a way to test the machine.
>>> A.accepts_input('accacata')
True
>>> A.read_input('accacata')
'3'
>>> ', '.join(A.read_input_stepwise('accacata'))
'0, 0, 1, 1, 2, 1, 2, 3, 3'
Note that DFA.read_input_stepwise produces a generator object.
Now, we want to also formally define the notion of the set of words that our machine will accept. Intuitively, we have a sense of what acceptance and rejection means. We read a word and trace a path along the automaton and if we end up in an accepting state, the word is accepted and otherwise, the word is rejected.
First of all, it makes sense that we should be able to define this formally by thinking about the conditions that we’ve placed on the transition function. Since on each state $q$ and on each symbol $a$, we know exactly what state we end up on, it makes sense that each word takes us to a specific state.
So, we can extend the definition of the transition function so that it is a function from a state and a word to a state, $\delta^* : Q \times \Sigma^* \to Q$.
The function $\delta^* : Q \times \Sigma^* \to Q$ is defined by
- $\delta^*(q,\varepsilon) = q$,
- $\delta^*(q,w) = \delta^*(\delta(q,a),x)$, for $a \in \Sigma$ and $x \in \Sigma^*$.
It might be helpful to note that we can also approach this definition from the other direction. That is, instead of writing $w = ax$, we consider the factorization $w = xa$. Then the inductive part of our definition becomes
$$\delta^*(q,xa) = \delta(\delta^*(q,x),a).$$
What’s nice about using $w = xa$ is it naturally captures the idea that we often want to know what the "last step" of a computation is, while the $w = ax$ version focuses on the first step.
Another particularly nice property that we get out of this is the ability to split computations up by substring. The following is a nice induction exercise to prove on your own.
Let $A$ be a DFA $A = (Q, \Sigma, \delta, q_0, F)$. Then for all $u, v \in \Sigma^*$ and $q \in Q$,
\[\delta^*(q,uv) = \delta^*(\delta^*(q,u),v).\]
Technically speaking, $\delta$ and $\delta^*$ are different functions, since one is a function on symbols and the other is a function on words. However, since $\delta^*$ is a natural extension of $\delta$, it’s very easy to forget about the star and simply write $\delta$ for both functions. This is something we won’t be too concerned about since the meaning is almost always clear from context. That said, sometimes it is necessary to make the distinction, like when you want to prove something about how $\delta$ and $\delta^*$ are related.
A neat observation about $\delta^*$ is that if you are familiar with functional programming, then this is really just a fold or reduce on $\delta$. In other words, $\delta^*(q,w)$ would be something like (foldl δ q w).
Now, we can formally define the acceptance of a word by a DFA.
Let $A = (Q,\Sigma,\delta,q_0,F)$ be a DFA. We say $A$ accepts a word $w \in \Sigma^*$ when $\delta^*(q_0,w) \in F$. Then the language of a DFA $A$, denoted $L(A)$, is the set of all words accepted by $A$,
$$L(A) = \{w \in \Sigma^* \mid \delta^*(q_0,w) \in F \}.$$
We say that a language $L$ is accepted by a DFA $A$ if for all strings $w \in \Sigma^*$, $A$ accepts $w$ if $w \in L$ and $A$ rejects $w$ if $w \not \in L$. In other words, $w \in L(A)$ if and only if $w \in L$, or more succinctly, $L(A) = L$.
It’s important to emphasize that when we say that a DFA $A$ accepts a language, this is a statement of equality. When read informally, to say that a DFA accepts a language sounds like $L \subseteq L(A)$. But it is important to remember that acceptance/recognition is about “solving the problem”. In this way, the DFA acts as a description of the language that it “solves”.
Since we are interested in the power of machines like DFAs, we will be considering questions about those languages that are accepted by DFAs. In order to talk about them collectively, we define the class of languages that are accepted by DFAs.
Let $\Sigma$ be an alphabet. A language $L \subseteq \Sigma^*$ is said to be recognizable if it is accepted by a DFA. That is, if there exists a DFA $A$ such that $L = L(A)$. The class of recognizable languages over $\Sigma$ may be denoted $\operatorname{\mathsf{Rec}} \Sigma^*$.
Divisibility
Now, we can begin to think about the kinds of problems that finite automata can solve. As a first example, we’ll consider the idea of divisibility. Recall (for instance, from discrete math) that when we divide two integers, we don’t always get another integer, which is nice because it spices things up a bit. However, we can prove that we always get a unique quotient and remainder.
A constructive proof of the division theorem shows us how to do this, though we’ve likely employed such an algorithm numerous times throughout our schooling. This was noted by Blaise Pascal in the 1600s who showed that there’s an algorithm for this in any base, not just decimal, and only by examining the sum of the digits of the number. This is based on the observation that remainders are essentially cyclic—we understand this structure to be $\mathbb Z_m$, the field of the integers modulo $m$.
Recall that for a string $w \in \{0,1\}^*$, we denote by $\llparen w \rrparen_2$ the natural number obtained by interpreting $w$ in base 2. Let’s consider the language
$$ L_{\div 3} = \{w \in \{0,1\}^* \mid 3 \mid \llparen w \rrparen_2\}.$$
In other words, this language describes the decision problem of whether a number is divisible by 3.
This is a fairly straightforward question to solve using a standard programming language, but notice that our model of computation places some fairly tight restrictions on what we can do: we can only remember a fixed amount of information and we must make a decision upon reading the string from left to right exactly once. This can be a bit of a challenge because we don’t typically think of numerical problems from left to right—we usually begin from the right and go to the left.
The key here is that we need to be able to say something about the input we’ve read so far. If it’s the end of the input, what kind of determination can we make about what we’ve read? If it’s not the end of the input, what kind of information do we have that will allow us to update what we know, based on the next symbol that’s read?
The other observation here is about the problem setting: how do we test for divisibility? A standard run through CS 141 will have you used to the idea of the modulus operator, which produces remainders. And a quick jaunt through discrete math will tell you that there are only ever a finite number of remainders and every number must have one. It seems like this is a viable option for the information we want to keep as states.
So our state set is $\{0,1,2\}$, representing each of the three equivalence classes in $\mathbb Z_3$. How do we move between them?
Recall that we need to read a string from left to right, which means that the most significant bits are read first. Now, suppose we’ve read a string $x$ and now we want to read the next symbol—either a $0$ or a $1$. We just have to remember a bit about binary math. We recall that adding a new digit to the right end of a binary string has the following arithmetic interpretation:
$$\llparen x0\rrparen_2 = 2 \cdot \llparen x\rrparen_2 \quad \text{and} \quad \llparen x1\rrparen_2 = 2 \cdot \llparen x\rrparen_2 + 1.$$
In essence, we take $x$ and do a “bit shift” to the right. In binary, this has the effect of multiplying the number by 2. Since the next bit to be read is the last bit we read, this is always going to be in the “1”s position, so we are adding either 0 or 1 to the doubled integer.
With this in mind, we just need to think about how reading a new bit will change our result modulo 3. Luckily, we know that modular arithmetic behaves like ordinary arithmetic and we can accomplish this computation just by considering the residues mod 3. We can summarize the changes to $\llparen x\rrparen_2 \bmod 3$ in the following table:
| $\llparen x\rrparen_2 \bmod 3$ | $\llparen x0\rrparen_2 \bmod 3$ | $\llparen x1\rrparen_2 \bmod 3$ |
|---|
| $0$ | $0$ | $1$ |
| $1$ | $2$ | $0$ |
| $2$ | $1$ | $2$ |
Now, this looks suspiciously like a transition table. If $q = \llparen x \rrparen_2 \bmod 3$ is the state that we’re in, then we have $\delta(q,a) = (2 \cdot q + a) \bmod 3$ and this corresponds exactly with our definition of $\delta$ from above. So now we have the pieces to put together our DFA.