Non-context-free languages
We’ve briefly touched on what characterizes context-free languages. In the same way that we can think of the characteristic property of regular languages as being “finiteness”, we can think of the characteristic property of context-free languages as being about “nestedness” or “symmetry”. This means that languages that are not context-free do not have this nice structural property of nestedness.
For example, why is it that a language of strings $xx^R$ is context-free, but a language of strings $xx$ is not? If you look at the exercises, you see this theme a lot—context-free languages often make use of reversal. And in many cases, if we get rid of that reversal, we end up with something that’s not context-free.
Intuitively, one can see why this might be the case when thinking about the operation of a PDA: if our memory is constrained by stack access, then we necessarily can only retrieve information in reverse-order, or whatever was inserted most recently. We would like to formalize this notion.
Now, we discover why, several weeks ago, when we discussed the pumping lemma, I wrote “pumping lemma for recognizable languages” (more commonly called the “pumping lemma for regular languages”). Yes, it is because there is a pumping lemma for context-free languages.
The pumping lemma for regular languages describes a structural constraint on the description of regular languages. The structure that is used in the pumping lemma for regular languages is the finite automaton. Similarly, the pumping lemma for context-free languages will describe a structural constraint on the description of context-free languages—but we will use context-free grammars for this.
Let $L \subseteq \Sigma^*$ be a context-free language. Then there exists a positive integer $n$ such that for every word $w \in L$ with $|w| \geq n$, there exists a factorization $w = uvxyz$ with $u,v,x,y,z \in \Sigma^*$ such that
- $vy \neq \varepsilon$,
- $|vxy| \leq n$,
- $uv^i xy^i z \in L$ for all $i \in \mathbb N$.
This pumping lemma is due to Bar-Hillel, Perles, and Shamir in 1961. As it turns out, there are a lot of language classes for which there are pumping lemmas (linear languages, deterministic context-free languages, indexed languages, regular tree languages).
The reasoning behind the pumping lemma for context-free languages is in the same vein as the one for regular languages. Since the description of any context-free grammar is finite, for a sufficiently long word, some aspect of its derivation must be repeated. For regular languages, this is analogous to the fact that a state will show up more than once on a path in a DFA. For context-free languages, this will be the fact that a variable appears more than once on a path in a parse tree.
Since $L$ is context-free, there must be a CFG $G$ in Chomsky normal form that generates it. Let $m$ be the number of variables in $G$. Then the pumping length for $L$ will be $n = 2^{m+1}$.
Consider a word $w \in L$ with $|w| \geq n = 2^{m+1}$. Let $T$ be a parse tree for $w$ and fix it. Since $G$ is in CNF, the parse tree $T$ is a binary tree and it has $n = 2^{m+1}$ leaf nodes. Then there must be a path in $T$ from the root to a leaf containing at least $m+1$ internal nodes.
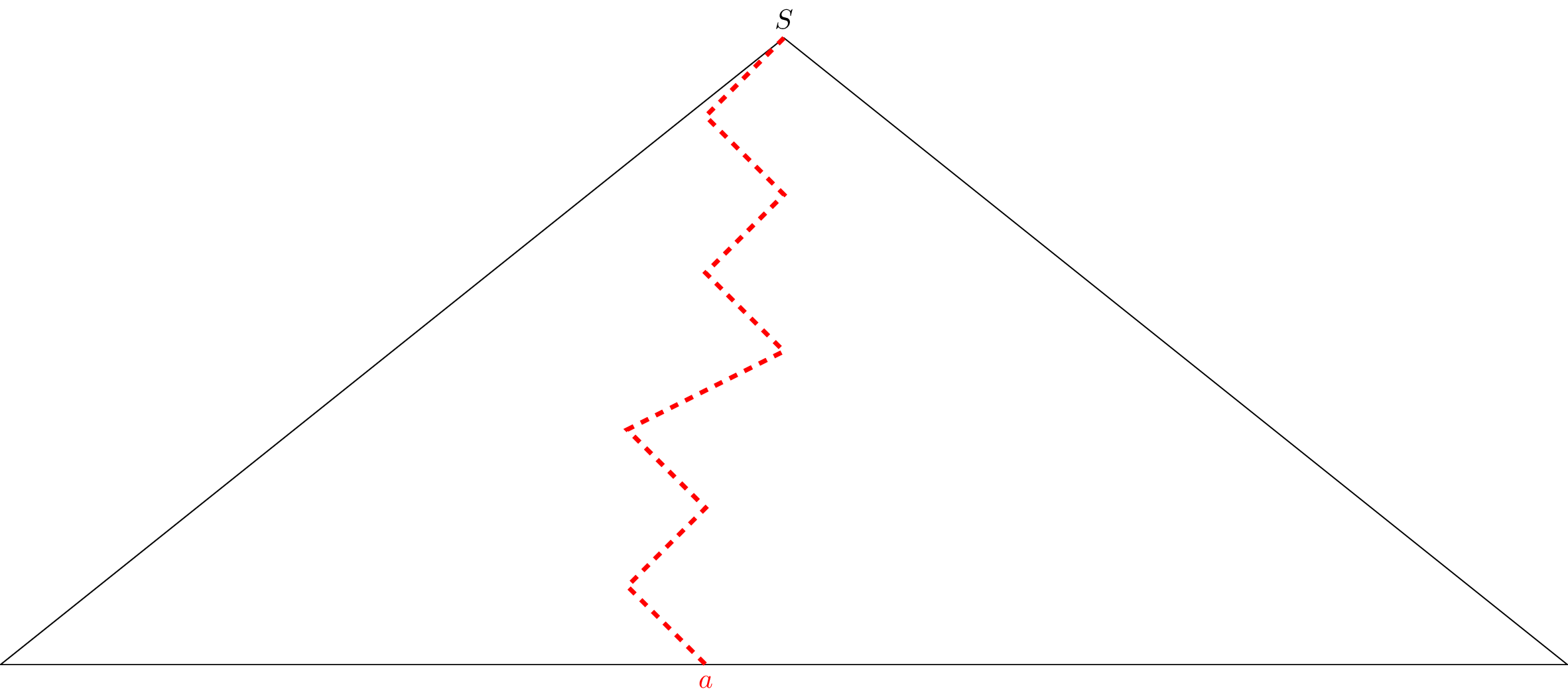
Pick such a path. Since there are at least $m+1$ internal nodes along this path and only $m$ different variables in $G$, by the Pigeonhole principle, there must be a variable of $G$ that appears twice on the path. Let this variable be $X$ and consider the occurrence of $X$ that is closest to the leaf on our chosen path.
Let $T_1$ and $T_2$ be two subtrees of $T$ that are rooted at the two occurrences of $X$ on the path closest to the leaf (i.e., the closest one and the next closest one). Let $T_2$ be the tree rooted at the closest occurrence of $X$ so $T_2$ must be a proper subtree of $T_1$. Furthermore, every path from the root of $T_1$ to a leaf has at most $m+1$ internal nodes and therefore $T_1$ has at most $2^{m+1} = n$ leaf nodes.
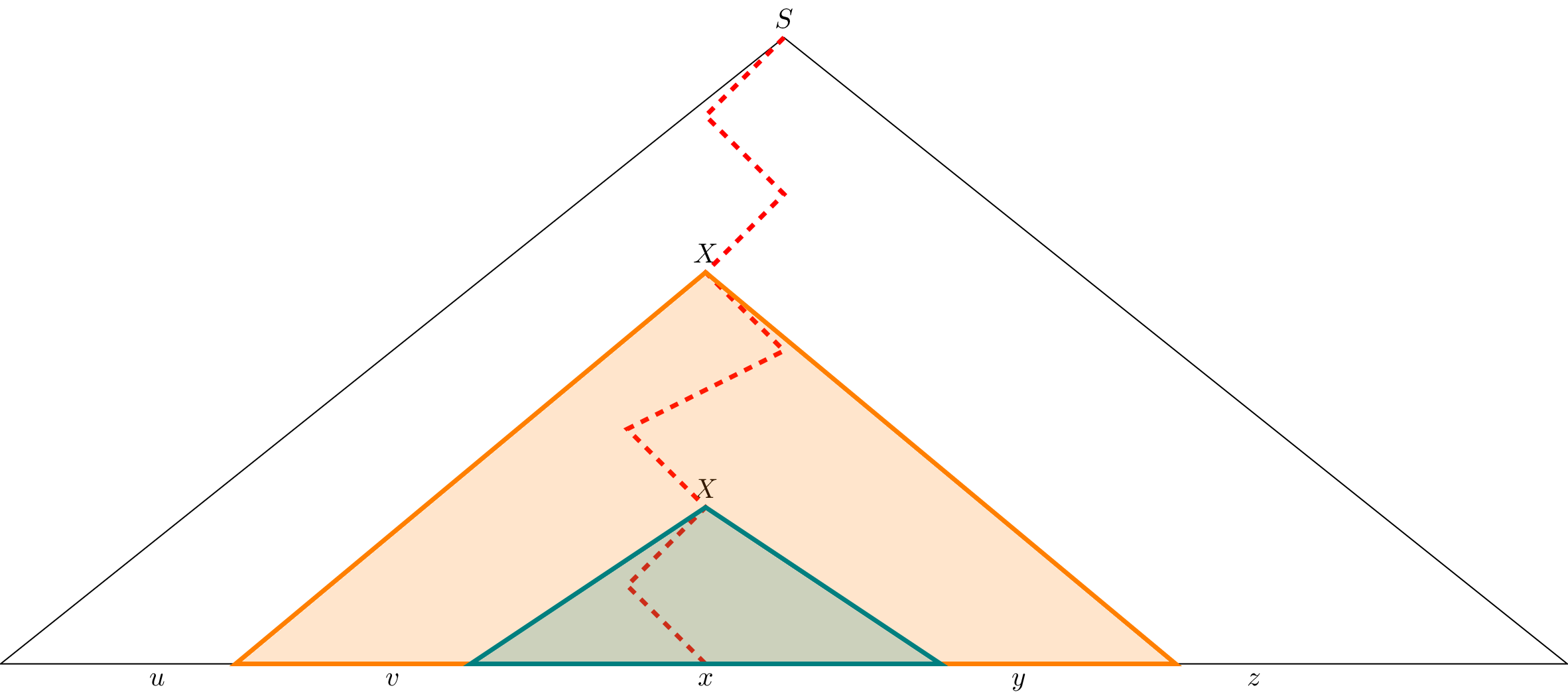
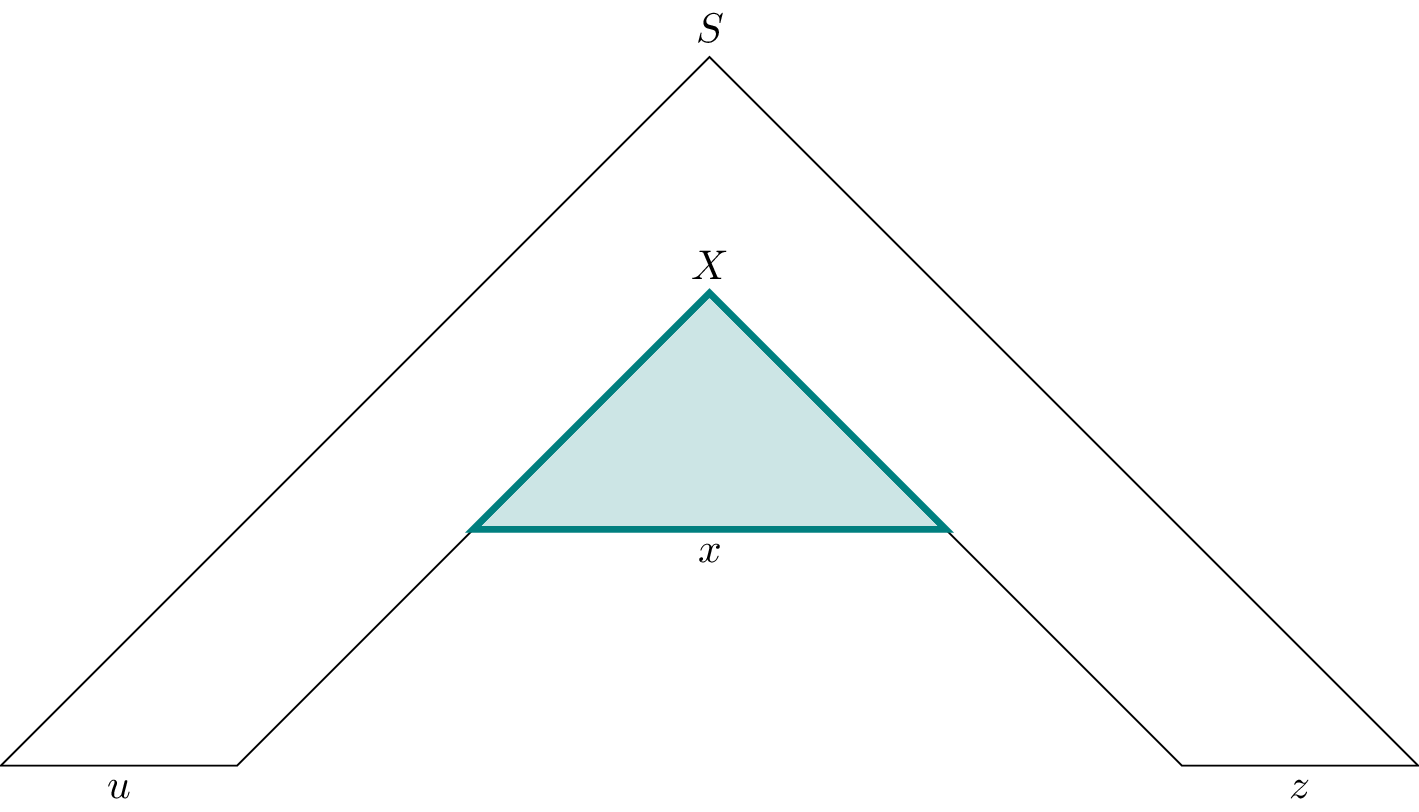
Let $x$ be the word for which $T_2$ is the parse tree rooted at $X$ and let $v$ and $y$ be the words formed by the leaves of the parse tree $T_1$ rooted at $X$ around $T_2$ such that $T_1$ is a parse tree for the word $vxy$. Then we let $u$ and $z$ be the words formed by the leaves of $T$ around $T_1$ such that $T$ is a parse tree for the word $w = uvxyz$.
Now we need to show that $uvxyz$ is a factorization for $w$ such that the conditions of the pumping lemma hold. First, to see that $|vxy| \leq n$, we just observe that $T_1$ can have at most $2^{m+1} = n$ leaf nodes.
Next, to see that $vy \neq \varepsilon$, we note that since both $T_1$ and $T_2$ are rooted at $X$, we can construct a parse tree in which $T_1$ is removed and replaced by $T_2$. This would then be a parse tree for $uxz$. However, recall that every parse tree for a word in a grammar in CNF must have exactly the same size. Since $T_2$ was already shown to be smaller than $T_1$ we must have that $uxz \neq uvxyz$ and therefore $vy \neq \varepsilon$.
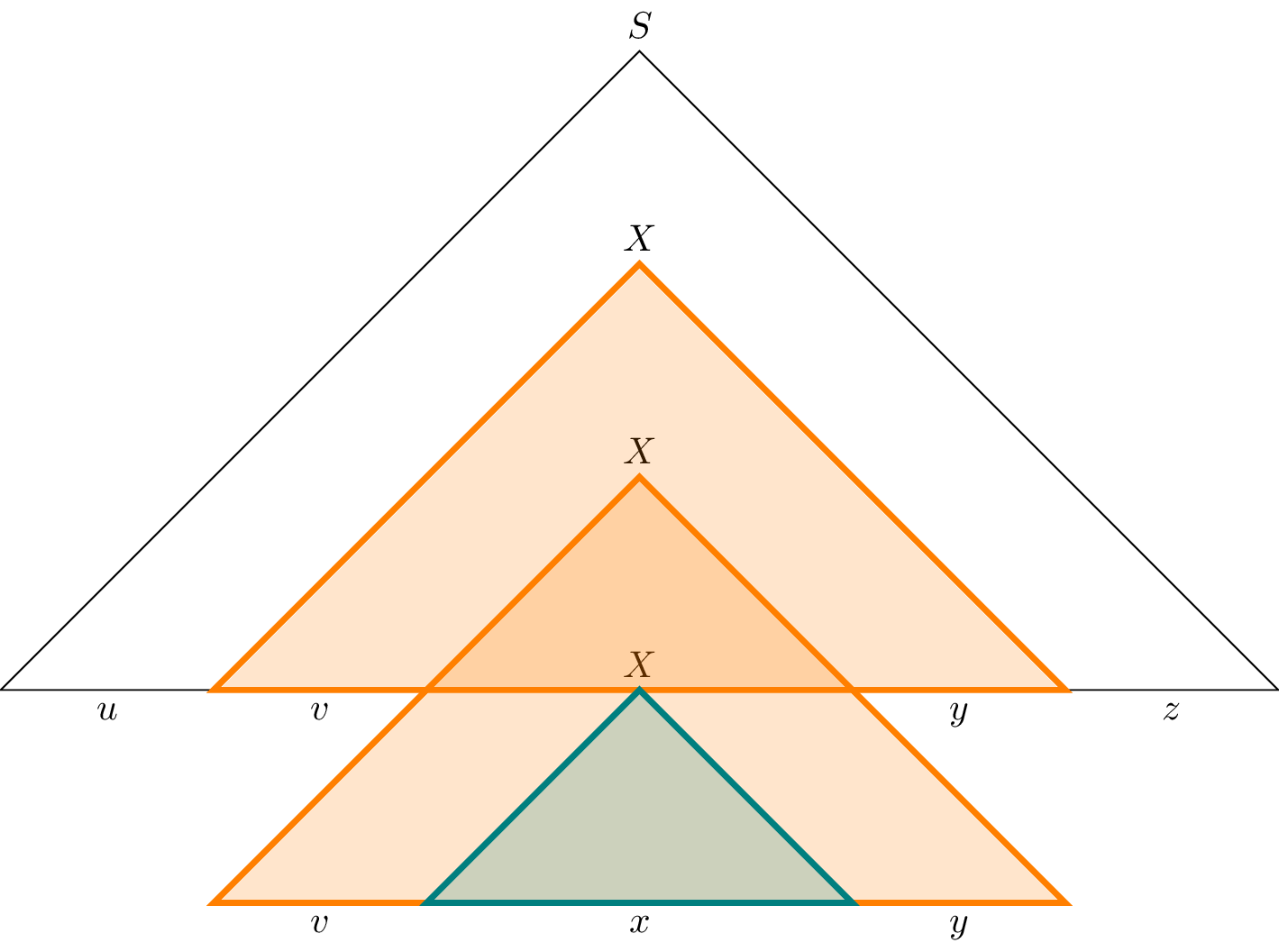
Finally, to see that $uv^ixy^iz \in L$ for all $i \in \mathbb N$, we first note that we have already shown $uv^0 xy^0 z \in L$ above. To see that this holds for $i > 1$, we can perform a similar substitution by replacing $T_2$ with $T_1$ to give us a parse tree for $uv^2xy^2$. We can then repeat this process any number of times to obtain a parse tree for $uv^ixy^iz$.
To show that a language is not context-free, our strategy will be very similar to the one we employed for regular languages. We assume that our language is context-free, then show that we are able to find a string that is unable to satisfy the conditions of the pumping lemma by following our template from before.
- The opponent chooses a pumping constant $n \gt 0$.
- We choose a word $w \in L$ with $|w| \geq n$.
- The opponent chooses a factorization $w = uvxyz$ with $|vxy| \leq n$ and $vy \neq \varepsilon$.
- We choose $i \in \mathbb N$.
Then we win if $uv^ixy^iz \not \in L$.
However, there are a few more things to be mindful of when carrying out these proofs for context-free languages. The reason for this is the conditions that are placed on our factorization. Recall that for regular languages, we had factorizations $xyz$ with $|xy| \leq n$. This condition constrained the area that we “pumped” to the front of the string.
For context-free languages, the pumping lemma specifies $uvxyz$ such that $|vxy| \leq n$. This change makes it so that the “pumpable” part of the string can be anywhere in the string, not just near the front. This means that we will have much more casework to do.
Let $L = \{a^m b^m c^m \mid m \geq 0\}$. Then $L$ is not context-free.
Suppose that $L$ is context-free and let $n$ be the pumping length for $L$. Let $w = a^n b^n c^n$. Clearly, $w \in L$ and $|w| = 3n \geq n$. Now, we must consider all factorizations of $w = uvxyz$ such that $|vxy| \leq n$ and $vy \neq \varepsilon$. We consider the following cases, based on the fact that $|vxy| \leq n$.
- Suppose $vy = a^s$ such that $0 \lt s \leq n$. We have $uv^2xy^2z = a^{n+s}b^nc^n \not \in L$, since $n+s \neq n$.
- Suppose $vy = a^s b^t$ such that $0 \lt s+t \leq n$. Then $uv^0xy^0z = a^{n-s}b^{n-t}c^n$. Then we have at least one of $n-s \lt n$ or $n-t \lt n$, so $uv^0xy^0z \not \in L$.
- Why did we choose $i = 0$ instead of $i = 2$? Since we wrote $vy = a^s b^t$, it is easy to think that $v = a^s$ and $y = b^t$, but we could actually have $v = a^{s'}$ and $y = a^{s-s'} b^t$, in which case we would have $uv^2xy^2z = a^{n+s'}b^ta^{s-s'}b^{n}c^n$, which is still not in the language as we wanted, but is a lot more complicated to write. In other words, the choice is a tactical choice on the part of the author to save himself some time (if he didn’t follow up with this explanation for your benefit).
- Suppose $vy = b^s$ such that $0 \lt s \leq n$. We can apply a similar argument as for Case 1.
- Suppose $vy = b^s c^t$ such that $0 \lt s+t \leq n$. We can apply a similar argument as for Case 2.
- Suppose $vy = c^s$ such that $0 \lt s \leq n$. We can apply a similar argument as for Case 1.
Thus, every factorization of $w = uvxyz$ fails to satisfy the pumping lemma and therefore $L$ is not context-free as assumed.
Note that since $|vxy| \leq n$, we could never have a situation where $vy$ contained all three of $a,b,c$. Notice also that we have five explicit cases, but luckily, each of these cases folds nicely into just two broad cases. How do we identify the cases? Since $|vxy| \leq n$, we can think of sliding a window of length $n$ across the entire string and identifying all of the different cases. All of this makes choosing the word $w$ to be pumped much more important in avoiding a lot of work.

What is it about strings $a^k b^k c^k$ that are not symmetric? The key is in the “linkage” we’re creating: we can only tie together two parts of the string at a time. The pumping lemma says that if we try to tie three parts of the string together, we will run into trouble.
Another observation to make is that the pumping lemma for context-free languages is comparatively less “powerful” that the pumping lemma for regular languages, in that there are many cases of non-context-free languages for which a pumping lemma proof is difficult or impossible. There are a number of other tools that have been devleoped to deal with such languages, which we unfortunately don’t have time to cover.
Closure properties for context-free languages
We have not discussed closure properties for context-free languages in detail yet, but just like for regular languages, closure properties will turn out to be a useful tool for showing that certain languages are not context-free.
One thing you might have noticed with some of these examples is that they implictly use the regular operations:
- When we choose between two rules $S \to A_1 \mid A_2$, we’re really describing a union of strings generated from $A_1$ or those generated from $A_2$.
- When we take a rule $S \to A_1 A_2$, we’re really describing a concatenation of strings generated from $A_1$ and those generated from $A_2$.
- When we have a rule $S \to \alpha S \beta$, we’re really describing some iteration of strings generated from $S$.
We can use these observations to conclude that the context-free languages are closed under the regular operations.
The class of context-free languages is closed under the regular operations.
We’ll do this informally.
- For union, combine the variables and productions of your two grammars and add a new start variable with the new productions $S_0 \to S_1 \mid S_2$.
- For concatenation, very similarly, combine the variables and productions of your two grammars and add a new start variable with the new production $S_0 \to S_1 S_2$.
- For star, take your grammar and add a new start variable and rules $S_0 \to S_1 S_0 \mid \varepsilon$.
To prove this formally, we would need to through an inductive argument—this makes a nice exercise. An alternative exercise is to try to give constructions for these operations as pushdown automata.
Of course, it makes sense that we would need closure under the regular operations because they describe the “basic” operations we want to apply to languages: choice via union, string construction via concatenation, and iteration via star. The next natural candidates to consider then are complementation (the ability to negate) and intersection (expressing “and”).