Grammars
Grammars are a specific kind of string rewriting system. Informally, such systems define a set of rules of the form $\alpha \to \beta$, by which a string containing a substring $\alpha$ can be rewritten by replacing $\alpha$ with the substring $\beta$. Formally, we can define grammars in the following way.
A grammar if a 4-tuple $G = (V, \Sigma, P, S)$, where
- $V$ is a finite set of variables (sometimes called nonterminals), often denoted by uppercase letters,
- $\Sigma$ is a finite alphabet, called terminals or terminal symbols, with $\Sigma \cap V = \emptyset$,
- $P \subseteq (V \cup \Sigma)^*V(V \cup \Sigma)^* \times (V \cup \Sigma)^*$ is a finite set of productions or rules, written in the form $\alpha \to \beta$ where $\alpha \in (V \cup \Sigma)^*V(V \cup \Sigma)^*$ and $\beta \in (V \cup \Sigma)^*$ (i.e., rules consist of strings of terminals and variables with the restriction that the left hand side must contain at least one variable), and
- $S$ is the start variable.
The idea is that given a grammar, by starting with the start variable $S$ we can generate a string by applying production rules from the grammar until we arrive at a string that does not contain any variables and only contains terminals.
Like finite automata, grammars were developed in a different context than computation. As you might guess, formal grammars were designed as a way to formally specify grammars for natural language and were developed by Noam Chomsky in 1956 as phrase-structure grammars. But while the modern treatment of formal grammars was developed relatively recently, the notion of a formal grammar can be traced back to the Indian subcontinent, as far as the 4th century BCE.
Here’s a simple grammar for English taken from Jurafsky and Martin (2020):
\begin{align*}
S & \to NP \enspace VP \\
NP & \to Pronoun \mid ProperNoun \mid Det \enspace Nominal \\
Nominal & \to Nominal \enspace Noun \mid Noun \\
VP & \to Verb \mid Verb \enspace NP \mid Verb \enspace NP \enspace PP \mid Verb \enspace PP \\
PP &\to Preposition \enspace NP
\end{align*}
Despite their origins as a tool to define the grammatical structure of natural language, where they’re most commonly found now is in defining the grammatical structure of programming languages. For example, the Python Language Reference describes the language using snippets that look like
for_stmt ::= "for" target_list "in" starred_list ":" suite
["else" ":" suite]
This says that a for_stmt is a statement that begins with the literal string for, followed by a string that follows the rules of a target_list, followed by the literal string in, followed by a string that follows the rules of starred_list, followed by the literal string :, followed by a block of code defined by suite. Here are those rules
suite ::= stmt_list NEWLINE | NEWLINE INDENT statement+ DEDENT
stmt_list ::= simple_stmt (";" simple_stmt)* [";"]
In Section 10, we can find the full grammar specification that is the formally specified grammar that is used in the compiler.
I mentioned before that in the process of lexical analysis, the problem that regular languages are able to represent is the ability to tell us which tokens are present in a string, but not whether they’re in the correct order. The phase in compilation which enforces the correct order of tokens, or whether a string of tokens is “grammatically correct”, is called parsing. As you might expect, parsers parse strings and determine their grammatical validity, and as you might guess from our current discussion, parsers are built on formal grammars.
Context-free grammars
Now is a good time to introduce the Chomsky Hierarchy (due to Chomsky). Much like interest in comparing the power of automata models, the Chomsky Hierarchy categorizes the power of different classes of grammars. This is called a hierarchy because each class is contained in the more powerful class. Intuitively, every language that can be generated by a particular grammar can be generated by a more powerful grammar. (Though this is not quite as clear-cut as you may initially expect)
| Grammar | Language class | Machine model
|
|---|
| Type-0 (Unrestricted) | Recursively enumerable | Turing machines
|
| Type-1 (Context-sensitive) | Context-sensitive | Linear-bounded automata
|
| Type-2 (Context-free) | Context-free | Pushdown automata
|
| Type-3 (Right linear) | Regular | Finite automata
|
Interestingly, although intended for grammars, the hierarchy happens to map very nicely onto automata models.
Observe that the lowest level of the hierarchy, the languages characterized by right/left linear grammars, are (claimed to be) exactly the regular languages. Since we’ve already dealt with the regular languages in detail, we will be shifting our attention to the grammars just above: the context-free grammars.
A context-free grammar (CFG) is a 4-tuple $G = (V, \Sigma, P, S)$, where the set of productions is restricted to $P \subseteq V \times (V \cup \Sigma)^*$. That is, rules in a context-free grammar are of the form $A \to \beta$ for $A \in V$ and $\beta \in (V \cup \Sigma)^*$ (i.e. the left hand side of every production must be exactly one variable).
Let’s take a look at an example.
Let $G = (V,\Sigma,P,S)$, where $V = \{S\}$, $\Sigma = \{a,b\}$, $S$ is the start variable, and $P = \{(S, aSb), (S, SS), (S, \varepsilon)\}$.
While this is a perfectly fine definition, as we’ve defined it, we generally do not write grammars, even formally, like this. More typically, we write grammars with the variable on the left hand side of an arrow with the right hand side on the other side of the arrow, like so:
\begin{align*}
S &\to aSb \\
S &\to SS \\
S &\to \varepsilon
\end{align*}
We also write grammars that have the same left hand side with the right hand sides on one line, separated by $\mid$, like:
\begin{align*}
S &\to aSb \mid SS \mid \varepsilon
\end{align*}
This is sufficient because it contains all of the information of the formal definition: every variable appears on the left hand side of some production and every alphabet symbol appears in some right hand side of a production. If they don’t show up, they’re not ever used and can be safely omitted.
Of course, when doing this, we are implicitly relying on a number of stylistic conventions to be able to interpret the grammar without explicitly specifying its parts:
- The left-hand side variable of the first rule is assumed to be the start variable and is typically denoted $S$ (though not always).
- Variables are typically denoted by uppercase Latin characters (i.e. $A, B, C, \dots$).
- Alphabet symbols, if they are generic, are typically denoted by lowercase Latin characters (i.e. $a, b, c, \dots$).
If your set of variables or alphabet symbols is not obvious, then you should explicitly state what they are or some stylistic convention you plan to use. For instance, grammars used in linguistics or programming languages will use more descriptive variable names and a much larger set of terminals.
Let’s try generating a string.
Consider the grammar above. We start with the start variable $S$. We can replace $S$ with a right hand side of a production that has $S$ on its left hand side. So we can replace it with $\varepsilon$:
\[S \Rightarrow \varepsilon.\]
A convention that we will introduce here but discuss in more detail later is the use of $\Rightarrow$ to mean substitution according to our grammar. This is in contrast with $\rightarrow$, which denotes a production rule.
Now, observe that replacing $S$ with $\varepsilon$ was not the only possibility. We could alternatively replace it with $aSb$:
\[S \Rightarrow aSb.\]
In this case, our string contains a variable that we can replace. We can apply another rule.
\[S \Rightarrow aSb \Rightarrow aaSbb.\]
We continue applying rules until there are no variables left in our string to replace:
\[aaSbb \Rightarrow aaSSbb \Rightarrow aaSaSbbb \Rightarrow aaSabbb \Rightarrow aaaSbabbb \Rightarrow aaababbb .\]
Just like we think of states in finite automata as describing some property about the states that reach them, we should think of variables as describing some property of the strings that get generated by them.
Our grammar
\[S \to aSb \mid SS \mid \varepsilon\]
is fairly simple: it consists of a single variable $S$, so the language of the grammar $G$ consists of strings that are generated via the variable $S$. What this variable can be replaced by has three cases:
- $\varepsilon$,
- the concatenation of two strings generated by $S$, or
- a string generated by $S$ surrounded by $a$ on the left and $b$ on the right.
Notice that because $S$ shows up on the right hand side of some rules, that this is a recursive definition. This then makes the rule $S \to \varepsilon$ act as our base case. In fact, this grammar turns out to generate exactly the string of balanced brackets if we take $a$ to be an open bracket and $b$ to be a closing bracket.
Recall that palindromes are strings $w$ such that $w = w^R$. We claim that the following grammar generates the language of palindromes over the alphabet $\{a,b\}$.
\[S \to aSa \mid bSb \mid a \mid b \mid \varepsilon\]
To see why that is, we can view palindromes recursively. A palindrome is either
- A single symbol, like $a$ or $b$, or the empty string $\varepsilon$, or
- If $w$ is a palindrome, then $awa$ or $bwb$ is a palindrome.
Does this definition work? Consider a string $cwc$, where $w$ is a palindrome—so $w = w^R$. If we apply the definition of reversal, we have
\[(cwc)^R = (wc)^R c = c^R w^R c = cw^Rc = cwc.\]
One might ask why these are called context-free grammars. The name has to do with how the grammar works: for any production $A \to \alpha$, and any string $\beta A \gamma$, we can always apply the production $A \to \alpha$. The context of $A$, whatever is around $A$, has no bearing on what rule gets applied, only that the variable is present. Consider, for example, the following definition for context-sensitive grammars.
A grammar $G = (V, \Sigma, P, S)$ is said to be context-sensitive if every production in $P$ is of the form $\alpha B \gamma \to \alpha \beta \gamma$, for $\alpha, \gamma \in (V \cup \Sigma)^*$, $\beta \in (V \cup \Sigma)^+$, and $B \in V$.
In other words, a rule of the form $\alpha B \gamma \to \alpha \beta \gamma$ means that replacing $B$ with $\beta$ is only allowed within the context $(\alpha,\gamma)$. That is, rules are sensitive to the context in which a variable is situated.
This leads us to the notion of defining a language that is generated by a grammar and all of the accompanying theorems and proofs. To do so, we will need to discuss what this means and formalize some aspects of the generative process, the sequence of applications of production rules that result in a string. We require the following definitions.
Let $G = (V,\Sigma,P,S)$ be a context-free grammar.
- A sentential form is a string of variables and terminals $\alpha \in (V \cup \Sigma)^*$.
- A sentence is a sentential form that consists only of terminals (i.e. $\alpha \in \Sigma^*$).
- We define an application of a rule from the grammar $G$ on a sentential form by $\alpha B \gamma \Rightarrow_G \alpha \beta \gamma$ if $\alpha, \gamma \in (V \cup \Sigma)^*$ are strings of variables and terminals and $B \to \beta \in P$ is a rule in $G$.
- We define $\Rightarrow_G^k$ for $k \in \mathbb N$ to be $k$ applications of rules from $G$ by
- $\beta \Rightarrow_G^0 \beta$ for all $\beta \in (V \cup \Sigma)^*$,
- $\alpha \Rightarrow_G^{k+1} \gamma$ if $\alpha \Rightarrow_G^k \beta$ and $\beta \Rightarrow_G \gamma$.
Then we define
\[\Rightarrow_G^* = \bigcup\limits_{k \geq 0} \Rightarrow_G^k.\]
We say that $\Rightarrow_G^*$ is the reflexive, transitive closure of $\Rightarrow_G$. That is, $\alpha \Rightarrow_G^* \beta$ if there are sentential forms $\alpha = \alpha_0, \alpha_1, \dots, \alpha_n = \beta$ such that
$\alpha_0 \Rightarrow_G \alpha_1 \Rightarrow_G \cdots \Rightarrow_G \alpha_n$.
Usually, we drop the subscript $G$ if it is clear from context which grammar we’re talking about.
- A derivation is 0 or more applications $\Rightarrow_G$ to a sentential form.
These definitions allow us to give the following definition for what it means to be “generated” by a grammar.
Let $G = (V,\Sigma,P,S)$ be a context-free grammar. The language generated by $G$ is
$$L(G) = \{w \in \Sigma^* \mid S \Rightarrow_G^* w\}.$$
A language $L$ is a context-free language if there exists a context-free grammar $G$ such that $L(G) = L$.
Notice that the application of productions in a grammar is nondeterministic. In this case, we have two ways in which we have a choice to make. First, we can replace any variable that is present in a sentential form, so we have a choice of which variable to choose to expand. Secondly, for each variable, we have a choice of which production to apply to the variable. This means that a string can be generated by a grammar in multiple ways—that is, strings may have multiple derivations.
Recall that for a context-free grammar $G$, a derivation is a sequence of 0 or more applications $\Rightarrow_G$ to a sentential form.
- A leftmost derivation is a derivation in which the leftmost variable is expanded at each step. (One can analogously define a rightmost derivation, though that is not typically as useful or necessary)
- A parse tree is a tree representing a derivation.
- The internal nodes are labeled by variables and the leaf nodes are labeled by terminals.
- The children of a node are the nodes corresponding to the sequence of variables and terminals on the right hand side of a production.
- The yield of a parse tree is string obtained by reading off the leaf nodes.
Consider the following grammar $G$ that generates strings of balanced brackets
\[S \to \mathtt [ S \mathtt ] S \mid S \mathtt [ S \mathtt ] \mid \varepsilon,\]
The string $\mathtt{[][[]]}$ has the following derivations in $G$.
- A leftmost derivation
\[S \Rightarrow \mathtt [ S \mathtt ] S \Rightarrow \mathtt{[]} S \Rightarrow \mathtt{[]} \mathtt [ S \mathtt ] S \Rightarrow \mathtt{[][[} S \mathtt{]]} S \Rightarrow \mathtt{[][[]]} S \Rightarrow \mathtt{[][[]]} \]
- A derivation that is not leftmost,
\[S \Rightarrow \mathtt [ S \mathtt ] S \Rightarrow \mathtt [ S \mathtt ] \mathtt [ S \mathtt ] S \Rightarrow \mathtt [ S \mathtt ] \mathtt [ S \mathtt ] \Rightarrow \mathtt [ S \mathtt ] \mathtt [ \mathtt [ S \mathtt ] S \mathtt ] \Rightarrow \mathtt [ \mathtt ] \mathtt [ \mathtt [ S \mathtt ] S \mathtt ] \Rightarrow \mathtt [ \mathtt ] \mathtt [ \mathtt [ \mathtt ] S \mathtt ] \Rightarrow \mathtt [ \mathtt ] \mathtt [ \mathtt [ \mathtt ] \mathtt ] \]
- A different derivation that is leftmost,
\[S \Rightarrow S \mathtt [ S \mathtt ] \Rightarrow \mathtt [ S \mathtt ] S \mathtt [ S \mathtt ] \Rightarrow \mathtt{[]} S \mathtt [ S \mathtt ] \Rightarrow \mathtt{[]} \mathtt [ S \mathtt ] \Rightarrow \mathtt{[]} \mathtt{[[} S \mathtt ] S \mathtt ] \Rightarrow \mathtt{[]} \mathtt{[[]} S \mathtt ] \Rightarrow \mathtt{[]} \mathtt{[[]]}\]
An interesting observation from this is that the first two derivations actually result in the same parse tree, on the left, while the different leftmost derivation admits a different parse tree.
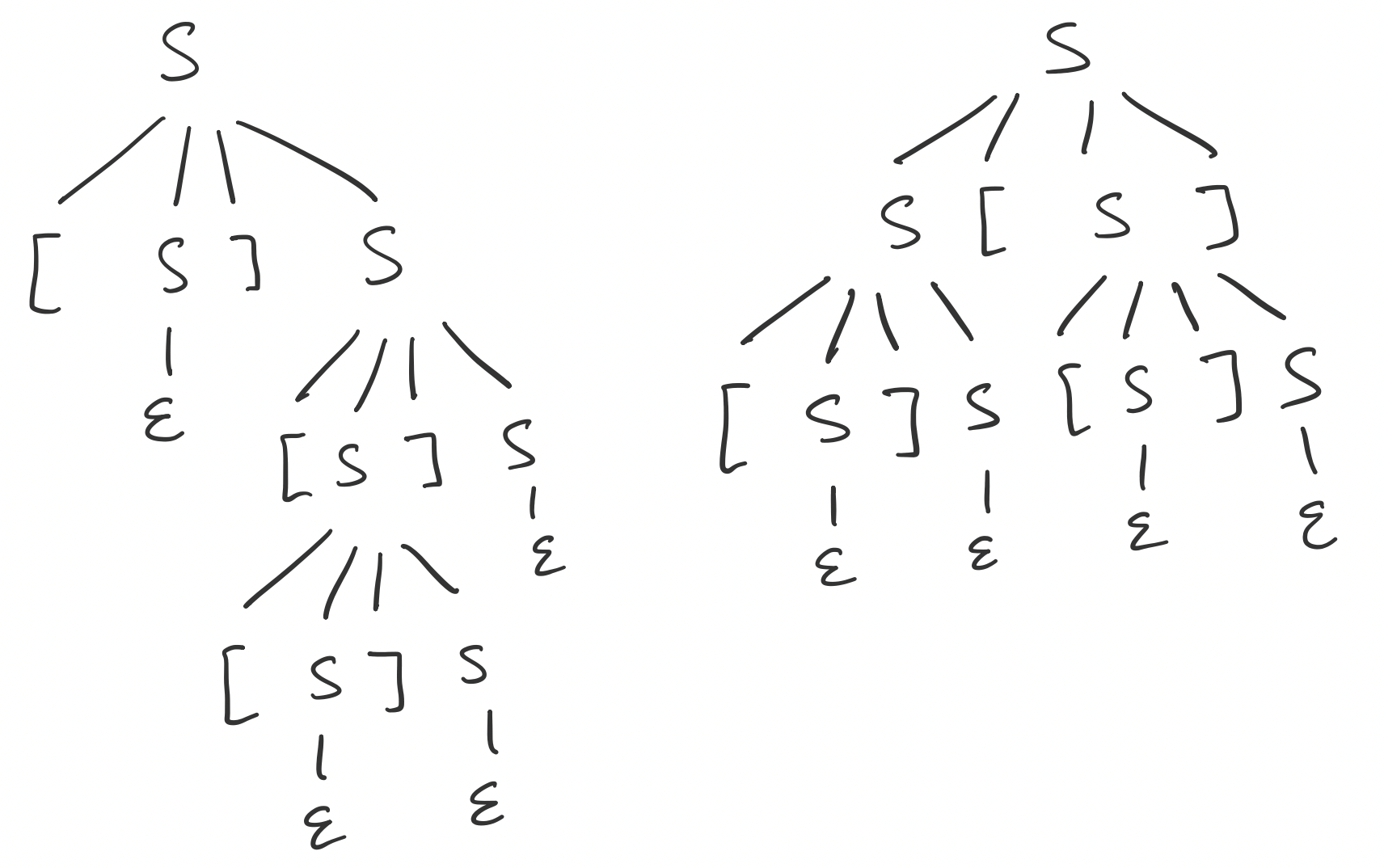
What this suggests is that derivations for a particular string are not unique, nor are the length of their derivations, even if we restrict ourselves to leftmost derivations. Furthermore, they do not admit the same parse trees. But one can conclude that a parse tree corresponds to a particular leftmost derivation.
One important observation to make here is that derivations are properties of grammars, not languages. From this example and an earlier example, we already have two different grammars that generate the same language (with a small modification).