Properties of pushdown automata
Equivalence of acceptance modes
As it turns out, the two modes of acceptance are equivalent. That is, given a PDA defined under one model of acceptance, it’s possible to construct a PDA under the other model of acceptance which accepts the same language. We’ll sketch out one of the constructions.
Let $A$ be a PDA that accepts by final state. Then there exists a PDA $A'$ which accepts $L(A)$ by empty stack.
Our new machine $A'$ needs to satisfy two properties. First of all, whenever $A$ reaches a final state on a word $w$ (that is, $A$ accepts $w$), we want to empty the stack. Secondly, we don’t want the stack to ever be empty before the entire input is read.
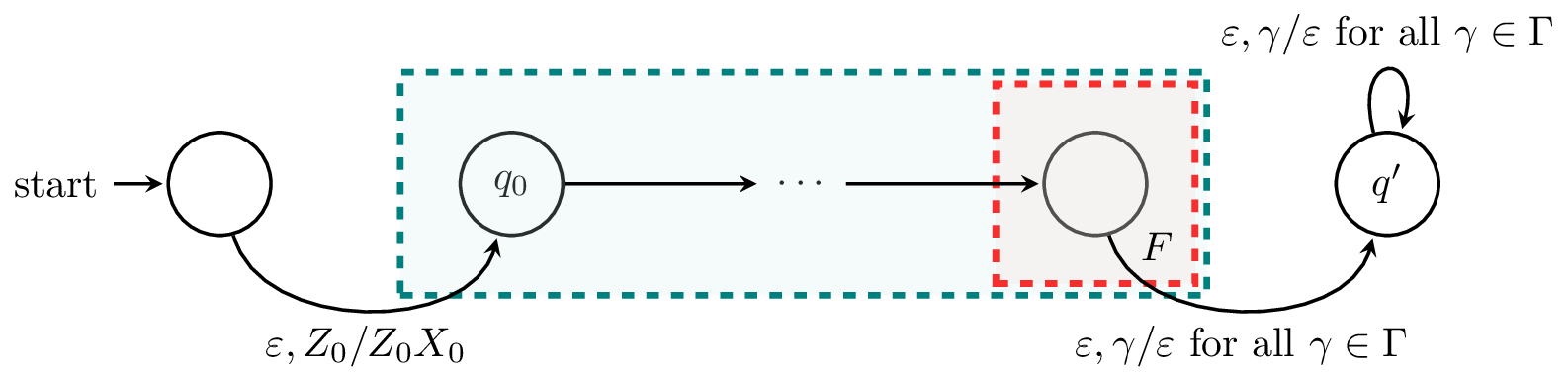
For the first property, we create a new state $q'$ and add transitions $\delta(q,\varepsilon,\gamma) = (q',\varepsilon)$ from every final state $q$ of $A$ to $q'$. Then $q'$ only contains transitions of the form $\delta(q',\varepsilon,\gamma) = (q',\varepsilon)$ for all $\gamma \in \Gamma$. Also note that any computation that enters $q'$ with part of the input still unread will crash.
For the second property, to prevent the stack from being empty during the course of the computation, we add a new symbol $X_0$ to the bottom of the stack. We do this by adding a new initial state with a transition to the initial state of $A$ whose only function is to place $X_0$ below $Z_0$ on the stack. Since $X_0$ is not in the stack alphabet of $A$, there is no transition that can remove it and the only way the stack can be empty is after visitng $q'$.
We can put this together into a formal construction. Let $A = (Q, \Sigma, \Gamma, \delta, q_0, Z_0, F)$. We will define the PDA $A' = (Q', \Sigma, \Gamma', \delta', q_0', Z_0)$ that accepts $L(A)$ by empty stack by
- $Q' = Q \cup \{q_0', q'\}$,
- $\Sigma$ is the same,
- $\Gamma' = \Gamma \cup \{X_0\}$,
- $q_0'$ is a new initial state,
- $Z_0$ is the same,
and we define $\delta'$ by taking $\delta$ and adding the following transitions:
- $\delta'(q_0', \varepsilon, Z_0) = \{(q_0, Z_0X_0)\}$, and
- $\delta'(q, \varepsilon, X) = \{(q', x)\}$ for all $q \in F$ and $X \in \Gamma$.
From here, one needs to argue that for all strings $w \in \Sigma^*$, $(q_0, w, Z_0) \vdash^*_A (q_f, \varepsilon, \gamma)$ for some $q_f \in F$ and $\gamma \in \Gamma^*$ if and only if $(q_0', w, Z_0) \vdash^*_{A'} (q', \varepsilon, \varepsilon)$.
We leave the other construction as an exercise.
Let $B$ be a PDA that accepts by empty stack. Then there exists a PDA $B'$ which accepts $L(B)$ by final state.
Determinism and PDAs
Recall that PDAs as defined are not deterministic. A natural question that follows is whether nondeterministic and deterministic PDAs describe the same class of languages. In other words, given a nondeterministic PDA, does there always exist an equivalent deterministic PDA? The answer is no—deterministic PDAs cannot accept every pushdown language, so they are strictly less powerful than nondeterministic PDAs. Why might this be the case? First, let’s consider a definition for deterministic pushdown automata.
A deterministic pushdown automaton (DPDA) is a PDA $M = (Q,\Sigma,\Gamma,\delta,q_0,Z_0,F)$ with the following additional conditions on its transition function:
- $|\delta(q,a,X)| \leq 1$ for all $q \in Q, a \in \Sigma \cup \{\varepsilon\}, X \in \Gamma$, and
- for all $q \in Q$ and $X \in \Gamma$, if $\delta(q,\varepsilon,X) \neq \emptyset$, then $\delta(q,a,X) = \emptyset$ for all $a \in \Sigma$.
The class of languages accepted by DPDAs by final state are the deterministic pushdown languages.
The effect of this restriction is that every $\delta(q,a,X)$ transition has at most one output “action” $(q', \gamma)$. The second restriction concerns $\varepsilon$-transitions: we want to allow stack-driven $\varepsilon$-transitions, but we must disallow any input consumption on the same state and stack symbol, since otherwise a machine may have a choice of consuming input or not.
Let’s see an example of a language that is pushdown but not deterministic pushdown.
Recall that a palindrome is a string that can be read the same forwards or backwards. That is, $w = w^R$. Consider the language of palindromes,
$$L_{\mathsf{Pal}} = \{w \in \{a,b\}^* \mid w = w^R \}.$$
The idea is quite simple: we can read $w$ and keep track of it on the stack until we reach halfway through the string. Once we do that, we just need to make sure that the rest of the word matches the reverse of $w$. Luckily, this is exactly how stacks work. However, there’s a problem: how do we know we’re halfway?
Since we have a nondeterministic machine, we are able to guess when we’re halfway.
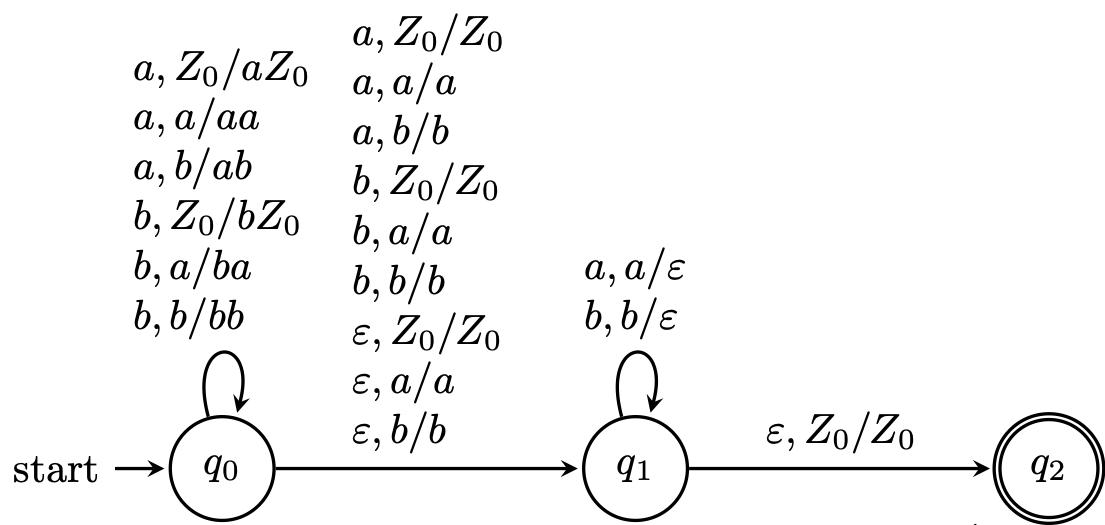
\begin{tikzpicture}[node distance=3.5cm,thick,auto]
\node[state,initial] (0) {$q_0$};
\node[state] (1) [right of=0]{$q_1$};
\node[state,accepting] (2) [right of=1] {$q_2$};
\path[->]
(0) edge [loop above] node [align=left] {$a,Z_0/aZ_0$ \\ $a,a/aa$ \\ $a,b/ab$ \\ $b,Z_0/bZ_0$ \\ $b,a/ba$ \\ $b,b/bb$} (0)
(0) edge node [align=left] {$a,Z_0/Z_0$ \\ $a,a/a$ \\ $a,b/b$ \\ $b,Z_0/Z_0$ \\ $b,a/a$ \\ $b,b/b$ \\ $\varepsilon, Z_0/Z_0$ \\ $\varepsilon,a/a$ \\ $\varepsilon,b/b$} (1)
(1) edge [loop above] node [align=left] {$a,a/\varepsilon$ \\ $b,b/\varepsilon$} (1)
(1) edge node [align=left] {$\varepsilon,Z_0/Z_0$} (2)
;
\end{tikzpicture}
from automata.pda.npda import NPDA
A = NPDA(
states=set(range(3)),
input_symbols=set('ab'),
stack_symbols=set('abZ'),
transitions={
0: {
'a': {
'Z': {(0, 'aZ'), (1, 'Z')},
'a': {(0, 'aa'), (1, 'a')},
'b': {(0, 'ab'), (1, 'b')}
},
'b': {
'Z': {(0, 'bZ'), (1, 'Z')},
'a': {(0, 'ba'), (1, 'a')},
'b': {(0, 'bb'), (1, 'b')}
},
'': {
'Z': {(1, 'Z')},
'a': {(1, 'a')},
'b': {(1, 'b')}
}
},
1: {
'a': {'a': {(1, '')}},
'b': {'b': {(1, '')}},
'': {'Z': {(2, 'Z')}}
}
},
initial_state=0,
initial_stack_symbol='Z',
final_states={2}
)
Here, our machine reads the first half of the string in $q_0$ and stores it on the stack. It nondeterministically guesses the middle of the string, which is a symbol if the palindrome is odd and $\varepsilon$ if the palindrome is even, and does not modify the stack. This guess moves the machine to state $q_1$, where it tries to match each symbol with what’s stored on the stack. If the stack is emptied, this means we have successfully read the second half of the string that matches the reverse of the first half, and we may move to $q_2$ to accept.
Like the example above, processing the latter part of the word depends on what is on the stack. If the lengths of the stack and the second half of the word don’t match up, then the machine crashes. Similarly, if a symbol is read that doesn’t match what’s on the stack, then the machine crashes.
Here, we trace one possible computation of the word $abba$,
\begin{align*}
(q_0,abba,Z_0) &\vdash (q_0,bba,aZ_0) \vdash (q_0,ba,baZ_0) \\
&\vdash (q_1,ba,baZ_0) \vdash (q_1,a,aZ_0) \vdash (q_1,\varepsilon,Z_0) \\
&\vdash (q_2,\varepsilon,Z_0).
\end{align*}
Here is a computation on the same word that fails,
\[(q_0,abba,Z_0) \vdash (q_0,bba,aZ_0) \vdash (q_0,ba,baZ_0) \vdash (q_0,a,bbaZ_0) \vdash (q_1,a,bbaZ_0).\]
Since there is no transition in $q_1$ on input symbol $a$ and stack symbol $b$, our computation crashes at this point.
Here is the entire set of possible configurations:
>>> for i, c in enumerate(A.read_input_stepwise('abba')):
... print(f'Step {i}: {c}')
...
Step 0: {PDAConfiguration(0, 'abba', PDAStack(('Z',)))}
Step 1: {PDAConfiguration(1, 'bba', PDAStack(('Z',))),
PDAConfiguration(1, 'abba', PDAStack(('Z',))),
PDAConfiguration(0, 'bba', PDAStack(('Z', 'a')))}
Step 2: {PDAConfiguration(1, 'bba', PDAStack(('Z', 'a'))),
PDAConfiguration(0, 'ba', PDAStack(('Z', 'a', 'b'))),
PDAConfiguration(1, 'ba', PDAStack(('Z', 'a'))),
PDAConfiguration(2, 'abba', PDAStack(('Z',))),
PDAConfiguration(2, 'bba', PDAStack(('Z',)))}
Step 3: {PDAConfiguration(0, 'a', PDAStack(('Z', 'a', 'b', 'b'))),
PDAConfiguration(1, 'ba', PDAStack(('Z', 'a', 'b'))),
PDAConfiguration(1, 'a', PDAStack(('Z', 'a', 'b')))}
Step 4: {PDAConfiguration(1, '', PDAStack(('Z', 'a', 'b', 'b'))),
PDAConfiguration(0, '', PDAStack(('Z', 'a', 'b', 'b', 'a'))),
PDAConfiguration(1, 'a', PDAStack(('Z', 'a', 'b', 'b'))),
PDAConfiguration(1, 'a', PDAStack(('Z', 'a')))}
Step 5: {PDAConfiguration(1, '', PDAStack(('Z',))),
PDAConfiguration(1, '', PDAStack(('Z', 'a', 'b', 'b', 'a')))}
Step 6: {PDAConfiguration(2, '', PDAStack(('Z',)))}
This machine relies very heavily on nondeterminism to guess the middle of the string, as well as what form the middle should take (depending on whether the string is ultimately of even or odd length). Intuitively, what we see is that it is not possible to tell whether a string is in the front or back half of the string while reading it only based on the portion of the string that is read or if it’s even or odd.
Computation by stack
Another way to think about why there is a difference between the deterministic and nondeterministic models is to think about how the two models need to work with the stack. The ability to remember an unbounded amount of information is quite powerful, but there are restrictions on how we can access this power.
We will see that nondeterminism allows us to exploit the stack in ways that are impossible with determinism. Just how much power does the combination of nondeterminism and the stack give us? We’ll see that in fact, we don’t need any states at all (well, technically just one state), and we can do all of our computation on the stack.
Let $A$ be a PDA. There exists an equivalent PDA $A'$ with one state that accepts by empty stack
Let $A = (Q, \Sigma, \Gamma, \delta, q_0, Z_0)$. We assume that $A$ accepts by empty stack, since otherwise we can simply transform it into an equivalent machine that accepts by empty stack. We define the new single state PDA $A' = (Q', \Sigma, \Gamma', \delta', q_0', Z_0’)$ by
- $Q' = \{r\}$,
- $\Gamma' = Q \times \Gamma \times Q$,
- $q_0' = r$,
and the transition function $\delta'$ is defined so that for each $q \in Q$, $a \in \Sigma$, and $X \in \Gamma$,
- for each transition $(q, \varepsilon) \in \delta(p,a,X)$ where $q \in Q$, we add the transition
\[(r, \varepsilon) \in \delta'(r,a,\langle p, X, q\rangle),\]
- and for each transition $(q, Y_1 Y_2 \cdots Y_k) \in \delta(p,a,X)$, we add the transition
\[(r, \langle q, Y_1, q_1 \rangle \langle q_1, Y_2, q_2 \rangle \cdots \langle q_{k-1}, Y_k, q_k \rangle) \in \delta'(r,a,\langle p, X, q_k\rangle)\]
for every $q_1, q_2, \dots, q_k \in Q$.
and we add also
\[\delta'(r,\varepsilon,Z_0') = \{(r,\langle q_0, Z_0, q \rangle) \mid q \in Q\}.\]
Since our new PDA only has one state, the computation must necessarily be driven entirely by the stack. In other words, the stack must maintain information about the current state of the machine as well as the contents of the stack.
To do so, we define the stack alphabet to be triples of the form $\langle p, X, q \rangle$, where $p,q \in Q$ and $X \in \Gamma$. Each stack symbol represents a computation of $A$ that if begun at state $p$ with only $X$ on the stack will end at state $q$ with an empty stack. The effect of this is that if $X$ is on top of a nonempty stack, such a computation “clears” $X$ and anything that it would have added over the course of computation. That is, $(p,xw,X\gamma) \vdash (p,w,\gamma)$ for some string $x$.
We have two types of transitions. The first are transitions that only remove items from the stack and do not push any items onto the stack. These transitions have the form $(q,\varepsilon) \in \delta(p,a,X)$. For each such transition, we add the transition
\[(r,\varepsilon) \in \delta'(r, a, \langle p, X, q \rangle).\]
The second type of transition are those that add items to the stack. If a transition adds $k$ items $Y_1, \dots, Y_k$ to the stack, we simultaneously guess a sequence of $k$ states such that
So for a transition $(q, Y_1 Y_2 \cdots Y_k) \in \delta(p, a, X)$, we add transitions
\[(r,\langle q, Y_1, q_1 \rangle \langle q_1 Y_2 q_2 \rangle \cdots \langle q_{k-1} Y_k q_k \rangle) \in \delta'(r, a, \langle p, X, q \rangle)\]
for all possible $q_1, q_2, \dots, q_k \in Q$.
Let’s examine what this transition means. Recall that we have just performed the computation step
\[(p,au,X) \vdash (q, u, Y_1 Y_2 \cdots Y_k).\]
If we proceed from this configuration, we pop $Y_1$, but this does not leave us with a stack with $Y_2$ on the top. The transition on $Y_1$ could leave us with even more stuff on the stack, like
\[(q, u, Y_1 Y_2 \cdots Y_k) \vdash (q', u', Z_1 Z_2 \cdots Z_\ell Y_2 \cdots Y_k).\]
Now, at this point, it seems like it’s impossible to tell what will happen next because we can add any number of items to the stack. However, recall that our machine needs to accept by empty stack. So if our computation is really headed for acceptance, it must eventually clear the stack out. In other words, anything that gets added to the stack needs to be removed eventually in an accepting computation.
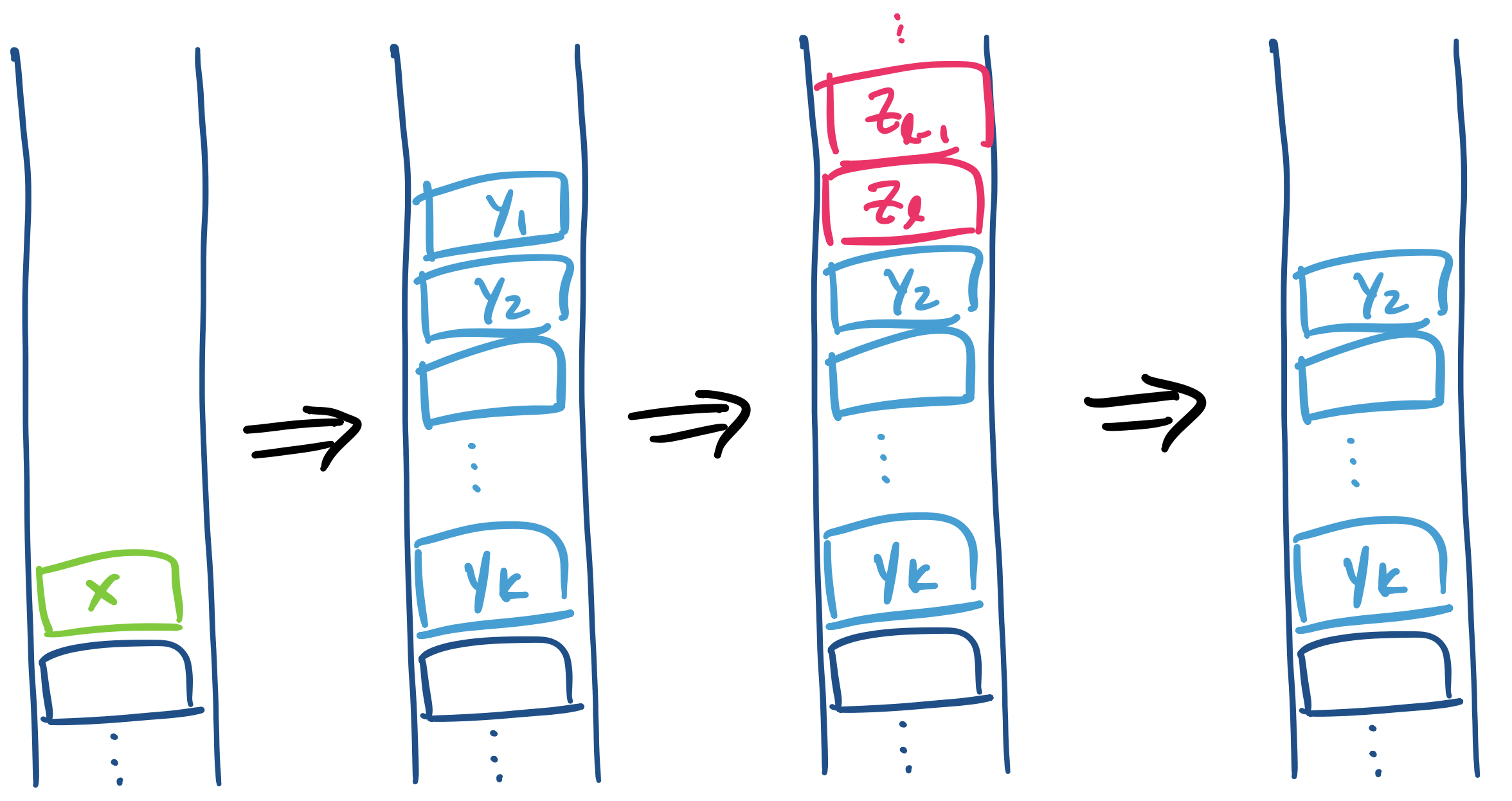
So we know that $Y_2$ must return to the top of the stack at some point. How much of the input string have we read at that point? What is the state that the PDA is in at that point? Those are things that we don’t know, but have to guess:
\[(q, u, Y_1 Y_2 \cdots Y_k) \vdash^* (q_1, u', Y_2 \cdots Y_k).\]
In essence, we should think of the symbol $\langle p, X, q \rangle$ primarily as being about clearing out $X$ off of the stack. The states at which it begins and ends this process is a detail that we fill in after the fact by considering all possible sequences of states $q_1, \dots, q_k$ such that we can pop $Y_1, \dots, Y_k$.
The formal claim here is that $(p, x, Y_1 Y_2 \cdots Y_k) \vdash^*_A (q, \varepsilon, \varepsilon)$ if and only if there exist states $q_1, q_2, \dots, q_k$ such that $(r, x, \langle q, Y_1, q_1 \rangle \langle q_1, Y_2, q_2 \rangle \cdots \langle q_{k-1}, Y_k, q_k \rangle ) \vdash^*_{A'} (r, \varepsilon, \varepsilon)$. Kozen Chapter 25 contains the full details of the induction.
This actually puts us in a bit of a pickle. Though we have a model of computation for languages beyond regular languages, there is a choice to be made: deterministic vs. nondeterministic. One the one hand, the deterministic model is more realistic, in the sense that real computers and real algorithms are deterministic. However, the nondeterministic model allows us to recognize languages of interest. What is the right move?
As before with recognizable languages and finite automata, we have not yet really homed in on the languages themselves. While the pushdown automata and the notion of a stack gives us some insight into the capabilities and limits of computation, we have a relatively vague grasp of the structure of the languages that they can recognize. So we should step back and explore an alternative description for these languages.