At last, we’re ready to step beyond the comfortable world of regular languages and finite automata. But how far outside should we tread? And how should we begin our exploration of the world beyond regularity?
Let’s think back to the finite automaton model. One of the recurring questions we asked was what would happen if we modified our model. In general, this is a central question in automata theory: Given a particular machine model, what modifications can we make to the model and do these modifications change the power of the model?
From our discussion of finite automata and regular languages, we can conclude that anything that will take us out of the class of regular languages will necessarily involve allowing a possibly infinite amount of memory.
If we think back to the Turing machine model, we still have a finite instruction set, represented by a set of states. The difference is the ability to read, write, and move along the tape. We are not quite ready to jump right to “full” computation yet, so any modification we make will have to be “in between” complete access to unlimited memory and finite memory.
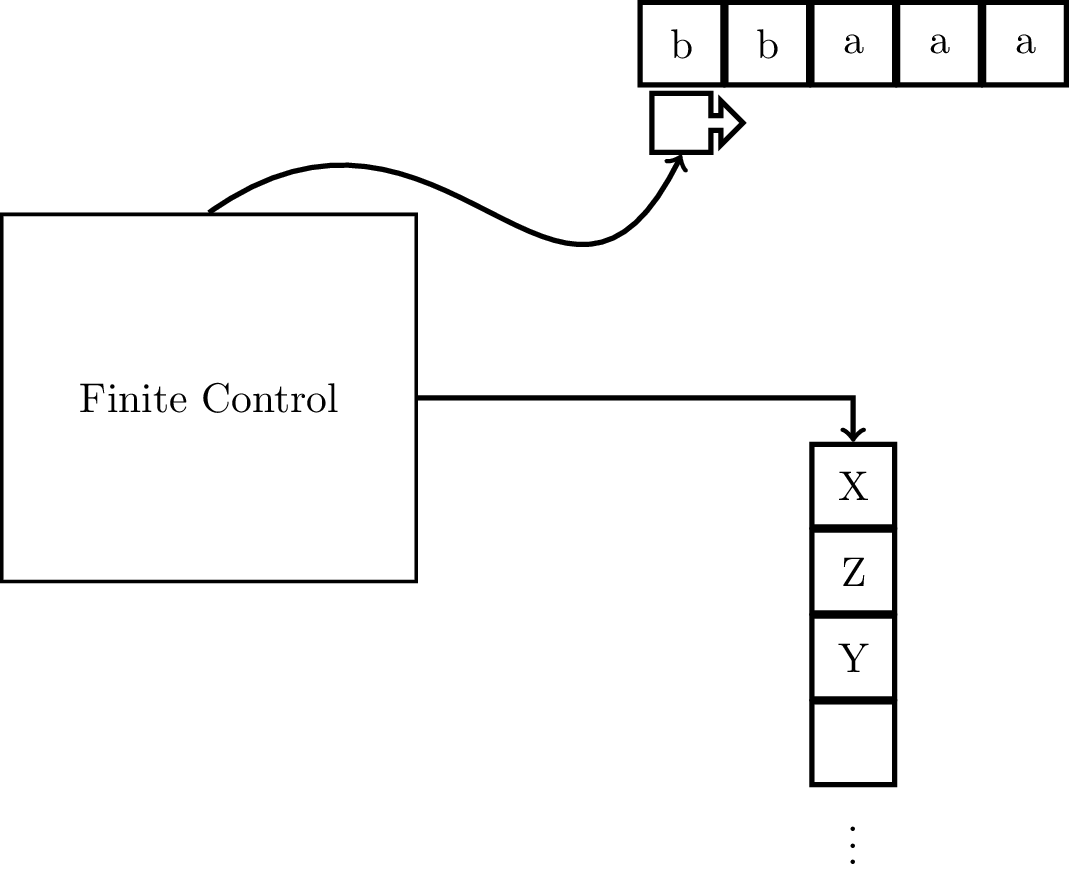
This suggests that we want to augment our finite automaton model with a data structure that may have unbounded memory but controls access to this memory. The structure we will use is a stack.
A stack (sometimes called a pushdown store) is a data structure with two operations,
A consequence of this definition is that the only item that is accessible is the item on the “top” of the stack. So these are called stacks because of the analogy piling a stack of (plates/books/papers/to-do items). You add items to your metaphorical stack by putting stuff on top and you can only remove items from your stack by taking things off the top.
The effect of this is that stacks give access to the items that are most recent. For this reason, stacks are also called last-in, first-out structures. So while stacks have unlimited memory, our access to the contents of the stack is limited. A stack can be thought of as a “shallow” form of memory, where we have immediate access only to the most recent items that were placed in the stack.
It is for this reason that stacks are a reasonable choice for a “not-too-powerful” extension of the finite automaton model. We will see that this is a meaningful restriction of power and this will have consequences on the structure of the kinds of languages our machine may recognize.
What then does our augmented machine model look like? We have an NFA that, in addition to reading the input also has access to a stack to which it may push and from which it may pop items. Since it has access to a stack, it is called a pushdown automaton.
The idea is that when you read a symbol on the input tape, you also take a symbol off of the stack. The transition depends on three pieces of information: the symbol you read on the input tape, the current state, and the symbol on the top of the stack. These determine what the next state is and what gets put onto the stack.
Pushdown automata were first defined in Oettinger (1961) and Schützenberger (1963). Around this time, research into formal languages and automata theory was picking up and there were all sorts of investigations into modifications and restrictions on automata and their relationship with machine translation. The pushdown automaton is one result of these kinds of questions being pursued.
A pushdown automaton (PDA) is a 7-tuple $M = (Q,\Sigma,\Gamma,\delta,q_0,Z_0,F)$, where
There are some things to point out about this definition.
Because of the added complexity of representing the stack, some like to treat $\delta$ as a relation instead, which is what Kozen does. In this view, $\delta \subseteq (Q \times (\Sigma \cup \{\varepsilon\}) \times \Gamma) \times (Q \times \Gamma^*)$ is a finite relation on $Q \times (\Sigma \cup \{\varepsilon\}) \times \Gamma$ and $Q \times \Gamma^*$. So a transition $$((q,a,X),(q',Y_1 Y_2 \cdots Y_k)) \in \delta$$ is equivalent to saying that $(q',Y_1 Y_2 \cdots Y_k) \in \delta(q,a,X)$, where $q,q' \in Q$, $a \in \Sigma \cup \{\varepsilon\}$, and $X, Y_1, \dots, Y_k \in \Gamma$. Of course, functions are really just special kinds of relations, so in the end, this is just a difference in notational preference (personally speaking, Kozen was the first textbook I’ve seen that does this).
As with finite automata, we can enumerate the parts of the PDA.
\begin{tikzpicture}[node distance=3cm,thick,auto]
\node[state,initial] (0) {$q_0$};
\node[state] (1) [right of=0]{$q_1$};
\node[state,accepting] (2) [right of=1] {$q_2$};
\path[->]
(0) edge [loop above] node [align=left] {$a,Z_0/XZ_0$ \\ $a,X/XX$} (0)
(0) edge node [align=left] {$\varepsilon,Z_0/Z_0$ \\ $b,X/\varepsilon$} (1)
(1) edge [loop above] node {$b,X/\varepsilon$} (1)
(1) edge node [align=left] {$\varepsilon,Z_0/Z_0$} (2)
;
\end{tikzpicture}
We write transitions in the following way: $$\delta(q,a,X) = \{(q_1,\alpha_1), \dots, (q_n,\alpha_n)\}$$ where $q,q_1,\dots,q_n \in Q$, $a \in \Sigma$, $X \in \Gamma$, and $\alpha_1,\dots,\alpha_n \in \Gamma^*$.
Since $\alpha_i$ is a string, it’s important to note the order in which we push symbols onto the stack. If $\alpha_i = X_1 X_2 \cdots X_k$ where $X_j \in \Gamma$, $X_k$ gets pushed onto the stack first and after all of $\alpha_i$ is pushed onto the stack, $X_1$ is on the top of the stack. In other words, the top of the stack should look like we just took $\alpha_i$ and turned it 90 degrees so that $X_k$ is at the bottom and $X_1$ is at the top.
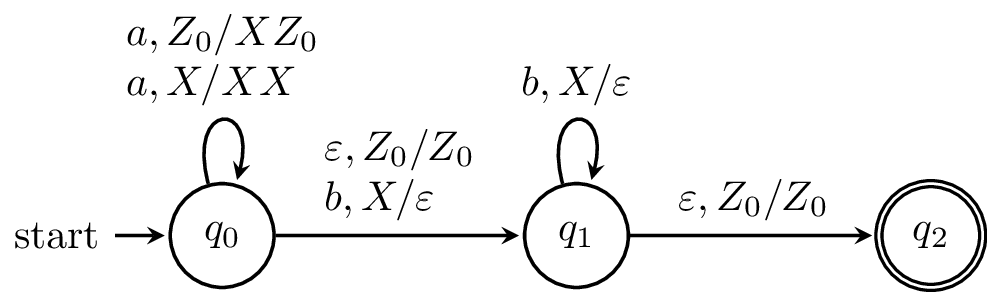
As an example, we write one of the transitions from the above machine as $$\delta(q_0,a,Z_0) = \{(q_0,XZ_0)\}.$$
Of course, as with NFAs, listing the entire transition function explicitly can be quite cumbersome. Also, note that just like for NFAs, we can draw a state diagram for a PDA. The idea is mostly the same, but the difference is how to denote the changes to the stack. For a transition $(q',\alpha) \in \delta(q,a,X)$ we label the transition from $q$ to $q'$ by $a,X/\alpha$.
An equivalent definition in the automata library is as follows.
from automata.pda.npda import NPDA
A = NPDA(
states=set(range(3)),
input_symbols=set('ab'),
stack_symbols=set('XZ'),
transitions={
0: {
'': {'Z': {(1, 'Z')}},
'a': {
'Z': {(0, 'XZ')},
'X': {(0, 'XX')}
},
'b': {'X': {(1, '')}}
},
1: {
'b': {'X': {(1, '')}},
'': {'Z': {(2, 'Z')}}
}
},
initial_state=0,
initial_stack_symbol='Z',
final_states={2}
)
What does this PDA do? The PDA begins by reading $a$’s and for each $a$ that’s read, an $X$ is put on the stack. Then, once a $b$ is read, and the computation moves onto the next state. For every $b$ that is read, an $X$ is taken off the stack. The machine can only reach the final state if the stack is empty and there is no more input to be read.
As with the NFA, if a transition is undefined, we assume that it goes to the empty set (since the image of the transition function is subsets of $Q \times \Gamma^*$). In practice, we treat this as the machine crashing. For a PDA, in addition to not having transitions defined on a state and symbol, we must also take into consideration the symbol that we pop from the stack. One particular case of this is when we try to pop an element off of an empty stack (this is undefined, so we go to the empty set).
Here, we have a PDA that we claim recognizes the language $\{a^k b^k \mid k \geq 0\}$. In order to verify our claim, we’ll need to formalize notions of what it means for a PDA to “recognize” or “accept” a language. And in order to do that, we’ll need to formalize the notion of what it means for a word to move through a PDA.
Describing the computation of an NFA was simple, since it’s really just a path through a directed graph and all we needed to know to describe what the state of the NFA was is how far in the input string the NFA is and what state(s) the NFA is on. With the PDA, there is one more piece of information that we need to take into account: the stack.
The existence of the stack complicates things in a few ways. We can no longer make the assumption that progression along the input string lines up with a sequence of states. This is because computations can be driven by the stack: it is possible for a computation to progress without consuming more of the input. For instance, a PDA may have transitions of the form $(q, \varepsilon, X)$, where no input is consumed, but moves may be made based on the contents of the stack. At the same time, a transition may push many items on the stack.
So to describe the “state” of a PDA during a computation, we will need to know not only the current state, but we also need to know the stack contents, as well as how much of the input string has already been read.
The description of the state of a PDA is called the configuration of a PDA and it is a 3-tuple $(q,x,\gamma)$, where
Now, we want to describe transitions from one configuration to another in the PDA.
We define the relation $\vdash$ on configurations by $(q,ax, X\gamma) \vdash (q',x,\beta\gamma)$ if and only if $(q',\beta) \in \delta(q,a,X)$. We can then define the closure of $\vdash$ by
A computation in a PDA $P$ is a sequence of configurations $C_1, C_2, \dots, C_n$, where $C_1 \vdash C_2 \vdash \cdots \vdash C_n$.
Here, we have the following configurations of our machine as it reads the string $aabb$.
>>> for i, c in enumerate(A.read_input_stepwise('aabb')):
... print(f'Step {i}: {c}')
...
Step 0: {PDAConfiguration(0, 'aabb', PDAStack(('Z',)))}
Step 1: {PDAConfiguration(0, 'abb', PDAStack(('Z', 'X'))),
PDAConfiguration(1, 'aabb', PDAStack(('Z',)))}
Step 2: {PDAConfiguration(0, 'bb', PDAStack(('Z', 'X', 'X'))),
PDAConfiguration(2, 'aabb', PDAStack(('Z',)))}
Step 3: {PDAConfiguration(1, 'b', PDAStack(('Z', 'X')))}
Step 4: {PDAConfiguration(1, '', PDAStack(('Z',)))}
Step 5: {PDAConfiguration(2, '', PDAStack(('Z',)))}
One thing to be aware of when using the automata library is that it represents the stack contents with the top of the stack on the right, while we represent stacks as strings with the left representing the top of the stack.
Notice that because transitions are nondeterministic, there are some steps that result in computations that don’t “make it”. However, we can trace out an accepting computation: \[(0, aabb, Z_0) \vdash (0, abb, XZ_0) \vdash (0, bb, XXZ_0) \vdash (1, b, XZ_0) \vdash (1, \varepsilon, Z_0) \vdash (2, \varepsilon, Z_0).\]
This string should be accepted, but we need to discuss what this means formally.
We want to say that strings that get accepted have accepting computations, but we need to be clear about what this means. Recall that for NFAs, we defined this to be all strings $w \in \Sigma^*$ such that $\delta(q_0, w) \cap F \neq \emptyset$. This was fine, since a computation on an NFA was just a sequence of states. But computations on PDAs are more complicated, so we have more possibilities.
If we consider acceptance on a PDA in the same way as an NFA, we want to be able to express the idea of “being in a final state after having read the entire string”. We get the following definition.
We say a PDA $P$ accepts a word $x$ by final state if $(q_0,x,Z_0) \vdash^* (q,\varepsilon, \gamma)$ for some $q \in F$ and $\gamma \in \Gamma^*$. The language of a PDA $P$ that accepts by final state is $$ L(P) = \{w \in \Sigma^* \mid \exists q \in F, \gamma \in \Gamma^*, (q_0, w, Z_0) \vdash^* (q, \varepsilon, \gamma)\}.$$
The class of languages accepted by pushdown automata are the pushdown languages.
Let’s look at the PDA from earlier again.
We had traced a computation on the word $aabb$, starting in the initial configuration $(q_0,aabb,Z_0)$: $$(q_0,aabb,Z_0) \vdash (q_0,abb,XZ_0) \vdash (q_0,bb,XXZ_0) \vdash (q_1,b,XZ_0) \vdash (q_1,\varepsilon,Z_0) \vdash (q_2,\varepsilon,Z_0).$$ Our final configuration is $(q_2, \varepsilon, Z_0)$. At this point, we have consumed the input string and are in $q_2 \in F$, so our input string is accepted.
Note that the definition of the transition function prevents any other word from reaching the final state. For instance, $a$’s can’t be read after moving to $q_1$, otherwise the machine will crash. Similarly, if a $b$ is read and there are is no corresponding stack symbol, the machine crashes, and a $\varepsilon$-transition can only be taken to reach the final state if the stack is empty.
Notice that in the above, we were careful to say that we were defining acceptance by final state. This implies that this is not the only model of acceptance for pushdown automata. An observation you may have made in our discussion so far is that the stack plays a significant role in computation in pushdown automata.
Something that often feels like a necessity for acceptance is for the stack to be empty. Under our definition for acceptance by final state, this is not a requirement. However, we can define an alternative mode of acceptance, where rather than have acceptance be determined by states, we have acceptance determined by the status of the stack.
Let $P$ be a PDA. Then we define the language $$ N(P) = \{w \in \Sigma^* \mid \exists q \in Q, (q_0, w, Z_0) \vdash^* (q,\varepsilon,\varepsilon) \}.$$ The language $N(P)$ is the language of the PDA $P$ under acceptance by empty stack.
In other words, we accept a word if the stack is empty after reading it. Obviously, under this model, final states are superfluous, so PDAs using this acceptance model can be described by a 6-tuple instead.
A classical language problem, especially for computer scientists and programmers, is identifying strings of balanced brackets. Intuitively, a string of brackets (i.e. a string over the alphabet of brackets $\{\mathtt [, \mathtt ]\}$) is balanced if they are “closed properly”. So strings like $\mathtt{[[]]}$ and $\mathtt{[][]}$ are balanced but $\mathtt{[]]}$ and $\mathtt{[[][}$ are not. One can give an inductive definition for strings of balanced brackets.
Suppose $w \in \{\mathtt [, \mathtt ]\}^*$. Then $w$ is balanced if
Determining whether a string of brackets is balanced is a common programming exercise to introduce someone to the idea of stacks. Conveniently, we are dealing with a machine that has a stack. The idea is that we want to have one closing bracket for each opening bracket with the additional constraint that we should only close something that is open.
The strategy is that for each open bracket we see, push it on the stack, and for each closing bracket we see, we need to be able to match it to an open bracket on the stack. If we see a closing bracket and there is nothing on the stack, then there is no open bracket waiting to be closed and our string is not balanced.
Here, we will give a PDA that accepts by empty stack.
from automata.pda.npda import NPDA
A = NPDA(
states={0},
input_symbols=set('[]'),
stack_symbols=set('[Z'),
transitions={
0: {
'': {'Z': {(0, '')}},
'[': {
'Z': {(0, '[Z')},
'[': {(0, '[[')}
},
']': {'[': {(0, '')}}
}
},
initial_state=0,
initial_stack_symbol='Z',
final_states=set(),
acceptance_mode='empty_stack'
)
Observe that this machine consists of only a single state, with transitions labelled
Notice that we still need a bottom of stack symbol in case we want to start a new string of balanced brackets, as in the string $\mathtt{[][]}$. Otherwise, we would empty the stack without having read the entire string.
>>> for i, c in enumerate(A.read_input_stepwise('[][[]]')):
... print(f'Step {i}: {c}')
Step 0: {PDAConfiguration(0, '[][[]]', PDAStack(('Z',)))}
Step 1: {PDAConfiguration(0, '][[]]', PDAStack(('Z', '['))),
PDAConfiguration(0, '[][[]]', PDAStack(()))}
Step 2: {PDAConfiguration(0, '[[]]', PDAStack(('Z',)))}
Step 3: {PDAConfiguration(0, '[[]]', PDAStack(())),
PDAConfiguration(0, '[]]', PDAStack(('Z', '[')))}
Step 4: {PDAConfiguration(0, ']]', PDAStack(('Z', '[', '[')))}
Step 5: {PDAConfiguration(0, ']', PDAStack(('Z', '[')))}
Step 6: {PDAConfiguration(0, '', PDAStack(('Z',)))}
Step 7: {PDAConfiguration(0, '', PDAStack(()))}
So an accepting computation for this string would be \begin{align*} (0, \mathtt{[][[]]}, Z_0) &\vdash (0, \mathtt{][[]]}, \mathtt{[}Z_0) \\ &\vdash (0, \mathtt{[[]]}, Z_0) \\ &\vdash (0, \mathtt{[]]}, \mathtt{[}Z_0) \\ &\vdash (0, \mathtt{]]}, \mathtt{[[}Z_0) \\ &\vdash (0, \mathtt{]}, \mathtt{[}Z_0) \\ &\vdash (0, \varepsilon, Z_0) \\ &\vdash (0, \varepsilon, \varepsilon) \end{align*}
An interesting question to consider is whether these acceptance modes are the same. That is, is it always possible to transform a PDA that accepts by final state into an equivalent one that accepts by empty stack, and vice-versa?