From last time, we defined the derivative of a regular expression $\mathbf r$ with respect to a symbol $a \in \Sigma$ in the following way: \begin{align*} \frac{d}{da}\mathtt a &= \epsilon, &\frac{d}{da}\mathtt b &= \varnothing \text{ for $b \in \Sigma$ and $b \neq a$}, &\frac{d}{da}\epsilon &= \varnothing, &\frac{d}{da}\varnothing &= \varnothing, \end{align*} and for regular expressions $\mathbf r_1$ and $\mathbf r_2$, \begin{align*} &\frac{d}{da}\left(\mathbf r_1 + \mathbf r_2\right) =& \frac{d}{da}\mathbf r_1 + \frac{d}{da}\mathbf r_2,& \\ &\frac{d}{da}\mathbf r_1\mathbf r_2 =& \left(\frac{d}{da}\mathbf r_1\right) \mathbf r_2 + \mathsf c\left(\mathbf r_1\right) \frac{d}{da}\mathbf r_2,& \text{ and } \\ &\frac{d}{da}\mathbf r_1^* =& \left(\frac{d}{da}\mathbf r_1\right) \mathbf r_1^*.& \end{align*}
This definition is essentially a recursive algorithm and we can apply it to compute a regular expression. We want to show that this expression describes the quotient $a^{-1} L(\mathbf r) = \{x \in \Sigma^* \mid ax \in L\left(\mathbf r\right)\}$.
Let $\mathbf r$ be a regular expression and let $a \in \Sigma$ be a symbol. Then, $$L\left(\frac{d}{da}\mathbf r\right) = a^{-1} L\left(\mathbf r\right) = \{x \in \Sigma^* \mid ax \in L\left(\mathbf r\right)\}.$$
We will prove this by induction on $\mathbf r$.
For the base cases, we have the following
Now, let $\mathbf s$ and $\mathbf t$ be regular expressions and assume that for all $a \in \Sigma$, $L\left(\frac{d}{da}\mathbf s\right) = a^{-1}L\left(\mathbf s\right)$ and $L\left(\frac{d}{da}\mathbf t\right) = a^{-1}L\left(\mathbf t\right)$.
First, we have $\mathbf r = \mathbf s + \mathbf t$: \begin{align*} L\left(\frac{d}{da}\left(\mathbf s + \mathbf t\right)\right) &= L\left(\frac{d}{da}\mathbf s+ \frac{d}{da}\mathbf t\right) \\ &= L\left(\frac{d}{da}\mathbf s\right) \cup L\left(\frac{d}{da}\mathbf t\right) \\ &= a^{-1} L\left(\mathbf s\right) \cup a^{-1} L\left(\mathbf t\right) \\ &= \{x \in \Sigma^* \mid ax \in L\left(\mathbf s\right)\} \cup \{x \in \Sigma^* \mid ax \in L\left(\mathbf t\right)\} \\ &= \{x \in \Sigma^* \mid ax \in L\left(\mathbf s\right) \cup L\left(\mathbf t\right)\} \\ &= \{x \in \Sigma^* \mid ax \in L\left(\mathbf s + \mathbf t\right)\} \\ &= a^{-1} L\left(\mathbf s + \mathbf t\right) \end{align*}
Next, we have $\mathbf r = \mathbf s \mathbf t$. We will define $L\left(\mathbf s\right)^\circ = L\left(\mathbf s\right) - \{\varepsilon\}$. Note that $L\left(\mathbf s\right) = L\left(\mathbf s\right)^\circ \cup L\left(\mathsf c\left(\mathbf s\right)\right)$. First, we try to transform $a^{-1}L(\mathbf{st})$. \begin{align*} a^{-1} L\left(\mathbf s \mathbf t\right) &= \{x \in \Sigma^* \mid ax \in L\left(\mathbf s\right)L\left(\mathbf t\right)\} \\ &= \{x \in \Sigma^* \mid ax \in \left(L\left(\mathbf s\right)^\circ \cup L\left(\mathsf c\left(\mathbf s\right)\right)\right) L\left(\mathbf t\right)\} \\ &= \{x \in \Sigma^* \mid ax \in \left(L\left(\mathbf s\right)^\circ L\left(\mathbf t\right) \cup L\left(\mathsf c\left(\mathbf s\right)\right) L\left(\mathbf t\right)\right)\} \\ &= \{x \in \Sigma^* \mid ax \in L\left(\mathbf s\right)^\circ L\left(\mathbf t\right)\} \cup \{x \in \Sigma^* \mid ax \in L\left(\mathsf c\left(\mathbf s\right)\right) L\left(\mathbf t\right)\} \\ &= \{uv \in \Sigma^* \mid au \in L\left(\mathbf s\right)^\circ, v \in L\left(\mathbf t\right)\} \cup \{v \in \Sigma^* \mid \varepsilon \in L(\mathsf c(\mathbf s)), av \in L(\mathbf t)\} \\ &= \left(a^{-1} L\left(\mathbf s\right)^\circ\right) L\left(\mathbf t\right) \cup L(\mathsf c(\mathbf s)) a^{-1} L\left(\mathbf t\right) \end{align*} There are two observations that we need to justify at this point.
Putting this together, we continue, to get the following: \begin{align*} a^{-1} L\left(\mathbf s \mathbf t\right) &= \left(a^{-1} L\left(\mathbf s\right)^\circ\right) L\left(\mathbf t\right) \cup L(\mathsf c(\mathbf s)) a^{-1} L\left(\mathbf t\right) \\ &= L\left(\left(\frac{d}{da}\mathbf s\right) \mathbf t\right) \cup L\left(\mathsf c\left(\mathbf s\right) \frac{d}{da}\mathbf t\right) \\ &= L\left(\left(\frac{d}{da}\mathbf s\right) \mathbf t + \mathsf c\left(\mathbf s\right) \frac{d}{da}\mathbf t\right) \\ &= L\left(\frac{d}{da}\mathbf s \mathbf t\right) \end{align*}
Therefore, $L\left(\frac{d}{da}\mathbf s \mathbf t\right) = a^{-1}L\left(\mathbf s \mathbf t\right)$.
Finally, we have $\mathbf r = \mathbf s^*$. \begin{align*} L\left(\frac{d}{da}\mathbf s^*\right) &= L\left(\left(\frac{d}{da}\mathbf s\right)\mathbf s^*\right) \\ &= \left(a^{-1}L\left(\mathbf s\right)\right) L\left(\mathbf s^*\right) \\ &= \{xy \in \Sigma^* \mid ax \in L\left(\mathbf s\right), y \in L\left(\mathbf s^*\right)\} \\ &= \{w \in \Sigma^* \mid aw \in L\left(\mathbf s^*\right)\} \\ &= a^{-1} L\left(\mathbf s^*\right) \end{align*}
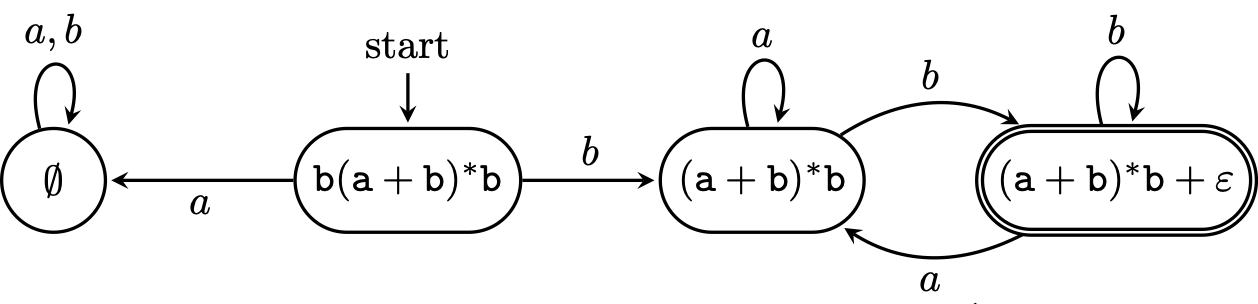
Let's compute the derivatives for the regular expression $\mathbf r = \mathtt{b(a+b)^*b}$. We saw above already that the derivative with respect to $b$ should be $\mathtt{(a+b)^*b}$, but let's verify that using our definition. We have \begin{align*} \frac{d}{db} \mathbf r &= \frac{d}{db} \mathtt{b(a+b)^*b} \\ &= \left(\frac{d}{db}\mathtt b\right) \cdot \mathtt{(a+b)^*b} + \mathsf c(\mathtt b) \cdot \frac{d}{db} \mathtt{(a+b)^*b} \\ &= \epsilon \cdot \mathtt{(a+b)^*b} + \varnothing \cdot \frac{d}{db} \mathtt{(a+b)^*b} \\ &= \mathtt{(a+b)^*b} \end{align*}
Then for $a$, we have \begin{align*} \frac{d}{da} \mathbf r &= \frac{d}{da} \mathtt{b(a+b)^*b} \\ &= \left(\frac{d}{da}\mathtt b\right) \cdot \mathtt{(a+b)^*b} + \mathsf c(\mathtt b) \cdot \frac{d}{da} \mathtt{(a+b)^*b} \\ &= \varnothing \cdot \mathtt{(a+b)^*b} + \varnothing \cdot \frac{d}{da} \mathtt{(a+b)^*b} \\ &= \varnothing \end{align*}
We have now ended up with two regular expressions. But we can continue, taking derivatives of derivatives. Obviously, no matter what we do, we have \[\frac{d}{dx}\left(\frac{d}{da} \mathbf r \right) = \frac{d}{dx} \varnothing = \varnothing = \frac d {da} \mathbf r\] for all $x \in \Sigma$. But we could get something interesting from $\frac d{db} \mathbf r$. For $a$, we have \begin{align*} \frac{d}{da} \left(\frac d{db} \mathbf r \right) &= \frac{d}{da} \mathtt{(a+b)^*b} \\ &= \left(\frac{d}{da} \mathtt{(a+b)^*}\right) \mathtt b + \mathsf c(\mathtt{(a+b)^*}) \frac d{da} \mathtt b \\ &= \left(\frac{d}{da} \mathtt{a+b}\right) \mathtt{(a+b)^*} \mathtt b + \epsilon \cdot \varnothing \\ &= \left(\frac d{da} \mathtt a + \frac d{da} \mathtt{b} \right) \mathtt{(a+b)^*} \mathtt b \\ &= \left(\epsilon + \varnothing \right) \mathtt{(a+b)^*} \mathtt b \\ &= \mathtt{(a+b)^*} \mathtt b \end{align*} Note that this is just $\frac{d}{db} \mathbf r$.
Then for $b$, we will skip some steps we've seen above and we end up with \begin{align*} \frac{d}{db} \left(\frac d{db} \mathbf r \right) &= \frac{d}{db} \mathtt{(a+b)^*b} \\ &= \left(\frac{d}{db} \mathtt{(a+b)^*}\right) \mathtt b + \mathsf c(\mathtt{(a+b)^*}) \frac d{db} \mathtt b \\ &= \left(\frac{d}{db} \mathtt{a+b}\right) \mathtt{(a+b)^*} \mathtt b + \epsilon \cdot \epsilon \\ &= \mathtt{(a+b)^*} \mathtt b + \epsilon \end{align*}
The fact that we can continue to compute derivatives of derivatives suggests that we can define an obvious extension for derivatives to words. Let $w = ax$, where $x \in \Sigma^*$ and $a \in \Sigma^*$. Then $\frac{d}{dw}\mathbf r = \frac{d}{dx}\left(\frac{d}{da}\mathbf r\right)$. This leads to the following very interesting observation.
Let $\mathbf r$ be a regular expression and let $w \in \Sigma^*$. Then $w \in L\left(\mathbf r\right)$ if and only if $\varepsilon \in L\left(\frac{d}{dw}\mathbf r\right)$.
We have $\varepsilon \in L\left(\frac{d}{dw}\mathbf r\right) \iff \varepsilon \in w^{-1} L\left(\mathbf r\right) \iff w \varepsilon \in L\left(\mathbf r\right) \iff w \in L\left(\mathbf r\right).$
This basically gives us an algorithm for testing whether a string $w$ is matched by a regular expression $\mathbf r$. First, compute $\frac{d}{dw} \mathbf r$ recursively using the definition. Then, compute $\mathsf c\left(\frac{d}{dw} \mathbf r \right)$ to determine whether $\varepsilon \in L\left(\frac{d}{dw} \mathbf r\right)$.
Let's see where this idea takes us. We don't yet have any derivatives that match $\varepsilon$, but we still have a derivative we haven't seen before: $\frac d{db} \frac d{db} \mathbf r$, or $\frac d{dbb} \mathbf r$. But since $\frac d{dbb} \mathbf r = \frac d{db} \mathbf r + \varepsilon$, computing the next derivatives is pretty straightforward. We have \begin{align*} \frac{d}{da} \left(\frac d{dbb} \mathbf r \right) &= \frac{d}{da} (\mathtt{(a+b)^*b + \epsilon}) \\ &= \frac{d}{da} \mathtt{(a+b)^*b + \frac d{da} \epsilon} \\ &= \mathtt{(a+b)^*b + \varnothing} \\ &= \mathtt{(a+b)^*} \mathtt b \end{align*} \begin{align*} \frac{d}{db} \left(\frac d{dbb} \mathbf r \right) &= \frac{d}{db} (\mathtt{(a+b)^*b + \epsilon}) \\ &= \frac{d}{db} \mathtt{(a+b)^*b + \frac d{db} \epsilon} \\ &= \mathtt{(a+b)^*b + \epsilon + \varnothing} \\ &= \mathtt{(a+b)^*} \mathtt b + \epsilon \end{align*}
Now, we don't see any new derivatives.
This seems like the right outcome, but when we started this process, we didn't really have any guarantees that we could ever stop. That we got here is not at all obvious. But Brzozowski showed that this is guaranteed to happen.
Every regular expression $\mathbf r$ has a finite number of distinct derivatives.
This has a few implications. First of all, to compute all the derivatives of a regular expression $\mathbf r$, we can do what we've done and just keep on computing them until we start getting the same expressions. Obviously, this is not the most efficient way to do this, but we're guaranteed the computation will stop.
But thinking back to the theoretical point of view, recall that these are sets of suffixes of words in our language. And when we consume prefixes of words belonging to these sets, we get different sets, but there are only finitely many of these sets. And finally, we know that those sets that contain $\varepsilon$ correspond to words in the language. This looks suspiciously like the following.
\begin{tikzpicture}[
node distance=3cm, thick, auto,
state/.append style={rounded rectangle}
]
\node[state,initial above] (0) {$\mathtt{b(a+b)^*b}$};
\node[state] (1) [left of=0]{$\mathtt{\varnothing}$};
\node[state] (2) [right of=0] {$\mathtt{(a+b)^*b}$};
\node[state,accepting] (3) [right of=2]{$\mathtt{(a+b)^*b + \epsilon}$};
\path[->]
(0) edge node {$a$} (1)
(0) edge node {$b$} (2)
(1) edge [loop above] node {$a,b$} (1)
(2) edge [loop above] node {$a$} (2)
(2) edge [bend left] node {$b$} (3)
(3) edge [loop above] node {$b$} (3)
(3) edge [bend left] node {$a$} (2)
;
\end{tikzpicture}
Unlike the Thompson construction we saw before or the position automaton I mentioned briefly, this directly gives us a DFA. However, if we want to use derivatives to compute an NFA, one way to do this was proposed by Antimirov, who, in 1996, defined partial derivatives of a regular expression. This method, like the position automaton that was mentioned earlier, produces an NFA of roughly the same size as the length of the regular expression.
This method lends itself quite nicely to implementation in functional programming languages. Stuart Kurtz's CMSC 28000 course notes on derivatives point to a paper detailing the use of derivatives in the regular expression implementations of Standard ML and Scheme (which you probably know now as Racket).
Personally, I first learned about derivatives as an undergrad stumbling upon Matt Might's post about using derivatives for parsing. It's quite accessible if you have some formal languages and algorithms knowledge. He also has his own implementation of a very simple regular expression matcher that uses derivatives in Scheme, which should be easy enough to follow if you've done some functional programming.