Finite automata and regular expressions
Now, we complete the characterization by showing the other direction: that the language of any DFA is regular. We will do this by showing that we can take any DFA and construct a regular expression that recognizes the same language.
Let $A$ be a DFA. Then there exists a regular expression $\mathbf r$ such that $L(\mathbf r) = L(A)$.
Let $A = (Q,\Sigma,\delta,q_0,F)$ and without loss of generality, let $Q = \{1,2,\dots,n\}$. In other words, we assign each state an integer label from $1$ through $n$.
For each pair of states $p,q \in Q$ and integer $k \leq n$, we define the language $L_{p,q,k}$ to be the language of words for which there is a path from $p$ to $q$ in $A$ consisting only of states with label $\leq k$. In other words, if $w$ is in $L_{p,q,k}$, then for every factorization $w = uv$, we have $\delta(p,u) = r$ such that $r \leq k$ and $\delta(r,v) = q$.
We will show that every language $L_{p,q,k}$ can be defined by a regular expression $\mathbf r_{p,q,k}$. We will show this by induction on $k$. The idea is that we will begin by building regular expressions for paths between states $p$ and $q$ with restrictions on the states that such paths may pass through and inductively build larger expressions from these paths until we acquire an expression that describes all paths through the DFA with no restrictions.
We begin with $k=0$. Since states are numbered $1$ through $n$, we have three cases:
- There is no transition from $p$ to $q$, in which case we have $L_{p,q,0} = \emptyset$. Then $\mathbf r_{p,q,0} = \emptyset$.
- There exists $a_1, a_2, \dots, a_m \in \Sigma$ with $\delta(p,a_i) = q$ for $1 \leq i \leq m$ in which case we have $L_{p,q} = \{a_1, a_2, \dots, a_m\}$ for each such transition. Then $\mathbf r_{p,q,0} = \mathtt{a_1 + a_2 + \cdots + a_m}$.
- We have $p = q$, in which case, in addition to the above, we also have $\varepsilon \in L_{p,q,0}$, and we add $\varepsilon$ to our regular expression $\mathbf r_{p,q,0}$ as appropriate.
For our inductive step, we consider the language $L_{p,q,k}$ and assume that there exist regular expressions $\mathbf r_{r,s,k-1}$ for languages $L_{r,s,k-1}$ for all states $r,s \in Q$. We claim that we have the following:
$$L_{p,q,k} = L_{p,q,k-1} \cup L_{p,k,k-1} (L_{k,k,k-1})^* L_{k,q,k-1}.$$
This language expresses one of two possibilities for words traveling on paths between $p$ and $q$.
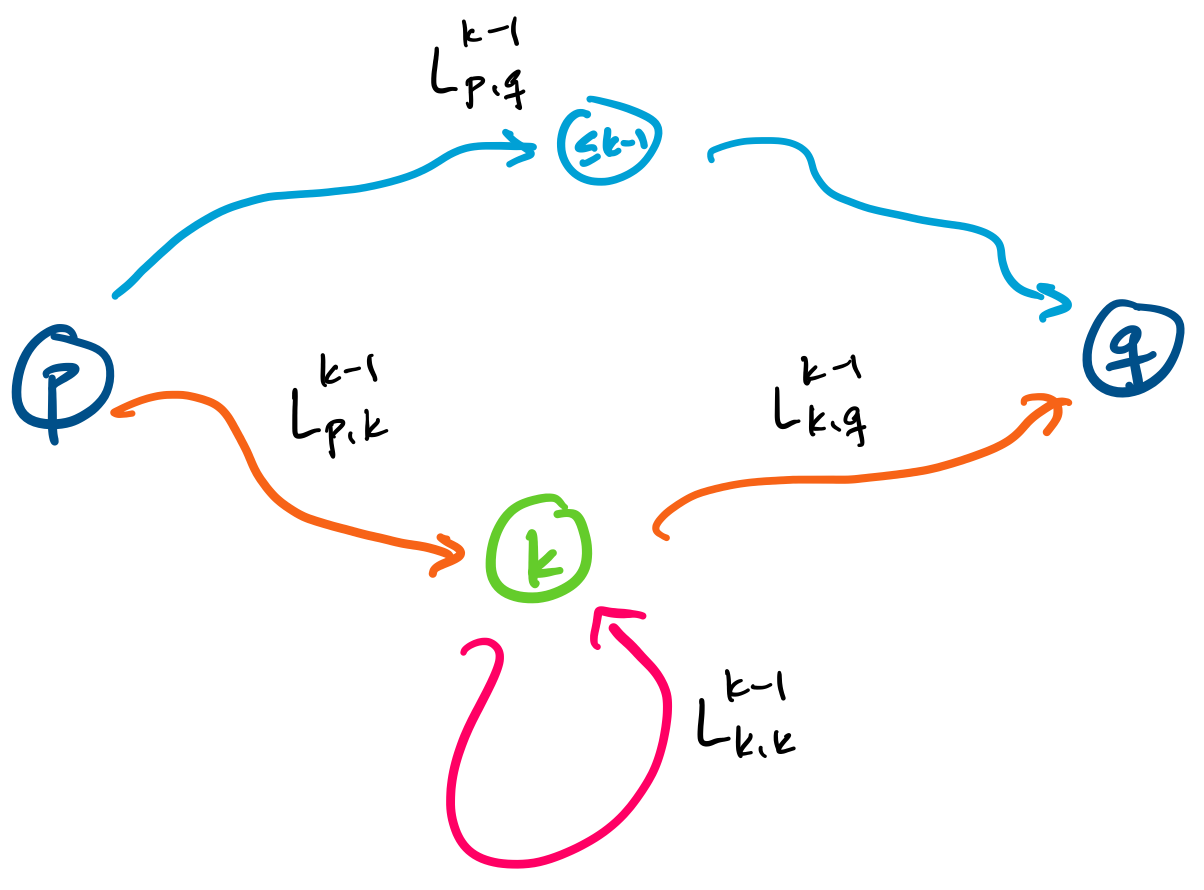
To see this, we first consider when $w \in L_{p,q,k-1}$. In this case, $w$ does not travel through any state $k$ or greater between $p$ and $q$.
The other term of the union consists of words $w$ with $p,q$ paths that contain state $k$. Recall that the language $L_{p,k,k-1}$ is the set of words with paths from $p$ to $k$ restricted to states with label $\leq k-1$ and the language $L_{k,q,k-1}$ is the set of words with paths from $k$ to $q$ restricted to states with label $\leq k-1$. In between these two languages is $L_{k,k,k-1}$, which is the set of words with paths from $k$ back to $k$ without containing any state with label greater than $k-1$.
Since each of the above languages has a regular expression by our inductive hypothesis, we can have the following regular expression:
$$\mathbf r_{p,q,k} = \mathbf r_{p,q,k-1} + \mathbf r_{p,k,k-1} (\mathbf r_{k,k,k-1})^* \mathbf r_{k,q,k-1}.$$
From this, we can conclude that there exists a regular expression
$$ \mathbf r = \sum_{q \in F} \mathbf r_{q_0,q,n}.$$
Here, $\mathbf r$ is the regular expression for the language of all words for which there exist a path from $q_0$ to a final state $q \in F$. In other words, $\mathbf r$ is a regular expression such that $L(\mathbf r) = L(A)$.
This proof, which is due to McNaughton and Yamada in 1960, gives us a dynamic programming algorithm for computing a regular expression from a DFA. Notice that we have the recurrence
\[\mathbf r_{p,q,k} = \begin{cases}
\emptyset & \text{if $k = 0$, $p \neq q$, and $\delta(p,a) \neq q$ for all $a \in \Sigma$}, \\
\varepsilon & \text{if $k = 0$, $p=q$, and $\delta(p,a) \neq q$ for all $a \in \Sigma$}, \\
\mathtt{a_1 + \cdots + a_n} & \text{if $k = 0$, $p \neq q$, and $\delta(p,a_i) = q$ for $1 \leq i \leq n$}, \\
\mathtt{\varepsilon + a_1 + \cdots + a_n} & \text{if $k = 0$, $p = q$, and $\delta(p,a_i) = q$ for $1 \leq i \leq n$}, \\
\mathbf r_{p,q,k-1} + \mathbf r_{p,k,k-1} (\mathbf r_{k,k,k-1})^* \mathbf r_{k,q,k-1} & \text{if $k \gt 0$}, \\
\end{cases}\]
The trick that's used here may seem familiar to you if you've seen the Floyd-Warshall algorithm for computing all-pairs shortest paths, because it operates on the same idea of progressively constructing paths by constraining the allowed intermediary vertices. (Why are we able to use basically the same algorithm? Because both the shortest paths and DFA to regular expression problems are based on objects that form semirings)
This result, together with the result from last class prove Kleene's theorem, which says that the classes of languages recognized by DFAs and regular expressions are the same. This result is due to Kleene in 1951, and was later published in 1956.
What are some consequences of Kleene's theorem? One thing you may have noticed about our regular expressions and the regular expressions you've used (namely POSIX regular expressions) have different sets of operators that you can use. Can we augment our regular expressions with more operators without changing their power? One easy way to do this is to make use of finite automata to prove closure properties for those operations—if you can construct a DFA for it, then you can add it to your regular expressions without any worry!
This sounds great, but it turns out that there are some features defined in POSIX that aren't regularity-preserving. In particular, backtracking can allow regexes to recognize languages which are not regular. In other words, this feature means that standard Unix/Posix regular expressions aren't actually regular! A formal study of the power of such "practical" regular expressions was done by Câmpeanu, Salomaa, and Yu in 2003. But what do languages that aren't regular look like and how do we prove this?
Non-regular languages
There is a theme emerging here: finite automata are characterized by the fact that they can only remember a fixed, finite amount, via its states. And now we've seen that regular expressions, which characterize the regular languages, also exhibit some notion of finiteness through derivatives and these derivatives correspond with states of a DFA.
This suggests that regular languages structurally organize themselves around some property that is finite. We can reason that this property for any language that isn't regular must be infinite. We've run into some of these barriers when trying to construct finite automata and regular expressions, so it's time to investigate more formally what it is that we can't accomplish with regular languages.
Recall that Kleene's theorem let us show that certain operations can be added to the regular expression language without changing the power of regular expressions. In other words, we've shown a number of closure properties—that the regular languages are closed under certain operations. This is why POSIX regular expressions have so many more operators than just union, concatenation, and star.
This sounds great, but it turns out that there are some features defined in POSIX that aren't regularity-preserving. A formal study of the power of such "practical" regular expressions was done by Câmpeanu, Salomaa, and Yu in 2003. In particular, backreferences can allow regexes to recognize languages which are not regular. What are backreferences? Consider the following Posix regular expression.
\([0-9]+\)\1
The [0-9]+ means match any string that consists of 1 or more digits 0 through 9—so any number. Note that this subexpression is surrounded by escaped parentheses. This means it will capture whatever is matched by this subexpression. We can then refer to a matched string by the reference \1.
What does this match? Note that this does not mean that \1 matches anything matched by the subexpression. Rather, \1 will match the exact string that was matched by the subexpression. In other words, $\mathtt{315 346}$ is not matched by this expression, but $\mathtt{315 315}$ is. This means that it is possible to "remember" what was read in an early part of a string and use it later. It is this ability that we claim is not possible to express using regular expressions.
But even with this additional power, these regular expressions still can't do things that we might hope, like parse HTML. And as mentioned in the discussion about lexical analysis and tokenization, regular expressions are insufficient for tasks like enforcing the order of a particular series of tokens.
The Pumping Lemma
We'll describe a condition that captures this idea that all regular languages must have this "finiteness" property, the Pumping Lemma for Regular Languages.
Let $L \subseteq \Sigma^*$ be a regular language. Then there exists a positive integer $n$ such that for every string $w \in L$ with $|w| \geq n$, there exists a factorization $w = xyz$ with $x,y,z \in \Sigma^*$ such that
- $y \neq \varepsilon$,
- $|xy| \leq n$, and
- $xy^iz \in L$ for all $i \in \mathbb N$.
On first contact, the statement of the pumping lemma can be very intimidating with a ton of quantifiers, but the idea behind it is quite simple. Here, $n$ is often referred to as the pumping length of $L$ and it is considered an innate property of the regular language $L$. What the pumping lemma intends to say is that for a long enough string, there are some things that we know about it and other similar strings in $L$ if $L$ is regular.
Specifically, if $L$ is regular, then it is recognized by a DFA and the DFA only has so many states, say $n$. If we read a long enough string, with more than $n$ symbols, then it has to reach at least one of the $n$ states more than once some point. This means that there's a loop in the DFA and we should be able to repeat the part of the word that goes through the loop as much as we like, if it really is recognized by a DFA. So let's walk through this in more detail as we try to prove the lemma.
Since $L$ is regular, there exists a DFA $A = (Q,\Sigma,\delta,q_0,F)$ that recognizes $L$. Let $n = |Q|$ be the number of states of $A$. If there are no strings that are of length at least $n$, then we're done (But what does this say about the language $L$?).
So, we assume that there is a string in $L$ with length at least $n$, say $w = a_1 a_2 \cdots a_\ell$, with $a_i \in \Sigma$ and $1 \leq i \leq \ell = |w| \geq n$. Since $w \in L$, we know that $w$ is accepted by $A$, meaning that there is a sequence of states $p_0, p_1, \dots, p_\ell \in Q$ where $p_0 = q_0$, $p_\ell \in F$, and $\delta(p_i, a_{i+1}) = p_{i+1}$ for $0 \leq i \leq \ell - 1$.
Note that since $\ell \geq n$, we have a sequence of states $p_0, \dots, p_n$ with $n+1$ states. However, by our definition of $A$, the state set $Q$ only contains $n$ distinct elements. Therefore, at least one of the states is repeated in the sequence. In other words, we have $p_s = p_t$ for some $0 \leq s \lt t \leq n$.
Now factor $w$ into three words
- $x = a_1 \cdots a_s$,
- $y = a_{s+1} \cdots a_t$,
- $z = a_{t+1} \cdots a_\ell$.
Here, we see that $y$ is non-empty, as required by condition (1) of the lemma, since $|y| = t-s$ by our requirement that $s \lt t$. Then $xy$ satisfies condition (2) since $|xy| = t$ and we set $t \leq n$.
To see that this factorization of $w$ also satisfies condition (3), we recall the sequence of states $p_0, \dots, p_\ell$. Then it is clear that by reading $x$, $y$, and $z$, we have the following path through states of $A$,
$$q_0 = p_0 \xrightarrow{x} p_s \xrightarrow{y} p_t \xrightarrow{z} p_\ell \in F.$$
But since $p_s = p_t$, it is clear that we have
$$q_0 = p_0 \xrightarrow{x} p_s \xrightarrow{y^i} p_t \xrightarrow{z} p_\ell \in F$$
for all $i \in \mathbb N$.
Thus, we have shown that any string $w \in L$ of length greater than $n$ satisfies conditions (1-3).
It's important to note that what the Pumping lemma says is that all regular languages will satisfy these conditions. What it doesn't say is that if a language satisfies these conditions, it must be regular—in fact, there are languages out there that do satisfy the pumping lemma, but aren't regular.
The pumping lemma is another result that was shown by Rabin and Scott in 1959 (along with the definition of NFAs, the product construction, and the subset construction that we saw earlier). As we'll see, next, this result seems to be a fairly important tool, since it has a name and everything. But it turns out that in the paper, this was a fairly minor characterization, sandwiched in between two other theorems. Hence, why this seemingly important result is only a lemma.
We usually refer to this as just "the pumping lemma" but this result is really the pumping lemma for regular languages. There are a bunch of similar results that work in the same way for many other language classes and this is now a standard tool in the theory of formal languages. We'll be seeing another one later on.