Regular operations and finite automata
A surprising fact about regular languages and languages recognized by DFAs is that they happen to be exactly the same—the class of DFA languages is the class of regular languages. At first glance, there's no obvious reason why this should be the case. After all, finite automata and regular expressions are totally different formalisms that have no obvious connection. But as we delve further into the class of regular languages, we'll see a surprising number of connections.
First, we will describe a way to construct a finite automaton, given a regular language/expression.
Let $L \subseteq \Sigma^*$ be a regular language. Then there exists a DFA $M$ with $L(M) = L$.
We will show this by structural induction. Since we've already shown that they're equivalent to DFAs, we will actually just construct $\varepsilon$-NFAs for convenience.
First, for our base case, we can construct the following $\varepsilon$-NFAs for each of conditions (1–3):

Since these are pretty simple, we won't formally prove that they're correct, but you can try on your own if you wish.
Now, we will show that we can construct an $\varepsilon$-NFA for each of conditions (4–6). For our inductive hypothesis, we let $L_A$ and $L_B$ be regular languages and assume that they can be accepted by DFAs $A$ and $B$, respectively.
Luckily, we've done a lot of the work up to this point.
First, we'll consider $L_A \cup L_B$. We've already seen how to construct a DFA for the union of the two languages by modifying the product construction. Here, we'll take the opportunity to describe an $\varepsilon$-NFA that does the same thing. Informally, we can make an NFA that looks like this:
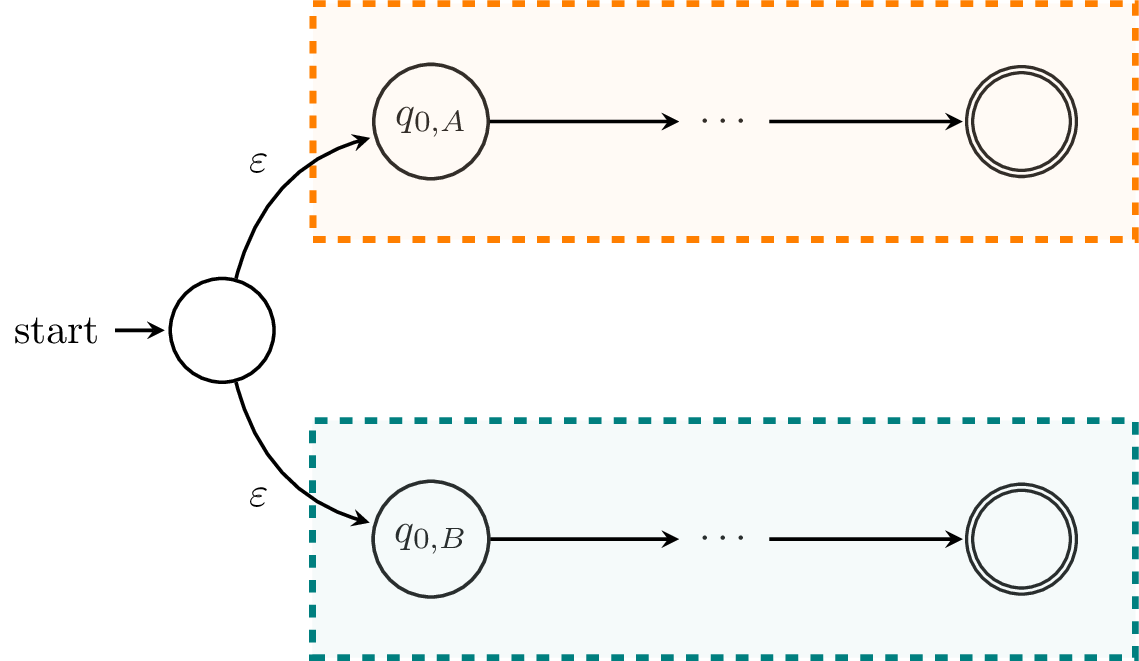
Basically, we take our idea about running two finite automata in parallel literally. We start in the initial states of each machine and run them. If one of them accepts, then we accept.
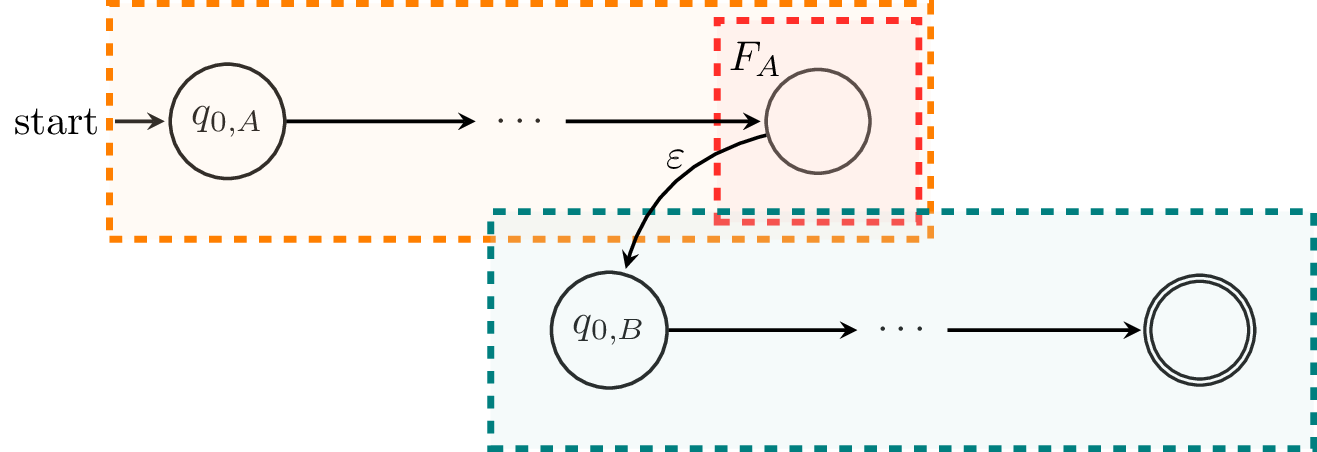
Next, we'll consider $L_A L_B$. We can modify the NFA from Theorem 5.4 so that it uses $\varepsilon$-transitions instead.
Finally, we consider $L_A^*$. For this, we'll break out and prove it as it's own theorem. Once we have proved it, we will have shown that we can construct $\varepsilon$-NFAs for $L_A \cup L_B$, $L_A L_B$, and $L_A^*$ and therefore, we can construct a DFA that accepts any given regular language.
The class of DFA languages is closed under Kleene star.
Let $A = (Q_A,\Sigma,\delta,q_{0,A},F_A)$ be a DFA. We can construct an $\varepsilon$-NFA that looks like this:
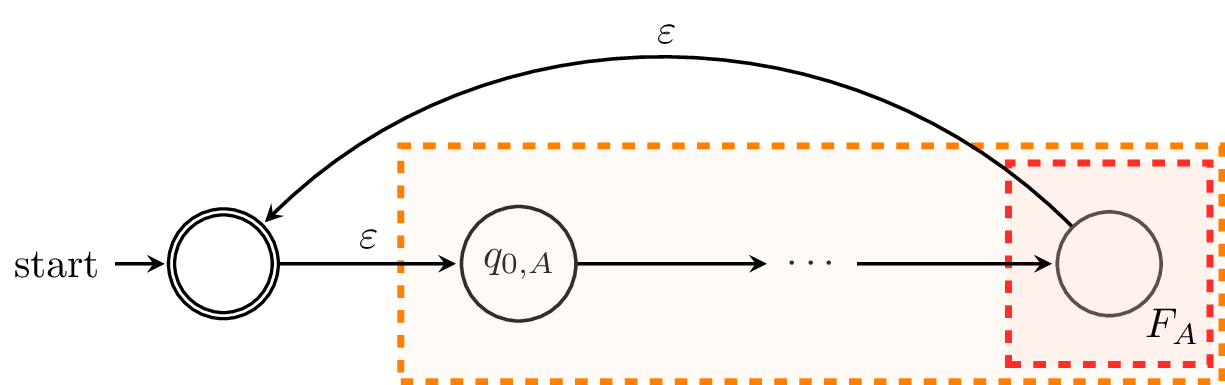
We define $A'$ by $A' = (Q_A \cup \{q_0',\}, \Sigma, \delta', \{q_0'\}, \{q_0'\})$, where the transition function $\delta' : Q_A \times (\Sigma \cup \{\varepsilon\}) \to 2^{Q_A \cup \{q_0'\}}$ is defined by
- $\delta'(q,a) = \{\delta(q,a)\}$ for all $q \in Q_A$ and $a \in \Sigma$,
- $\delta'(q,\varepsilon) = \{q_0'\}$ for all $q \in F_A$,
- $\delta'(q_0',\varepsilon) = \{q_{0,A}\}$.
We modify $A$ to get $A'$ as follows. First, we need to create a new initial state and make it an initial state, in case $\varepsilon \not \in L_A$. Secondly, for each state in $F_A$, instead of adding it to the set of final states in $A'$, we add $\varepsilon$-transitions to the sole final state of $A'$, $q_0'$. While this is mostly cosmetic, it makes the construction clearer. Each word that is accepted by $A'$ must begin at $q_0'$ and must end at $q_0'$, making zero or more traversals through $A$, and each traversal of $A$ must be a word accepted by $A$. Hence, each word accepted by $A'$ is a concatenation of multiple words accepted by $A$ and thus, a word that belongs to $L_A^*$.
This specific construction is due to Ken Thompson in 1968 and is most commonly called the Thompson construction. Thompson, was one of the early figures working on Unix and was, among other things, responsible for the inclusion of regular expressions in a lot of early Unix software like ed, making regexes ubiquitous among programmers. More recent work of his you may be familiar with include UTF-8 and the Go programming language.
Let's see an example and apply the Thompson construction.
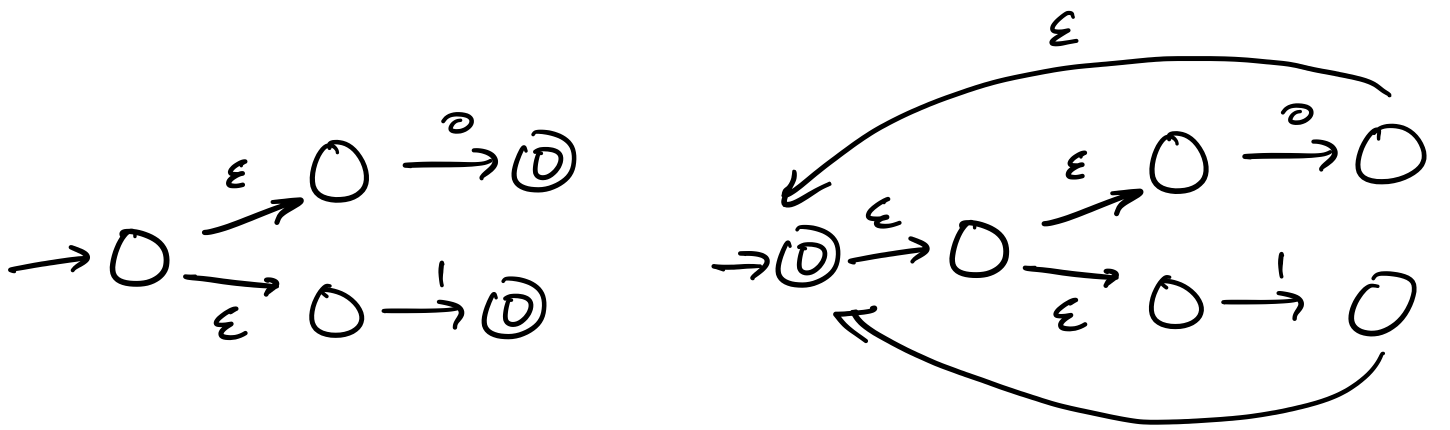
Consider regular expression $\mathbf r = \mathtt{(0+1)^* 000 (0+1)^*}$, which matches all binary strings that contain $000$ as a substring. To construct an NFA based on the Thompson construction, we begin with our basic NFAs for $0$ and $1$.
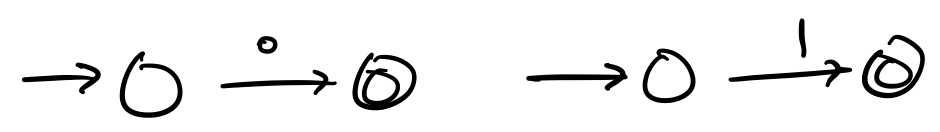
Then, we use these in the other constructions. For instance, we can construct the union, followed by the star.
Then we can perform our concatenations.
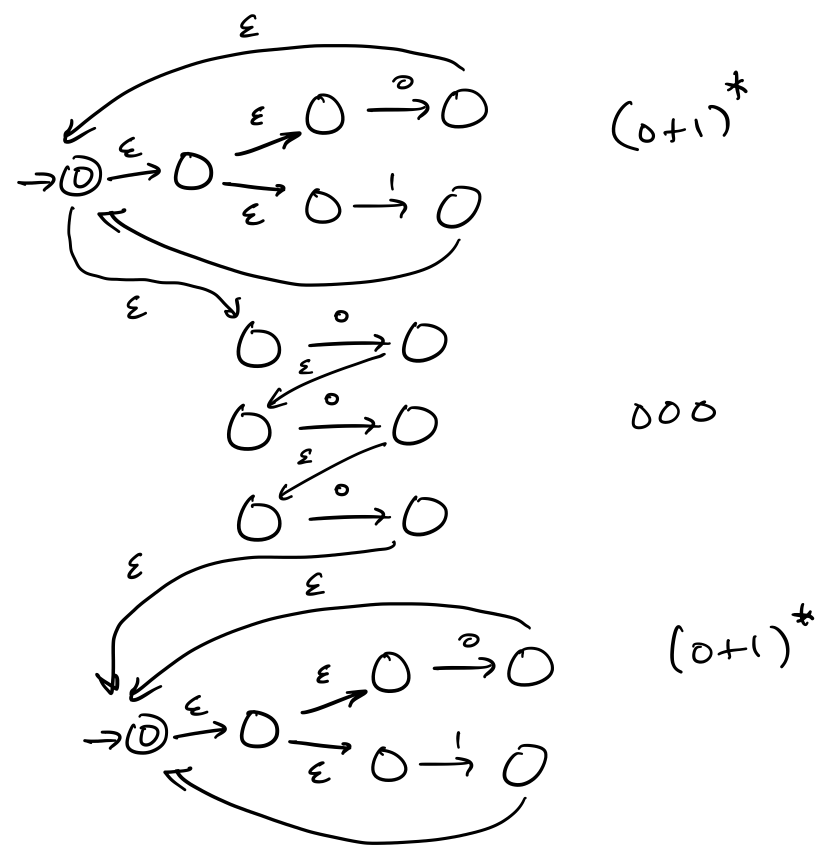
Observe that this machine is quite large and you can already see some states and transitions that are superfluous. Or, put another way, you probably could've come up with a smaller machine right at the start just by thinking about it for maybe half a minute.
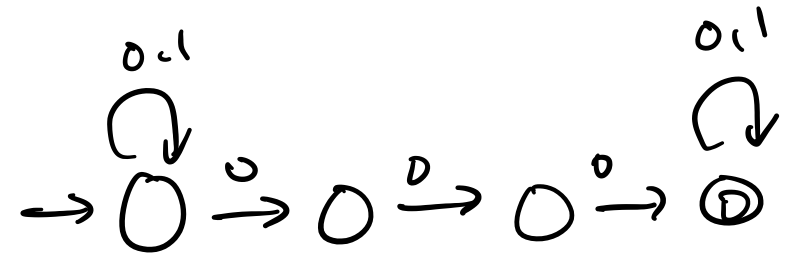
Despite this, we can observe that for a regular expression of length $n$, the Thompson construction gives us an NFA that has $O(n)$ states. To see this, we notice that each case of the construction only adds one or two states. Since each case corresponds to an atomic expression or an operation, we can see that each character in the expression is responsible for one or two states (we can also try to prove this formally).
The main downside of the Thompson construction is the use of $\varepsilon$-transitions. There are a number of algorithms that transform regular expressions without $\varepsilon$-transitions and still result in roughly $O(n)$ states.
- One such method is the position automaton, developed independently by Glushkov in 1961 and McNaughton and Yamada in 1960. This construction is based on the position of the letters in the regular expression.
- In 1996, Antimirov defined the partial derivative automaton, based on derivatives of regular expressions. Derivatives of regular expressions are regular expressions that are computed algebraically based on a given quotient. We'll be seeing these soon.
- The follow automaton is refinement of the position automaton, introduced by Ilie and Yu in 2003.