Now, we'll consider another possible enhancement to the finite automaton: allowing transitions to other states via $\varepsilon$. This additional trick will be very convenient, but again, we have to ask the question: does this make finite automata more powerful? Some of you have already caught on when I introduced the NFA with multiple initial states and wondered if multiple initial states really makes a difference over a single initial state. That same intuition will serve us when we think about how $\varepsilon$-transitions actually work.
First, the formal definition.
An $\varepsilon$-NFA is a 5-tuple $A = (Q,\Sigma,\delta,I,F)$ as in the definition of the NFA, except that the transition function is now a function from a state and either a symbol or $\varepsilon$ to a set of states, $\delta : Q \times (\Sigma \cup \{\varepsilon\}) \to 2^Q$.
So the question now is, what is the result of a transition function that allows $\varepsilon$s? Let's consider the following example.
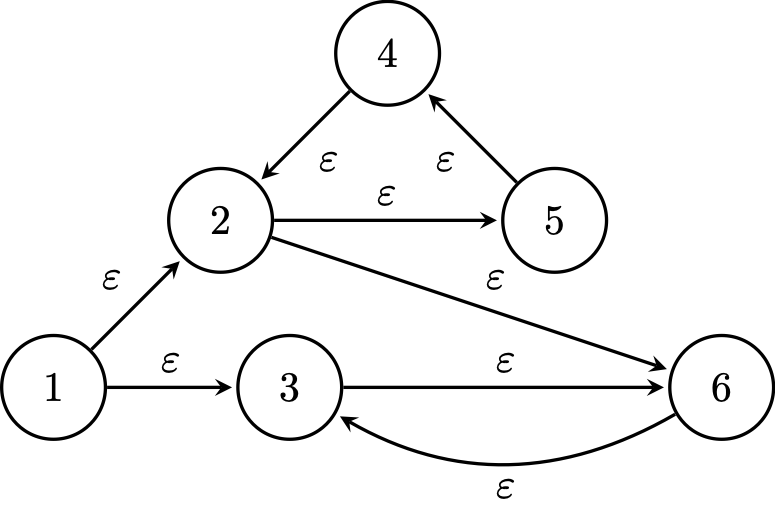
Consider the state diagram below. We can ask for each state, which other states we should be in if we "read $\varepsilon$"? In other words, if we don't read anything, where would we be?
What we would like is a way to say, for some set of states $P \subseteq Q$, "all the states that are reachable on one or more $\varepsilon$-transitions from a state $p \in P$". We'll define the $\varepsilon$-closure of $P$ to be exactly this.
The $\varepsilon$-closure of a state $q \in Q$ is denoted by $\mathcal E^*(q)$ and is defined inductively by
Then the $\varepsilon$-closure of a set $P \subseteq Q$, denoted $\mathcal E^*(P)$ is defined by $$\mathcal E^*(P) = \bigcup_{p \in P} \mathcal E^*(p).$$
This notion is mostly for the purposes of formal definitions: it allows us to say formally which states we are "in" without having read anything. We can then use this notion to define our extended transition function that allows for $\varepsilon$.
Let $\delta^* : Q \times \Sigma^* \to 2^Q$ be a function defined as follows,
In other words, our new extended transition function for the $\varepsilon$-NFA is just the one for the ordinary NFA, except that we need to ensure that we account for the $\varepsilon$-closure of the result.
You might observe that, as we still only need to consider at most $2^{|Q|}$ possible sets, that allowing $\varepsilon$-transitions do not give NFAs any additional power, and you would be absolutely correct. At this point, you can play the same game as with the NFA and perform the subset construction to acquire an equivalent DFA, as long as you make sure to account for the $\varepsilon$-closure.
If we have an $\varepsilon$-NFA $N = (Q,\Sigma,\delta,I,F)$, we can define a DFA $\mathcal D_\varepsilon(N) = (Q',\Sigma,\delta',q_0',F')$ in the same way as the subset construction above, but with two differences:
In other words, the subset construction for $\varepsilon$-NFAs is exactly the same as for NFAs, except that all the states of $\mathcal D_\varepsilon(N)$ are $\varepsilon$-closed subsets of $Q$. We can then use this to show the following.
A language $L$ is accepted by an $\varepsilon$-NFA if and only if $L$ is accepted by a DFA.
The proof is almost exactly the same as for ordinary NFAs so we won't be going through it here. This result establishes that DFAs, NFAs, and $\varepsilon$-NFAs are all equivalent models and that they all recognize the same class of languages. In other words, nondeterminism and $\varepsilon$-transitions do not give our basic finite automaton model any additional power.
For the most part, the distinction between an NFA and an $\varepsilon$-NFA is not that big, so it is usually not specified. You can assume that you can use $\varepsilon$-transitions in an NFA unless otherwise specified (but not DFAs).
So far, we have been focused on languages as problems to be solved by some model of computation. In particular, we've been giving our attention to finite automata, whether they're deterministic or not (and as we saw, the distinction doesn't matter when thinking about power). But what makes a language simple enough that it can be recognized by a DFA? This isn't something that we can answer by looking only at the model of computation, so we'll step back and investigate other properties of these languages.
Are there other ways to describe and represent languages? Recall that languages are sets and that we can perform all the usual set operations on these sets to describe or construct new languages. We also extended some string operations to languages. We will now define a specific set of these operations to be regular operations.
Let $\Sigma$ be an alphabet and let $L,M \subseteq \Sigma^*$ be languages. The following operations are the regular operations:
So what's so special about these particular operations? In some sense, we can think of these as the minimal set of operations needed to describe "interesting" things.
These operations define what we call the class of regular languages.
A language $L$ is regular if it satisfies the following:
Let $L_1$ and $L_2$ be regular languages.
This is an interesting definition because this tells us how to construct languages. This is in contrast to when we were talking about DFAs and NFAs—we were primarily focused on how to recognize languages.
What exactly do these definitions tell us? The base cases tell us what we start with: atomic pieces like the empty string and single letters. The inductive cases tell us how we can put these pieces together.
But why are these called regular languages? It's mostly because Kleene called them this when he first defined them in 1956 and no one bothered to come up with a better name since.

That's not actually entirely true, because there is a better name that shows up from the algebraic/French literature. Recall that we can view our alphabet together with concatenation as a monoid and the free monoid on our alphabet is just the set of strings over that alphabet. If we forget about focusing on free monoids and just consider arbitrary monoids, then the rational subsets of a monoid are those subsets that are closed under the rational operations: $\cup$, $\cdot$, and $*$ (here, $\cdot$ and $*$ refer to the binary operation for the monoid, not necessarily concatenation).
From this, it makes a lot of sense to call regular languages rational languages instead, and there are many who do, particularly algebraic automata theorists and French mathematicians. But the prevailing terminology, especially among computer scientists, is going to be regular languages.
However, the algebraic perspective gives us the following mechanism to describe languages.
Up to now, we've only considered finite automata as a way to describe a language. However, using finite automata as a description has its limitations, particularly for humans. While all of the finite automata we've seen so far are reasonably understandable, they are relatively small. Finite automata as used in practical applications can contain hundreds or thousands or more states. Luckily, our definition of regular languages will give us a more succinct and friendlier way to describe a regular language, via regular expressions.
The regular expression $\mathbf r$ over an alphabet $\Sigma$ with language $L(\mathbf r)$, is defined inductively by
and for regular expressions $\mathbf r_1$ and $\mathbf r_2$,
Furthermore, we establish an order of operations, like for typical arithmetic expressions:
and as usual, we can explicitly define an order for a particular expression by using parentheses.
Regular expressions are a way for us to use the idea of regular operations to describe languages algebraically, both informally and formally. By informal, I simply mean that regular expressions "look like math" and that they work kind of how you might expect algebra to work intuitively.
This is not a coincidence, because regular expressions really are algebraic in the formal sense. The regular expressions form what is called a semiring. A semiring is a set equipped with two operations, which we refer to as "addition" and "multiplication" with the condition that both addition and multiplication have identity elements. The regular expressions are a semiring because we take union to be addition with identity $\emptyset$ (i.e. $\mathbf r + \emptyset = \mathbf r$) and concatenation as multiplication with identity $\varepsilon$ (i.e. $\mathbf r \cdot \varepsilon = \mathbf r$).
(If these are semirings, then what makes a ring? It is the requirement that every element has an additive inverse, i.e. for all $n$, there exists an element $-n$ such that $n + (-n) = 0$. An example of a ring that we are all familiar with is the integers.)
I want to highlight another bit of notation here. I use $\mathbf{boldface}$ to denote regular expressions and $\mathtt{monospace}$ to denote the symbols used in the regular expression. This is because there's often confusion about the difference between the regular expression itself and the language of the regular expression. A regular expression $\mathbf r$ over an alphabet $\Sigma$ should be considered a string over the alphabet $\{\mathtt a \mid a \in \Sigma\} \cup \{\mathtt (,\mathtt ),\mathtt \emptyset,\mathtt *,\mathtt +,\mathtt \varepsilon\}$, while the language of $\mathbf r$, $L(\mathbf r)$ is a set of words over $\Sigma$.
Jacqus Sakarovitch, in Elements of Automata Theory, refers to this distinction as a bit of "tetrapyloctomy" but proceeds to point out that what we're dealing with is really the distinction between a syntactic object (the expression) and the semantic object (the language). As computer scientists, we are constantly having to navigate this distinction—we've already seen this before when trying to prove that a DFA works correctly.
Consider the regular expression $\mathbf r = \mathtt{(a+b)^* b (a+b)(a+b)}$. The language of $\mathbf r$ is $L(\mathbf r)$, the language of strings over the alphabet $\{a,b\}$ with $b$ in the third from last position. So, $abbb \in L(\mathbf r)$. If we want to describe $L(\mathbf r)$ using the regular operations, we would have something like: \[L(\mathbf r) = (\{a\} \cup \{b\})^* \{b\} (\{a\} \cup \{b\}) (\{a\} \cup \{b\}).\]
We can see that this definition mirrors that of the definition for regular languages and we can pretty easily conclude that the regular expressions describe exactly the class of regular languages. Again, we should note that we need to separate the notion of a regular expression and the language of the regular expression—a regular expression $\mathbf r$ is just a string, while $L(\mathbf r)$ is the set of words described by the regular expression $\mathbf r$.
Why does this matter? As with finite automata, one language can have multiple representations or descriptions. And since regular expressions form a semiring, this means that many of the algebraic identities we might be used to from arithmetic also apply to them.
Two regular expressions $\mathbf r$ and $\mathbf s$ over $\Sigma$ are equivalent if they describe the same language. That is, $\mathbf r \equiv \mathbf s$ if $L(\mathbf r) = L(\mathbf s)$.
This is the same kind of idea that you may have seen with logical equivalence—two logical formulas are said to be equivalent because they mean the same thing but we don't say they're equal because they are not literally the same.
Here are some basic identities for regular expressions. We let $\mathbf r, \mathbf s, \mathbf t$ be regular expressions over $\Sigma$.
The only "new" identity here that you wouldn't guess from arithmetic is cyclicity, which involves the Kleene star. All other identities follow from regular expressions forming a semiring.
Here are a few more examples of some regular expressions and the languages they describe.
The term regular expression may sounds familiar to many of you, particularly if you've ever needed to do a bunch of pattern matching. And your guess is correct: these are (mostly) the same thing. For the most part, the regular expressions as used in Unix and various programming languages are based on our theoretically defined regular expressions. This leads to a few points of interest.
The first is that this implies a non-theoretical application for all of the stuff that we've been doing so far: pattern matching. If you want to search for some text, or more generally a pattern, then regular expressions are your tool of choice. But, and I hinted at this earlier, regular expressions are for us to read, while the computer turns it into a finite automaton and uses that for text processing.
Now, that may have been obvious because the name gave it away. However, there's a second classical application of regular languages that is similar: lexical analysis. Lexical analysis is the phase of the compiler that is responsible for breaking up strings of symbols into a sequence of tokens (which is why this is also sometimes called tokenization).
Tokens are discrete units that have some meaning. For instance, the string
if ( x > 2 ) {could be tokenized as
[(KEYWORD, "if"), (SEPARATOR, "("), (IDENTIFIER, "x"), (OPERATOR, ">"), (LITERAL, "2"), (SEPARATOR, ")"), (SEPARATOR, "{")]Now, what's important to keep in mind is that tokenization only gives meaning to the parts of the string, but it doesn't check whether the sequence of tokens actually makes "grammatical" sense. This is a sign of things to come.
Of course, there's an obvious analogy to natural language. In computational linguistics, regular languages provide a simple first approach to tokenizing natural language sentences, by identifying discrete words and possibly the kinds of words (nouns, verbs, etc.) they are. Again, such processing only attempts to provide meanings to chunks of strings, but doesn't enforce any particular rules about how these chunks should be arranged.