One way to think about nondeterminism is to think of every nondeterministic transition as a possible choice. For instance, if we're in $q_0$ and we see a $b$, our choice is between staying in $q_0$ or going to $q_1$. We would not have such a choice in a determinstic machine. But how do we think about the ability to choose which path to take? To do this, we need to formally define acceptance for nondeterministic machines.
Again, we will extend our transition function, but this time we will do so in two ways. First, we'll do the same thing we did for DFAs, which is to extend $\delta$ to a function $\delta^*$ on states and strings.
The function $\delta^*: Q \times \Sigma^* \to 2^Q$ is defined by
- $\delta^*(q,\varepsilon) = \{q\}$, and
- for $w = xa$ with $x \in \Sigma^*$ and $a \in \Sigma$, we have
$$ \delta^*(q,xa) = \bigcup_{p \in \delta^*(q,x)} \delta(p,a).$$
Notice how this definition takes into account that the output of $\delta$ is a set of states. As usual, we drop the star when the context is clear that we're working with strings.
The other extension we'll make is more of a convenience (or an abuse of notation) by treating $\delta$ as a function on subsets of states $\delta: 2^Q \times \Sigma^* \to 2^Q$. To do this, we take for $P \subseteq Q$,
$$\delta(P,a) = \bigcup_{q \in P} \delta(q,a)$$
when the context is clear.
Let's take a moment to see how this definition fits with our intution about how nondeterminism behaves. It is easy to see that by taking the union of these sets, we really do get all possible transitions. However, note that this definition also handles transitions that are missing: if $\delta(p,a) = \emptyset$, then for any set $S$, we have $S \cup \emptyset = S$, and so $\delta^*$ remains well-defined.
Now, we can define acceptance under the nondeterministic model.
We say that an NFA $A$ accepts a word $w$ if $\delta^*(i,w) \cap F \neq \emptyset$ for some initial state $i \in I$. Then the language of an NFA $A = (Q,\Sigma,\delta,I,F)$ is defined by
$$ L(A) = \left\{w \in \Sigma^* \mid \delta^*(I,w) \cap F \neq \emptyset \right\}.$$
What does this definition say? For DFAs, acceptance is defined as the machine being in a final state at the moment we finish reading our input string. For NFAs, we will be in multiple possible states when we finish reading our string. This definition of acceptance says that as long as there is a final state among these states, the NFA accepts the string.
If we think of nondeterminic transitions as a choice, then a nondeterministic machine explores all possible choices we could have made. The resulting set of states that we end up with is the outcome of some sequence of choices that were made throughout the computation of the machine. One way to interpret what the acceptance condition is saying is that as long as there is at least one sequence of choices that we can make so that we're in a final state, then our string is accepted. Rather than a single path through our machine, we can think of a computation on a nondeterministic machine as a tree.
Another way to interpret nondeterministic choices is rather than making a choice, we're really making a guess: we don't know which of the choices we make are the right ones. But as long as there is some choice that works, then we can guess at each step and come up with a valid accepting computation.
The ability to guess is exactly what we need in order to solve the concatenation problem: with a deterministic machine, our problem was we didn't know when to make the jump from the first part of the string to the second part of the string. Without the ability to double back and re-read the front of the string, we need to be able to guess when the "break" happens.
Let $L_1$ and $L_2$ be DFA languages. Then there exists an NFA that accepts $L_1L_2$.
Let $L_1$ and $L_2$ be languages that are recognized by DFAs $A_1 = (Q_1, \Sigma, \delta_1, q_{0,1}, F_1)$ and $A_2 = (Q_2, \Sigma, \delta_2, q_{0,2}, F_2)$, respectively. We will construct an NFA $A' = (Q',\Sigma, \delta', I', F')$ to recognize $L_1 L_2$. Here, we have
- $Q' = Q_1 \cup Q_2$,
- $I' = \{q_{0,1}\}$,
- $F' = F_2$,
and the transition function $\delta':(Q_1 \cup Q_2) \times (\Sigma \cup \{\varepsilon\}) \rightarrow 2^{Q_1 \cup Q_2}$ is defined
- for $q \in Q_1$ and $a \in \Sigma$,
\[\delta'(q,a) = \begin{cases}
\{\delta_1(q,a)\} & \text{if $\delta_1(q,a) \not \in F$,} \\
\{\delta_1(q,a), q_{0,2}\} & \text{if $\delta_1(q,a) \in F$,}
\end{cases}\]
and
- $\delta'(q,a) = \{\delta_2(q,a)\}$ for $q \in Q_2$ and $a \in \Sigma$.
What does this NFA do? We begin by reading our string on $A_1$. Then, whenever the machine enters a final state of $A_1$, it simultaneously enters the initial state of $A_2$. In this way, we nondeterministically "guess" that we start the second part of the string. Then this construction hinges on the observation that we can only make it into the automaton $A_2$ if we enter a final state of $A_1$.
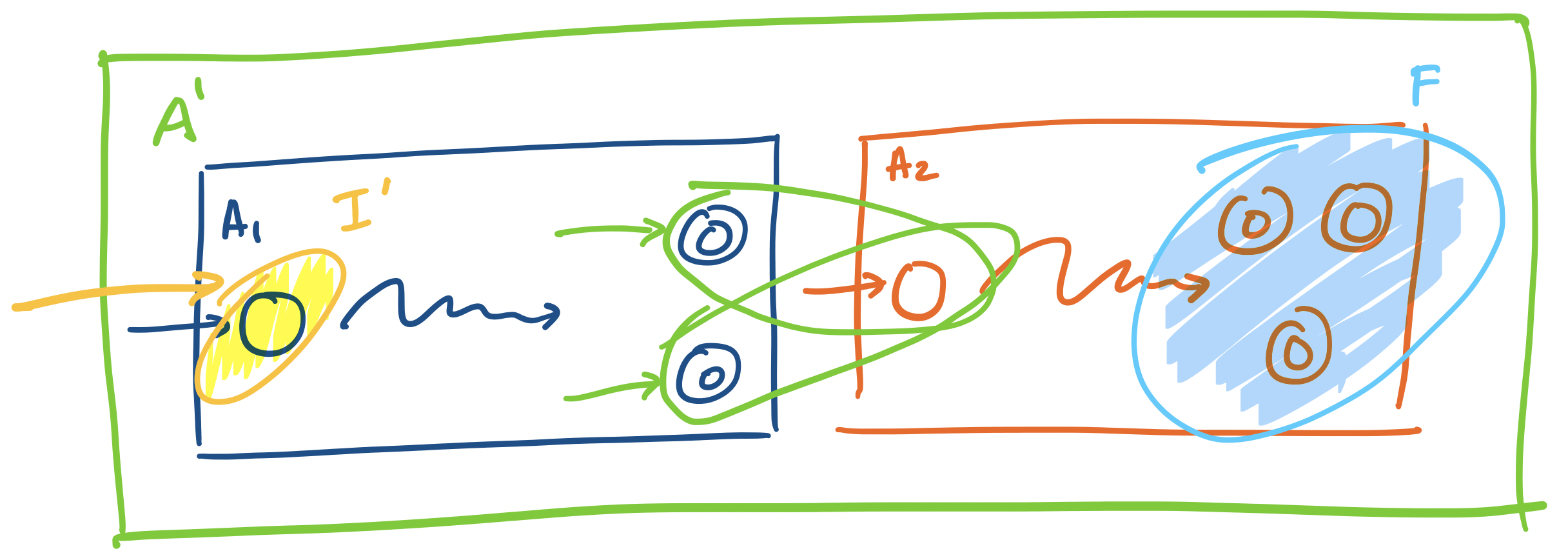
Consider a word $w \in \Sigma^*$ that's accepted by $A'$—that is $w \in L(A')$. Then $\delta'(\{q_{0,a}\}, w) \cap F_2 \neq \emptyset$. So we can split the word up into two words $w = xy$. Since the only entry point into $A_2$ is $q_{0,2}$, we have that $\delta_2(q_{0,2},y) \in F_2$. But in order for $q_{0,2}$ to be reached, there had to be some word $x$ such that $\delta_1(q_{0,1},x) \in F_1$. Our computation path looks like
\begin{align*}
q_{0,1} \xrightarrow{x} p \in & F_1, \\& \Downarrow \\ & q_{0,2} \xrightarrow{y} q \in F_2
\end{align*}
This gives us our two words $x \in L(A_1)$ and $y \in L(A_2)$ and therefore $w = xy \in L_1L_2$.
Now, suppose that $w \in L_1L_2$. This means that $w = uv$ where $u \in L_1$ and $v \in L_2$, and since these languages are both accepted by their respective DFAs, we have $u \in L(A_1)$ and $v \in L(A_2)$. So $\delta_1(q_{0,1}, w) = q \in F_1$ and $\delta_2(q_{0,2}, v) = q' \in F_2$. Then in $A'$, we have $\{q, q_{0,2}\} \subseteq \delta'(\{q_{0,1}\}, u)$. We then have $\delta'(\{q,q_{0,2}\}, v) \subseteq \delta'(\{q_{0,1}\}, uv)$ and therefore $\delta'(\{q_{0,1}\}, uv) \cap F_2 \neq \emptyset$.
\begin{align*}
q_{0,1} \xrightarrow{u} q \in & F_1, \\ &\Downarrow \\ & q_{0,2} \xrightarrow{v} q' \in F_2
\end{align*}
So $w = uv \in L(A')$.
The subset construction
So now, the obvious question to ask is: does nondeterminism really give us more power? That is, can NFAs recognize languages that DFAs can't? The example that we just constructed seems like something that would be really difficult to pull off with an NFA. And yet, it turns out the answer is no—DFAs are just as powerful as NFAs.
But how? We'll show that given any NFA $N$, we can construct a DFA $M$ that accepts the same language. The key observation is in examining what exactly is happening with our nondeterministic transition function. Remember that for each state and symbol, the transition function gives a set of states rather than a single state as a deterministic finite automaton.
So how many sets are there? If there are $n$ states, then there are $2^n$ possible subsets of $Q$. This is a large number which we've been trained as computer scientists to be alarmed at, but the important thing is that it is finite. This gives us a way to "simulate" the nondeterminism of an NFA using a DFA: just make each subset of $Q$ its own state!
This construction is called the subset construction and was again due to Rabin and Scott in 1959. An interesting question that one can consider is when the worst case of $2^n$ states comes up. Similar questions about the worst-case growth in the number of states of a DFA or NFA can be asked for other transformations or language operations in a line of research in automata theory called state complexity.
Let's define the subset construction formally.
Let $N = (Q,\Sigma,\delta,I,F)$ be an NFA. We will construct a DFA $\mathcal D(N) = (Q',\Sigma,\delta',q_0',F')$ such that $L(\mathcal D(N)) = L(N)$. We will define each component of $\mathcal D(N)$:
- $Q' = 2^Q$. That is, $Q'$ is the set of subsets of $Q$. This means that a state of $\mathcal D(N)$ is a subset of $Q$,
- $\Sigma$ is the same alphabet as in $N$,
- $q_0' = I$. That is, the initial state of $\mathcal D(N)$ is the set of initial states $I$,
- $F' = \{S \subseteq Q \mid S \cap F \neq \emptyset\}$. Remember that the acceptance condition of $N$ is that there is at least one path in $N$ that ends in an accepting state. Thus, the set of final states of $\mathcal D(N)$ is any subset of $Q$ that contains a final state of $N$.
- Finally, we have the transition function $\delta'$, which we define in terms of a set $S \subseteq Q$ and an input symbol $a \in \Sigma$:
$$\delta'(S,a) = \bigcup_{p \in S} \delta(p,a).$$
In other words, $\delta'(S,a)$ is all states reachable in $N$ from $S$ on the symbol $a$.
Let's try this with this example. Here's the NFA again.
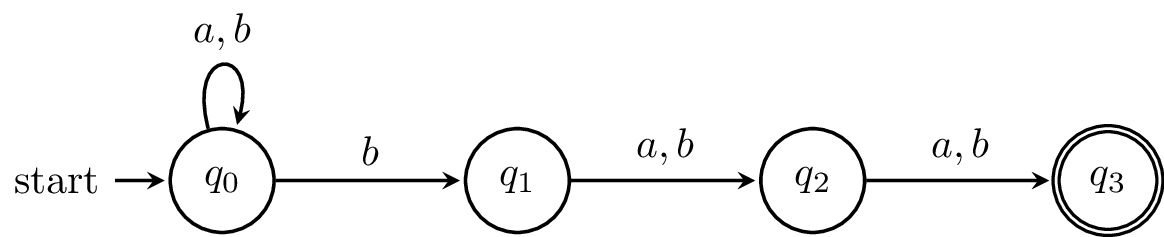
And here is the transition table with all the subsets.
| | $a$ | $b$
|
| $\emptyset$ | $\emptyset$ | $\emptyset$
|
| $\{q_0\}$ | $\{q_0\}$ | $\{q_0,q_1\}$
|
| $\{q_1\}$ | $\{q_2\}$ | $\{q_2\}$
|
| $\{q_2\}$ | $\{q_3\}$ | $\{q_3\}$
|
| $\{q_3\}$ | $\emptyset$ | $\emptyset$
|
| $\{q_0,q_1\}$ | $\{q_0,q_2\}$ | $\{q_0,q_1,q_2\}$
|
| $\{q_0,q_2\}$ | $\{q_0,q_3\}$ | $\{q_0,q_1,q_3\}$
|
| $\{q_0,q_3\}$ | $\{q_0\}$ | $\{q_0,q_1\}$
|
| $\{q_1,q_2\}$ | $\{q_2,q_3\}$ | $\{q_2,q_3\}$
|
| $\{q_1,q_3\}$ | $\{q_2\}$ | $\{q_2\}$
|
| $\{q_2,q_3\}$ | $\{q_3\}$ | $\{q_3\}$
|
| $\{q_0,q_1,q_2\}$ | $\{q_0,q_2,q_3\}$ | $\{q_0,q_1,q_2,q_3\}$
|
| $\{q_0,q_1,q_3\}$ | $\{q_0,q_2\}$ | $\{q_0,q_1,q_2\}$
|
| $\{q_0,q_2,q_3\}$ | $\{q_0,q_3\}$ | $\{q_0,q_1,q_3\}$
|
| $\{q_1,q_2,q_3\}$ | $\{q_2,q_3\}$ | $\{q_2,q_3\}$
|
| $\{q_0,q_1,q_2,q_3\}$ | $\{q_0,q_2,q_3\}$ | $\{q_0,q_1,q_2,q_3\}$
|
Note that all the subsets in red cannot be reached from the initial state $\{q_0\}$. Now, here is the state diagram for the DFA.
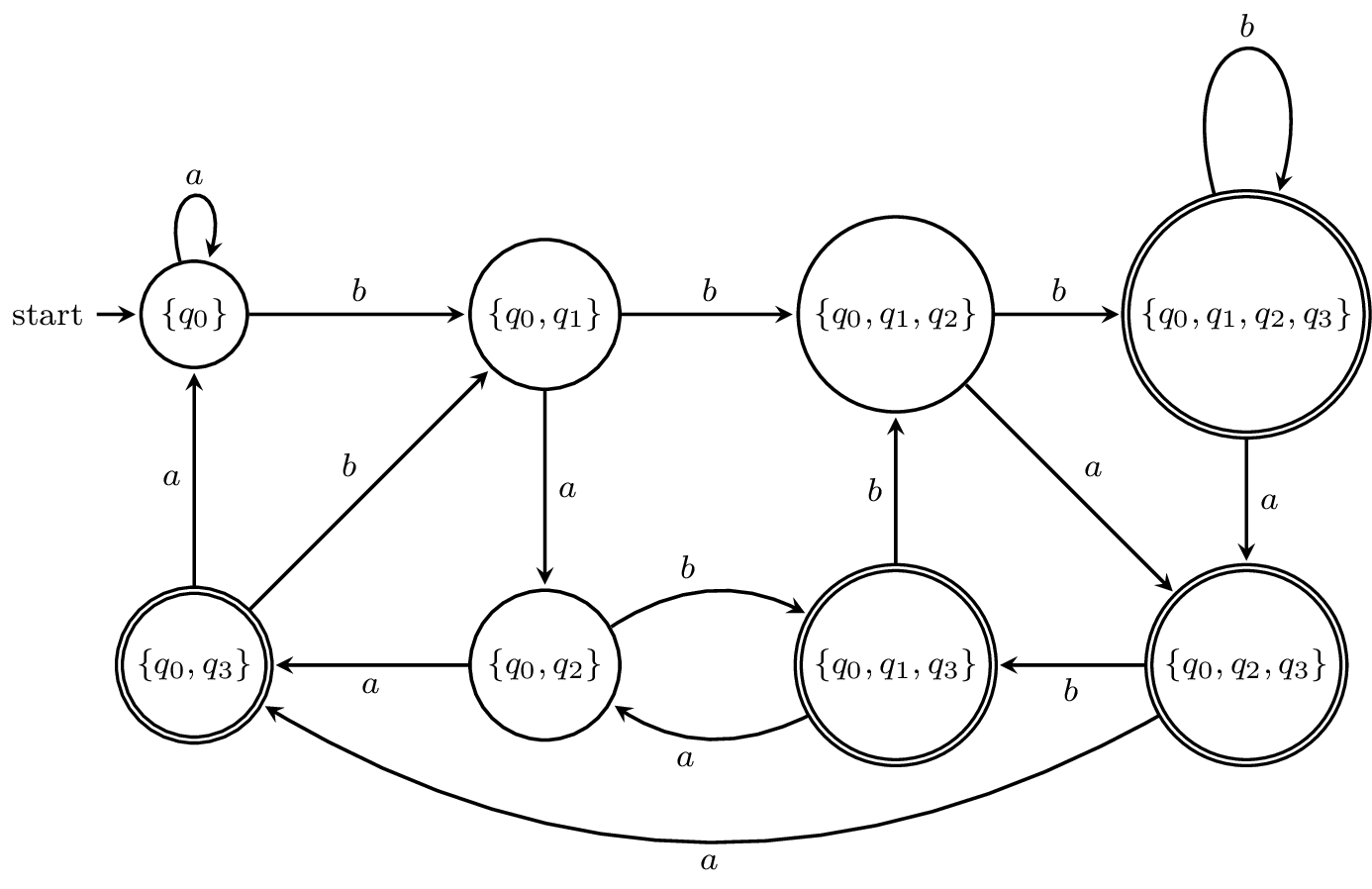
I've omitted all the subsets that can't be reached, but this is still a large DFA relative to the size of the NFA. In fact, one can show that the language $\{a,b\}^* b \{a,b\}^{n-1}$ can be recognized by an NFA with $n+1$ states but requires a DFA with $2^n$ states. (This is why it was interesting to see that an exercise from the first edition of Hopcroft and Ullman's book asked for a DFA that accepted this language for $n = 10$)
Now, we want to show that $\mathcal D(N)$ and $N$ recognize exactly the same language.
Let $N$ be an NFA. Then $L(N) = L(\mathcal D(N))$.
We want to show that $w \in L(N)$ if and only if $w \in L(\mathcal D(N))$. This means that by definition, $\delta(I,w) \cap F \neq \emptyset$ if and only if $\delta'(I,w) \cap F \neq \emptyset$. So, we will show that $\delta(q,w) = \delta'(\{q\},w)$. We will show this by induction on $w$.
First, we have $w = \varepsilon$. Then $\delta(q,\varepsilon) = \{q\} = \delta'(\{q\},\varepsilon)$.
Now, let $w = ua$ with $a \in \Sigma$ and string $u \in \Sigma^*$ and assume that $\delta(q,u) = \delta'(\{q\},u)$. Then we have
\begin{align*}
\delta'(\{q\},ua) &= \delta'(\delta'(\{q\},u),a) &\text{(by definition of $\delta'$)}\\
&= \delta'(\delta(q,u),a) &\text{(by inductive hypothesis)}\\
&= \bigcup_{p \in \delta(q,u)} \delta(p,a) &\text{(by definition of $\delta'$)}\\
&= \delta(q,ua). &\text{(by definition of $\delta$)}
\end{align*}
Thus, we have shown that $\delta(q,w) = \delta'(\{q\},w)$ for all $q \in Q$ and $w \in \Sigma^*$, and we can conclude from the definition of the final states that $L(N) = L(\mathcal D(N))$.
Of course, this only gives us half of what we need, although what remains is fairly simple. We can just state the following.
A language $L$ is accepted by a DFA if and only if $L$ is accepted by an NFA.
We have already shown the only if direction of this theorem in Theorem 6.4. What's left to show is the if direction, which involves taking a DFA and constructing an equivalent NFA. This should be fairly simple to define and prove correctness for, so we won't go through it.
From this we get the following.
The class of DFA languages is closed under concatenation.
Let $A$ and $B$ be DFAs. By Theorem 5.4, there exists an NFA that accepts the language $L(A)L(B)$. Then by Theorem 6.5, there must exist a DFA that accepts $L(A)L(B)$.