Acceptance modes for PDAs
When we defined acceptance, we were careful to say that we were defining acceptance by final state. This implies that this is not the only model of acceptance for pushdown automata.
Let $P$ be a PDA. Then we can define the language of the machine by
$$ N(P) = \{w \in \Sigma^* \mid (q_0, w, Z_0) \vdash^* (q,\varepsilon,\varepsilon), q \in Q \}.$$
In other words, we accept a word if the stack is empty after reading it. Obviously, under this model, final states are superfluous, so PDAs using this acceptance model can be described by a 6-tuple instead.
As it turns out, the two models of acceptance are equivalent. That is given a PDA defined under one model of acceptance, it's possible to construct a PDA under the other model of acceptance which accepts the same language. We'll sketch out the constructions.
Let $A$ be a PDA that accepts by final state. Then there exists a PDA $A'$ which accepts $L(A)$ by empty stack.
Our new machine $A'$ needs to satisfy two properties. First of all, whenever $A$ reaches a final state on a word $w$ (that is, $A$ accepts $w$), we want to empty the stack. Secondly, we don't want the stack to ever be empty before the entire input is read.
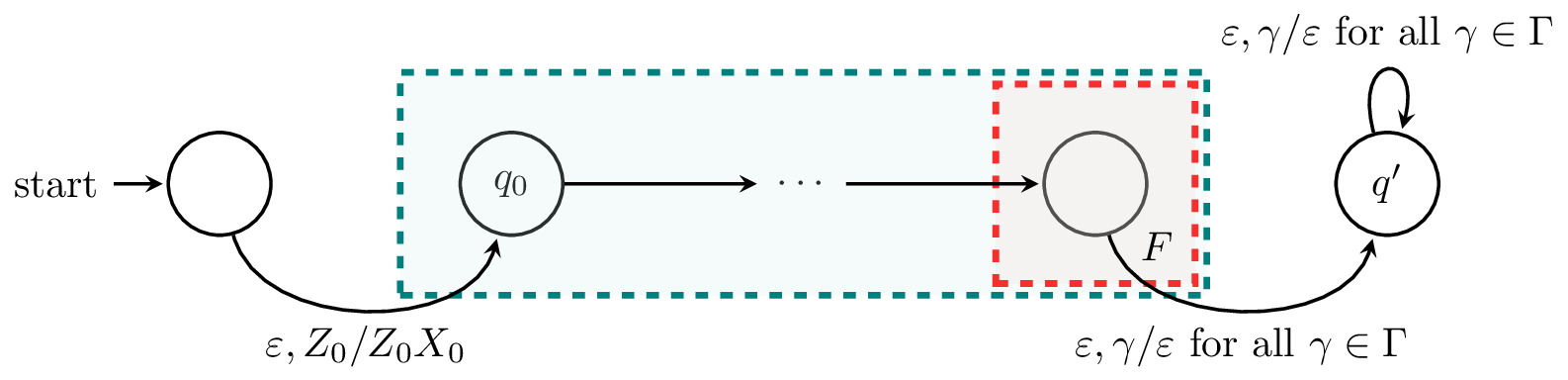
For the first property, we create a new state $q'$ and add transitions $\delta(q,\varepsilon,\gamma) = (q',\varepsilon)$ from every final state $q$ of $A$ to $q'$. Then $q'$ only contains transitions of the form $\delta(q',\varepsilon,\gamma) = (q',\varepsilon)$ for all $\gamma \in \Gamma$. Also note that any computation that enters $q'$ with part of the input still unread will crash.
For the second property, to prevent the stack from being empty during the course of the computation, we add a new symbol $X_0$ to the bottom of the stack. We do this by adding a new initial state with a transition to the initial state of $A$ whose only function is to place $X_0$ below $Z_0$ on the stack. Since $X_0$ is not in the stack alphabet of $A$, there is no transition that can remove it and the only way the stack can be empty is after visitng $q'$.
Let $B$ be a PDA that accepts by empty stack. Then there exists a PDA $B'$ which accepts $L(B)$ by final state.
To construct our new PDA $B'$, we need to ensure that the machine enters a final state whenever the machine would have emptied its stack and accepted. To do this, we add a new state $q'$ to $B'$ which is its sole accepting state.
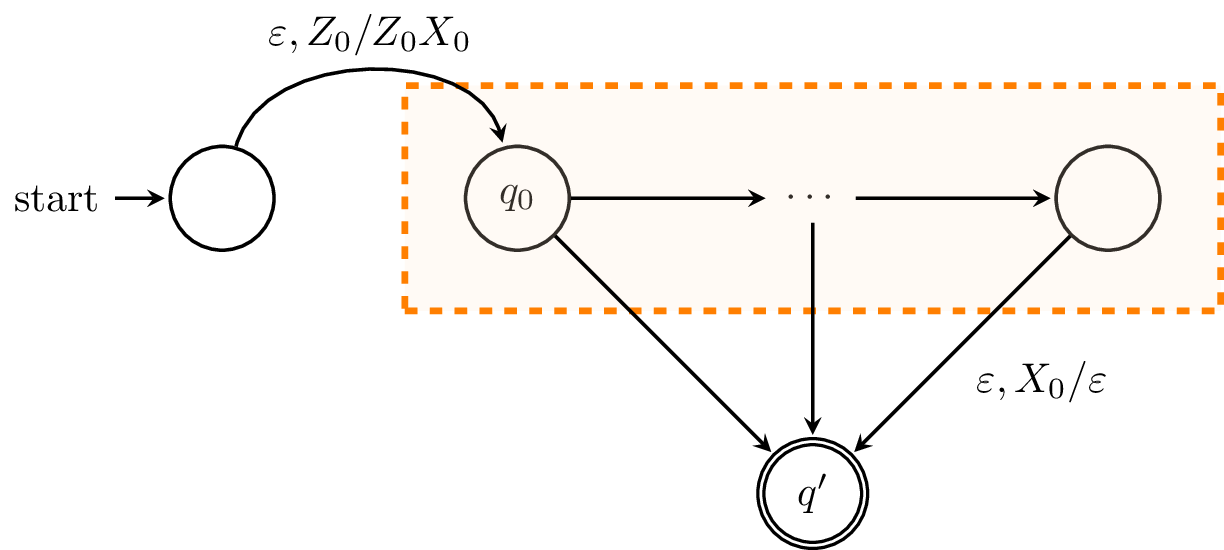
However, we also need a means of detecting that the stack is empty. To do this, we again add a new symbol $X_0$ to the stack alphabet and add a new initial state that adds $X_0$ to the stack below $Z_0$.
With this, we can add transitions $\delta(q,\varepsilon,X_0) = (q',\varepsilon)$ from every state $q$ of $B$. Since there are no transitions involving the stack symbol $X_0$ in $B$, it is clear that the machine only takes the transition to $q'$ whenever $B$ would have emptied its stack.
Equivalence of CFGs and PDAs
Just as regular expressions and finite automata happened to have a correspondence, so do context-free grammars and pushdown automata. For proofs in both directions, we'll take advantage of the fact that PDAs that accept via final state are equivalent to those that accept by empty stack. We will show that CFGs can be converted to PDAs that accept via empty stack and vice-versa. Since we already showed that these are equivalent with PDAs that accept via final state, we effectively show that these are equivalent to CFGs too.
Let $G$ be a context-free grammar. Then there exists a pushdown automaton $M$ such that $N(M) = L(G)$.
Let $G = (V,\Sigma,P,S)$ be a CFG. We will create a PDA $M = (Q,\Sigma,\Gamma, \delta, q_0, Z_0)$ which accepts by empty stack defined as follows:
- $Q = \{q\}$,
- $\Gamma = V \cup \Sigma$,
- $q_0 = q$,
- $Z_0 = S$,
and we define the following transitions
- $\delta(q,\varepsilon,A) = \{(q,\alpha) \mid A \to \alpha \in P\}$ for each variable $A \in V$,
- $\delta(q,a,a) = \{(q,\varepsilon)\}$ for each symbol $a \in \Sigma$.
Here is what the machine looks like.
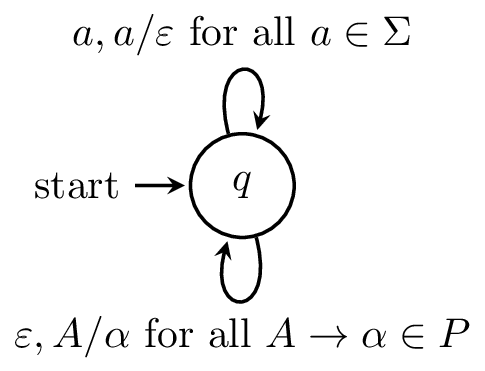
This machine essentially acts as a parser for $G$, albeit a nondeterministic one. And unlike many other machines we've seen before, the computation in this machine is driven primarily by the stack:
- Whenever we see a variable $A$ at the top of the stack, we pop it and replace it with the right hand side of a production $A \to \alpha$.
- Whenever we see a terminal $a$ at the top of the stack, we pop it and consume a symbol of the input word.
This process essentially performs a leftmost derivation of our input word. It's important to note that we can elide many of the tricky details of how we can ensure the correct production rule is chosen when we see $A$ through the magic of nondeterminism.
To formally prove this, we need to show that we have a derivation $S \Rightarrow^* w$ over $G$ if and only if there is a computation $(q,w,S) \vdash^* (q,\varepsilon,\varepsilon)$ in $M$. The details follow.
We will first show that $L(G) \subseteq N(M)$. Let $w \in L(G)$. There exists a leftmost derivation for $w$
$$S = \gamma_1 \Rightarrow \gamma_2 \Rightarrow \cdots \Rightarrow \gamma_n = w,$$
where $\gamma_i \in (V \cup \Sigma)^*$ for $1 \leq i \leq n$. Since this is a leftmost derivation, we can write $\gamma_i = x_i \alpha_i$, where $x_i \in \Sigma^*$ and $\alpha_i \in V(V \cup \Sigma)^*$ for $1 \leq i \leq n-1$. In other words, $\alpha_i$ begins with the leftmost variable of $\gamma_i$. Furthermore, $x_i$ must be a prefix of $w$ and for each $x_i$, we can write $w = x_i y_i$ for some $y_i \in \Sigma^*$.
We will show by induction on $i$, that if $S \Rightarrow^* \gamma_i = x_i \alpha_i$, then $(q,w,S) \vdash^* (q,y_i,\alpha_i)$ on the PDA $M$ for all $1 \leq i \leq n$.
For our base case, we take $i = 1$. We have $x_1 = \varepsilon$, $y_1 = w$, and $\alpha_1 = S$. Thus, we have $(q,w,S) \vdash^* (q,y_i,\alpha_i)$ trivially.
For our inductive hypothesis, we assume that $(q,w,S) \vdash^* (q,y_j,\alpha_j)$ for all $j < i$. So suppose we have $S \Rightarrow^* \gamma_{i-1} = x_{i-1} \alpha_{i-1}$. By the inductive hypothesis, there exists a computation $(q,w,S) \vdash^* (q,y_{i-1},\alpha_{i-1})$, where
- we can write the input string as $w = x_{i-1} y_{i-1}$, and
- we can write the sentential form $\alpha_{i-1}$ starting explicitly with a variable $A_{i-1}$ by $\alpha_{i-1} = A_{i-1} \eta_{i-1}$ for some $\eta_{i-1} \in (V \cup \Sigma)^*$, and $\gamma_{i-1} = x_{i-1} \alpha_{i-1}$.
At this point, there is a variable $A_{i-1}$ at the top of the stack. Since we want a sentential form $x_i \alpha_i$, where the first symbol of $\alpha_i$ is a variable, this means we need to do the following:
- Pop $A_{i-1}$ off the stack.
- Replace $A_{i-1}$ by applying some production.
- Consume any terminals on the stack until there is a variable at the top.
So we pop $A_{i-1}$ off the stack. Since we have a leftmost derivation of $w$, there must exist a production $A_{i-1} \to \beta_{i-1}$ in $G$ for some $\beta_{i-1} \in (V \cup \Sigma)^*$. By our definition of $M$, there is a transition with $(q,\beta_{i-1}) \in \delta(q,\varepsilon,A_{i-1})$. Therefore, we have $(q,y_{i-1},\alpha_{i-1}) \vdash (q,y_{i-1},\beta_{i-1}\eta_{i-1})$. That is, the machine pops $A_{i-1}$ off the stack and applies the rule $A_{i-1} \to \beta_{i-1}$ by putting $\beta_{i-1}$ on the stack.
At this point, $\beta_{i-1}$ is on the top of the stack. However, $\beta_{i-1}$ is an arbitrary sentential form made up of terminals and non-terminals. To consume terminals on the stack, we must have the same symbols in our input string and apply the rule $\delta(q,a,a) = \{(q,\varepsilon)\}$ for $a \in \Sigma$.
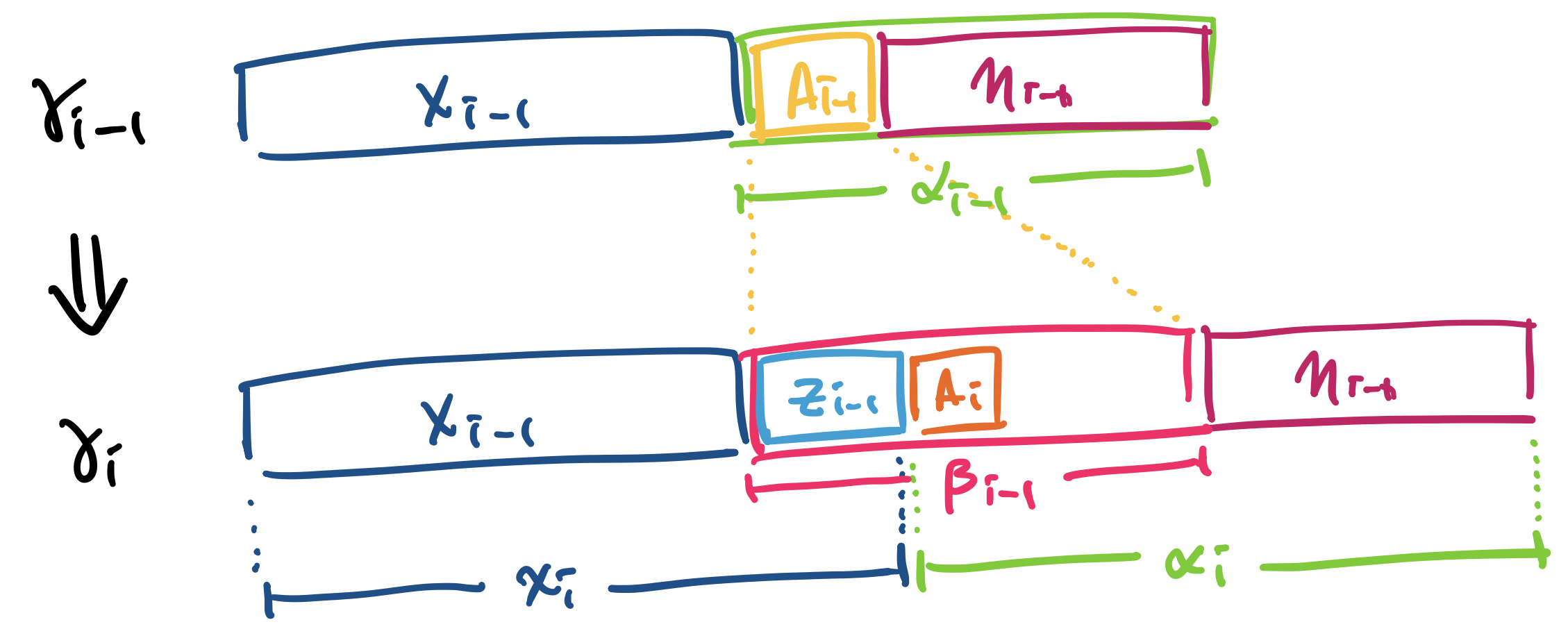
Let $z_{i-1}$ denote the symbols on the top of the stack to be consumed.
- We rewrite $y_{i-1}$, the remaining input, as $y_{i-1} = z_{i-1} y_i$.
- We rewrite the stack contents as $\beta_{i-1} \eta_{i-1} = z_{i-1} \alpha_i$, where $z_{i-1} \in \Sigma^*$.
- Then $x_i = x_{i-1} z_{i-1}$.
Reading $z_{i-1}$ then gives us
$$(q,y_{i-1},\alpha_{i-1}) = (q,y_{i-1}, A_{i-1} \eta_{i-1}) \vdash (q, y_{i-1}, \beta_{i-1} \eta_{i-1}) = (q, z_{i-1} y_i, z_{i-1} \alpha_i) \vdash^* (q,y_i,\alpha_i).$$
Thus, we have shown that for each $i$, we have $(q,w,S) \vdash^* (q,y_i,\alpha_i)$. Then taking $i = n$, we have
$$(q,w,S) \vdash^* (q,y_n,\alpha_n) = (q,\varepsilon,\varepsilon)$$
and thus $w \in N(M)$ as desired.
Next, we will show that $N(M) \subseteq L(G)$. Let $w \in N(M)$. We will show that for any variable $A \in V$, if $(q,w,A) \vdash^* (q,\varepsilon,\varepsilon)$, then $A \Rightarrow^* w$. We will show this by induction on $n$, then length of an accepting computation $(q,w,A) \vdash^* (q,\varepsilon,\varepsilon)$.
For our base case, we have $n = 1$, since $A \neq \varepsilon$. Since $A$ is at the top of the stack, we must choose a transition of the form $\delta(q,\varepsilon,A)$. However, this means that $w = \varepsilon$ and $(q,\varepsilon) \in \delta(q,\varepsilon,A)$ and this implies that there is a rule $A \to \varepsilon$ in $G$. Thus, we have $A \Rightarrow^* w$.
Now, suppose that $n > 1$ and for our inductive hypothesis, we assume that for all variables $A \in V$, if the length of a computation $(q,w,A) \vdash^* (q,\varepsilon,\varepsilon)$ of $M$ is fewer than $n$ steps, then $A \Rightarrow^* w$. Consider a computation $(q,w,A) \vdash^* (q,\varepsilon,\varepsilon)$ of length $n$.
Again, we must first take a transition $\delta(q,\varepsilon,A)$ since $A$ is on the top of the stack. This time, we take the transition corresponding to a rule of the form $A \to Y_1 \cdots Y_k$, where $Y_1, \dots, Y_k \in (V \cup \Sigma)$, and we have $(q,w,A) \vdash (q,w,Y_1 \cdots Y_k)$. From here, consider the following computation,
$$(q,w,A) \vdash (q,w,Y_1 \cdots Y_k) \vdash^* (q,x_1,Y_2 \cdots Y_k)$$
where $x_1$ is a suffix of $w$ with $w = w_1 x_1$.
In other words, we have $(q,w_1 x_1,Y_1 \cdots Y_k) \vdash^* (q,x_1,Y_2 \cdots Y_k)$. Now, we make use of the following observation: the computation
$$(q,w_1,Y_1 \cdots Y_k) \vdash^* (q,\varepsilon,Y_2 \cdots Y_k)$$
is also a valid computation in $M$. The reasoning is simple: the computation clearly does not depend on $x_1$, since none of $x_1$ was read. If our input word were simply $w_1$, we would have exactly the above computation. However, this leads us to another similarly useful observation we can make: the computation
$$(q,w_1,Y_1) \vdash^* (q,\varepsilon,\varepsilon)$$
is also a valid computation in $M$. The reasoning is similar: if we began our computation of $w_1$ with only $Y_1$ on the stack, we would arrive at the same configuration since $Y_2 \cdots Y_k$ were inconsequential to the computation.
Now, we observe that we have one of two possibilities.
- If $Y_1 \in \Sigma$, then $(q,w_1,Y_1) \vdash (q,\varepsilon,\varepsilon)$ implies that $w_1 = Y_1$ and we have $Y_1 \Rightarrow^* w_1$ trivially.
- Otherwise, we have $Y_1 \in V$ and since $(q,w_1,Y_1) \vdash (q,\varepsilon,\varepsilon)$ is a computation of length less than $n$, we have $Y_1 \Rightarrow^* w_1$ by the inductive hypothesis.
We can now return to the computation
$$(q,w,A) \vdash (q,w,Y_1 \cdots Y_k) \vdash^* (q,x_1,Y_2 \cdots Y_k)$$
and observe that we have
$$(q,x_{i-2},Y_{i-1} \cdots Y_k) = (q,w_{i-1} x_{i-1},Y_{i-1} \cdots Y_k) \vdash^* (q,x_{i-1},Y_i \cdots Y_k)$$
for every $1 \leq i \leq k$. So we can apply a similar argument to obtain derivations $Y_i \Rightarrow^* w_i$ for $w = w_1 \cdots w_k$. This gives us our derivation,
$$A \Rightarrow Y_1 \cdots Y_k \Rightarrow^* w_1 Y_2 \cdots Y_k \Rightarrow^* w_1 w_2 Y_3 \cdots Y_k \Rightarrow^* w_1 \cdots w_k = w$$
and thus $A \Rightarrow^* w$. Taking $A = S$, we have $S \Rightarrow^* w$ and $w \in L(G)$ as desired.
Consider the grammar for palindromes,
$$S \rightarrow aSa \mid bSb \mid a \mid b \mid \varepsilon,$$
and consider a PDA $P$ for this grammar, which we obtain by following the construction of Theorem 17.4. Then a computation of $P$ on the word $aababaa$ looks like
\begin{align*}
(q,aababaa,S) & \vdash (q,aababaa,aSa) \\ & \vdash (q,ababaa,Sa) \\ & \vdash (q,ababaa,aSaa) \\ & \vdash (q,babaa,Saa) \\ & \vdash (q,babaa,bSbaa) \\ & \vdash (q,abaa,Sbaa) \\ & \vdash (q,abaa,abaa) \\ & \vdash (q,baa,baa) \\ & \vdash (q,aa,aa) \\ & \vdash (q,a,a) \\ & \vdash (q,\varepsilon, \varepsilon)
\end{align*}
Now, we'll consider the other direction. We won't go through all the details this time.
Let $M$ be a pushdown automaton. Then there exists a context-free grammar $G$ such that $L(G) = N(M)$.
Let $M = (Q,\Sigma,\Gamma,\delta,q_0,Z_0)$ be a PDA that accepts by empty stack. We want to simulate the process of performing a computation on $M$ via a grammar $G$. Suppose we have an accepting computation on a string and consider one step of such a computation
$$(q,au,X) \vdash (q',u,Y_1 \cdots Y_k)$$
where $q,q' \in Q$, $u \in \Sigma^*$, $a \in \Sigma \cup \{\varepsilon\}$, and $X, Y_1, \dots, Y_K \in \Gamma$.
In this computation, we follow the transition $(q',Y_1 \cdots Y_k) \in \delta(q,a,X)$. Note that $a \in \Sigma \cup \{\varepsilon\}$. Because the PDA has to empty its stack in order to accept this string, the computation proceeds and at some point we end up in a configuration $(q_1,u_1,Y_2 \cdots Y_k)$. Afterwards, we continue the computation, removing each $Y_i$ and consuming the input word until we end up in a configuration $(r,\varepsilon,\varepsilon)$ for some state $r \in Q$.
We will construct a CFG $G = (V,\Gamma,P,S)$ that generates $N(M)$. First, we define the set of variables $V$ by
$$ V = \{S\} \cup \{A_{q,X,r} \mid q,r \in Q, X \in \Gamma\}.$$
Much like the DFA to regular expression proof, we try to solve the slightly more general problem of describing all strings between every pair of states in our machine. Here, we define a variable based on the pair of states $q,r \in Q$. But in the PDA, we also have another object driving the computation: the stack. So we include the item $X$ that is at the top of the stack to be popped.
This results in the variable $A_{q,X,r}$. We want that $A_{q,X,r} \Rightarrow^* w$ for a word $w$ if and only if $(q,w,X) \vdash^* (r,\varepsilon,\varepsilon)$. That is, $A_{q,X,r}$ generates all strings $w$ such that there is a computation on input $w$ from $q$ to $r$ with $X$ initially at the top of the stack.
We then need to define our set of productions appropriately. Consider a transition $(r_0,Y_1 \cdots Y_k) \in \delta(q,a,X)$ as above. There are two cases.
- If we have $(r_0,\varepsilon)$, then no items are placed on the stack. We add the production
$$A_{q,X,r_0} \to a.$$
This represents the action of popping $X$ off the stack, reading a symbol $a$, and moving to state $r_0$.
- If $k \geq 1$, we do add items on to the stack. So we add productions of the form
$$A_{q,X,r_k} \to aA_{r_0,Y_1,r_1} A_{r_1,Y_2,r_2} \cdots A_{r_{k-1},Y_k,r_k}$$
for all possible $r_1, \dots, r_k \in Q$.
Be careful of the subscripts here: note that though we have a transition to the state $r_0$, the variable we are defining is $A_{q,X,r_k}$. Why do we define the variable this way?
Recall that we had the transition $(r_0, Y_1 \cdots Y_k) \in \delta(q,a,X)$. So what we try to represent is the action of reading a symbol $a$, popping $X$ from the stack, pushing $Y_1 \cdots Y_k$ on to the stack, and moving to state $r_0$.
However, all of those things we pushed onto the stack need to get removed over the course of the computation. So they will all be involved in generating some part of our input string. But what would the state of this machine actually look like after, say, removing $Y_1$?
Recall that we've just performed the computation step
\[(q,au,X) \vdash (r_0, u, Y_1 Y_2 \cdots Y_k).\]
If we proceed from this configuration, we pop $Y_1$, but this does not leave us with a stack with $Y_2$ on the top. The transition on $Y_1$ could leave us with even more stuff on the stack, like
\[(r_0, u, Y_1 Y_2 \cdots Y_k) \vdash (r_0', u', Z_1 Z_2 \cdots Z_\ell Y_2 \cdots Y_k).\]
But because we know we have to clear out the stack, we know that $Y_2$ must return to the top of the stack at some point. How much of the input string have we read at that point? What is the state that the PDA is in at that point? Those are things that we don't know, but have to guess:
\[(r_0, u, Y_1 Y_2 \cdots Y_k) \vdash^* (r_1, u', Y_2 \cdots Y_k).\]
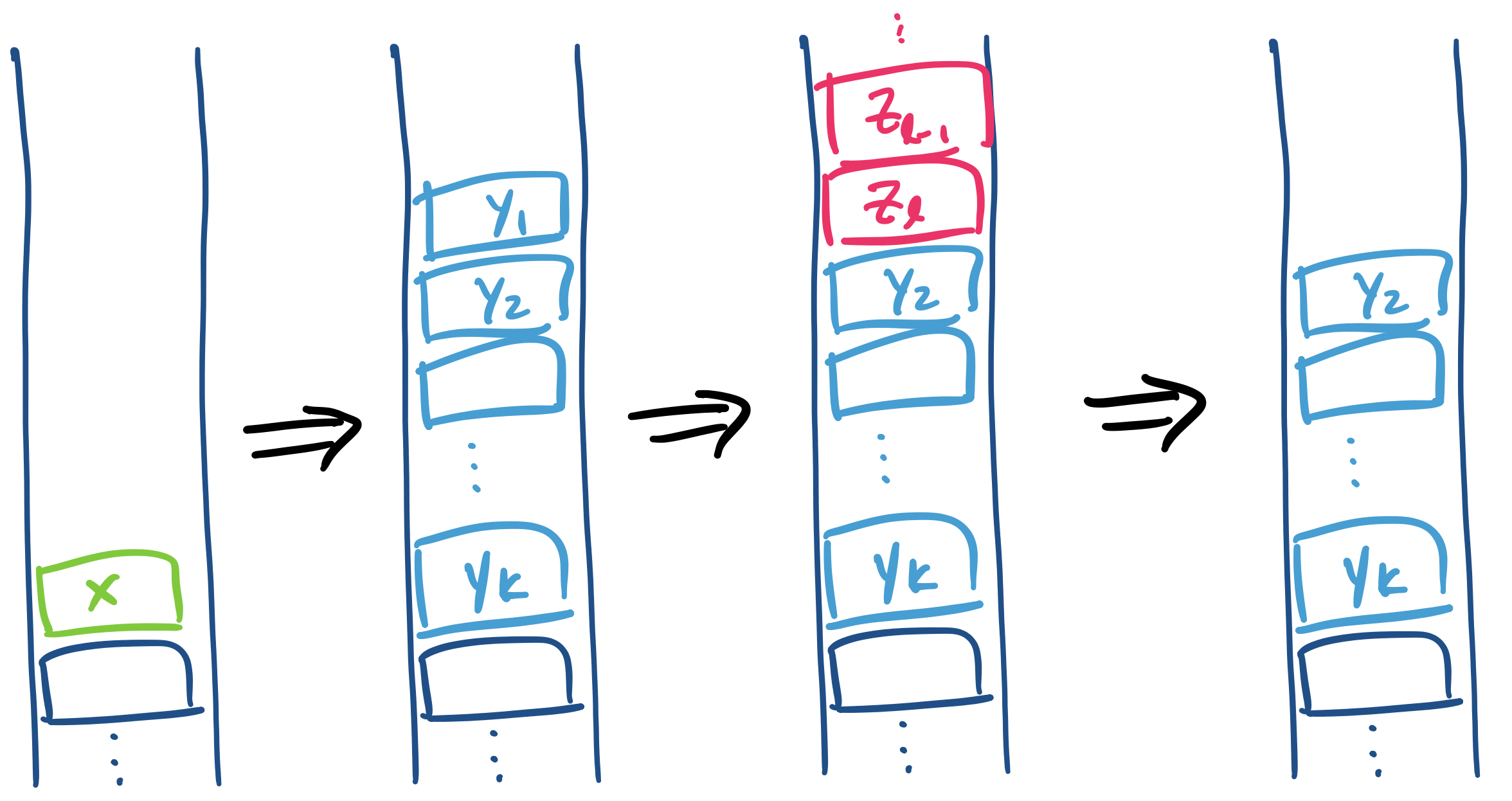
In essence, we should think of the variable $A_{q,X,r}$ primarily as being about clearing out $X$ off of the stack and the possible strings that get consumed by the PDA (and hence generated by our grammar). The states at which it begins and ends this process is a detail that we fill in after the fact by considering all possible sequences of states $r_1, \dots, r_k$ such that we can pop $Y_1 \cdots Y_k$.
There is a question of whether we can actually do this thing of taking all the possible sequences of states, since it seems like there could be an infinite number of such sequences. However, note that each of these production is based on a transition and the number of stack symbols that transition pushes onto the stack. Since this number is fixed, we only need to consider all of these combinations: if there are $n$ states in the PDA and our transition pushes $k$ stack symbols on to the stack, that's only $n^k$ different productions that we need to add. Not all of the variables will be useful, and those that are will be the ones that admit a valid derivation.
Since we want to generate all words such that the PDA $M$ reaches a configuration with an empty stack, we add transitions for all states $q \in Q$ and the start state $q_0$
$$S \to A_{q_0,Z_0,q}.$$
From this, we have $(q_0,w,Z_0) \vdash^* (q,\varepsilon,\varepsilon)$ if and only if $S \Rightarrow A_{q_0,Z_0,q} \Rightarrow^* w$.