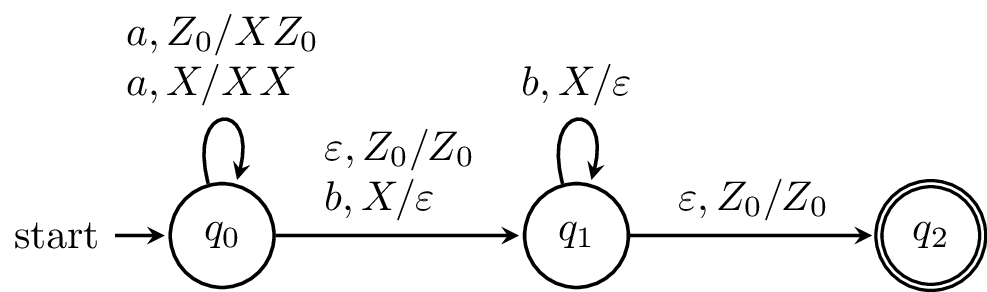
Here, we have a PDA that we claim recognizes the language $\{a^k b^k \mid k \geq 0\}$. In order to verify our claim, we'll need to formalize notions of what it means for a PDA to "recognize" or "accept" a language. And in order to do that, we'll need to formalize the notion of what it means for a word to move through a PDA.
Describing the computation of an NFA was simple, since it's really just a path and all we needed to know to describe what the state of the NFA was is how far in the input string the NFA is and what state(s) the NFA is on. With the PDA, there is one more piece of information that we need to take into account: the stack.
The description of the state of a PDA is called the configuration of a PDA and it is a 3-tuple $(q,w,\gamma)$, where
Now, we want to describe transitions from one configuration to another in the PDA.
We define the relation $\vdash$ on configurations by $(q,aw, X\gamma) \vdash (q',w,\beta\gamma)$ if and only if $(q',\beta) \in \delta(q,a,X)$. We can then define the closure of $\vdash$ by
A computation in a PDA $P$ is a sequence of configurations $C_1, C_2, \dots, C_n$, where $C_1 \vdash C_2 \vdash \cdots \vdash C_n$.
We say a PDA $P$ accepts a word $x$ by final state if $(q_0,x,Z_0) \vdash^* (q,\varepsilon, \gamma)$ for some $q \in F$ and $\gamma \in \Gamma^*$. The language of a PDA $P$ is $$ L(P) = \{w \in \Sigma^* \mid \text{ $P$ accepts $w$ }\}.$$
Let's look at the PDA from earlier again.
We can describe how this PDA works informally. The PDA begins by reading $a$'s and for each $a$ that's read, an $X$ is put on the stack. Then, once a $b$ is read, and the computation moves onto the next state. For every $b$ that is read, an $X$ is taken off the stack. The machine can only reach the final state if the stack is empty and there is no more input to be read.
We can trace a computation on the word $aabb$ to see how this works. We begin in the initial configuration $(q_0,aabb,Z_0)$. Then our computation looks like this: $$(q_0,aabb,Z_0) \vdash (q_0,abb,XZ_0) \vdash (q_0,bb,XXZ_0) \vdash (q_1,b,XZ_0) \vdash (q_1,\varepsilon,Z_0) \vdash (q_2,\varepsilon,Z_0).$$
Note that the definition of the transition function prevents any other word from reaching the final state. For instance, $a$'s can't be read after moving to $q_1$, otherwise the machine will crash. Similarly, if a $b$ is read and there are is no corresponding stack symbol, the machine crashes, and a $\varepsilon$-transition can only be taken to reach the final state if the stack is empty.
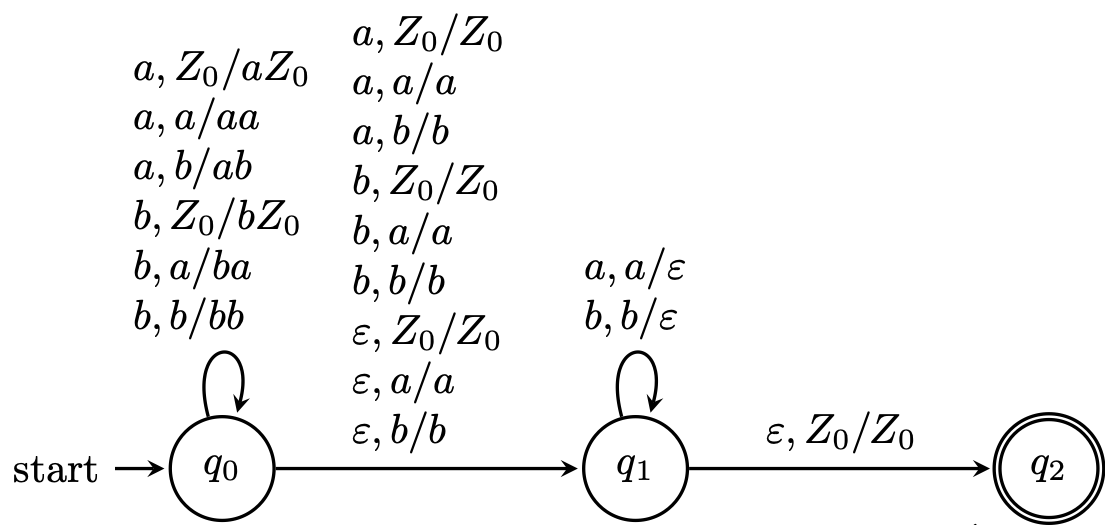
Here, we want to define a PDA that recognizes the language of palindromes, $$\{w \in \{a,b\}^* \mid w = w^R \}.$$
The idea is quite simple: we can read $w$ and keep track of it on the stack until we reach halfway through the string. Once we do that, we just need to make sure that the rest of the word matches the reverse of $w$. Luckily, this is exactly how stacks work. However, there's a problem: how do we know we're halfway?
Since we have a nondeterministic machine, we are able to guess when we're halfway.
\begin{tikzpicture}[shorten >=1pt,on grid,node distance=3.5cm,>=stealth,thick,auto]
\node[state,initial] (0) {$q_0$};
\node[state] (1) [right of=0]{$q_1$};
\node[state,accepting] (2) [right of=1] {$q_2$};
\path[->]
(0) edge [loop above] node [align=left] {$a,Z_0/aZ_0$ \\ $a,a/aa$ \\ $a,b/ab$ \\ $b,Z_0/bZ_0$ \\ $b,a/ba$ \\ $b,b/bb$} (0)
(0) edge node [align=left] {$a,Z_0/Z_0$ \\ $a,a/a$ \\ $a,b/b$ \\ $b,Z_0/Z_0$ \\ $b,a/a$ \\ $b,b/b$ \\ $\varepsilon, Z_0/Z_0$ \\ $\varepsilon,a/a$ \\ $\varepsilon,b/b$} (1)
(1) edge [loop above] node [align=left] {$a,a/\varepsilon$ \\ $b,b/\varepsilon$} (1)
(1) edge node [align=left] {$\varepsilon,Z_0/Z_0$} (2)
;
\end{tikzpicture}
from automata.pda.npda import NPDA
A = NPDA(
states={f'q{i}' for i in range(3)},
input_symbols=set('ab'),
stack_symbols=set('abZ'),
transitions={
'q0': {
'a': {
'Z': {('q0', 'aZ'), ('q1', 'Z')},
'a': {('q0', 'aa'), ('q1', 'a')},
'b': {('q0', 'ab'), ('q1', 'b')}
},
'b': {
'Z': {('q0', 'bZ'), ('q1', 'Z')},
'a': {('q0', 'ba'), ('q1', 'a')},
'b': {('q0', 'bb'), ('q1', 'b')}
},
'': {
'Z': {('q1', 'Z')},
'a': {('q1', 'a')},
'b': {('q1', 'b')}
}
},
'q1': {
'a': {'a': {('q1', '')}},
'b': {'b': {('q1', '')}},
'': {'Z': {('q2', 'Z')}}
}
},
initial_state='q0',
initial_stack_symbol='Z',
final_states={'q2'}
)
Here, our machine reads the first half of the string in $q_0$ and stores it on the stack. It nondeterministically guesses the middle of the string, which is a symbol if the palindrome is odd and $\varepsilon$ if the palindrome is even, and does not modify the stack. This guess moves the machine to state $q_1$, where it tries to match each symbol with what's stored on the stack. If the stack is emptied, this means we have successfully read the second half of the string that matches the reverse of the first half, and we may move to $q_2$ to accept.
Like the example above, processing the latter part of the word depends on what is on the stack. If the lengths of the stack and the second half of the word don't match up, then the machine crashes. Similarly, if a symbol is read that doesn't match what's on the stack, then the machine crashes.
Here, we trace one possible computation of the word $abba$, \begin{align*} (q_0,abba,Z_0) &\vdash (q_0,bba,aZ_0) \vdash (q_0,ba,baZ_0) \\ &\vdash (q_1,ba,baZ_0) \vdash (q_1,a,aZ_0) \vdash (q_1,\varepsilon,Z_0) \\ &\vdash (q_2,\varepsilon,Z_0). \end{align*}
Here is a computation on the same word that fails, \[(q_0,abba,Z_0) \vdash (q_0,bba,aZ_0) \vdash (q_0,ba,baZ_0) \vdash (q_0,a,bbaZ_0) \vdash (q_1,a,bbaZ_0).\] Since there is no transition in $q_1$ on input symbol $a$ and stack symbol $b$, our computation crashes at this point.
Here is the entire set of possible configurations:
>>> for i, c in enumerate(A.read_input_stepwise('abba')):
... print(f'Step {i}: {c}')
...
Step 0: {PDAConfiguration('q0', 'abba', PDAStack(('Z',)))}
Step 1: {PDAConfiguration('q1', 'bba', PDAStack(('Z',))),
PDAConfiguration('q0', 'bba', PDAStack(('Z', 'a'))),
PDAConfiguration('q1', 'abba', PDAStack(('Z',)))}
Step 2: {PDAConfiguration('q2', 'bba', PDAStack(('Z',))),
PDAConfiguration('q0', 'ba', PDAStack(('Z', 'a', 'b'))),
PDAConfiguration('q2', 'abba', PDAStack(('Z',))),
PDAConfiguration('q1', 'ba', PDAStack(('Z', 'a'))),
PDAConfiguration('q1', 'bba', PDAStack(('Z', 'a')))}
Step 3: {PDAConfiguration('q0', 'a', PDAStack(('Z', 'a', 'b', 'b'))),
PDAConfiguration('q1', 'a', PDAStack(('Z', 'a', 'b'))),
PDAConfiguration('q1', 'ba', PDAStack(('Z', 'a', 'b')))}
Step 4: {PDAConfiguration('q1', 'a', PDAStack(('Z', 'a', 'b', 'b'))),
PDAConfiguration('q1', 'a', PDAStack(('Z', 'a'))),
PDAConfiguration('q0', '', PDAStack(('Z', 'a', 'b', 'b', 'a'))),
PDAConfiguration('q1', '', PDAStack(('Z', 'a', 'b', 'b')))}
Step 5: {PDAConfiguration('q1', '', PDAStack(('Z',))),
PDAConfiguration('q1', '', PDAStack(('Z', 'a', 'b', 'b', 'a')))}
Step 6: {PDAConfiguration('q2', '', PDAStack(('Z',)))}
We saw earlier that context-free languages are closed under the regular operations: union, concatenation and star. A natural follow-up question is to see how far this goes—do we get all the same closure properties as regular languages?
To prove closure properties, we apply the same methods as before: show that there's a representation for our language resulting from the operation. For context-free grammars, this typically means constructing a CFG from other CFGs. However, just as with regular languages, with PDAs, we now have multiple equivalent representations for context-free languages (or at least we will once we prove this). And just like with regular languages, some things are harder or easier to prove in one model over the other. Once we prove that PDAs and CFGs are equivalent models,, we can prove things about context-free languages that were maybe too cumbersome to do with grammars.
For instance, PDAs give us a nice way to work with regular languages. Here, we'll show that CFLs are closed under intersection with a regular language. This might seem strange at first, but it turns out to be quite handy.
Let $L \subseteq \Sigma$ be a context-free language and let $R \subseteq \Sigma^*$ be a regular language. Then $L \cap R$ is a context-free language.
Let $A = (Q_A,\Sigma,\Gamma,\delta_A,s_A,Z_0,F_A)$ be a PDA that accepts $L$ and let $B = (Q_B, \Sigma, \delta_B, s_B, F_B)$ be a DFA that recognizes $R$. We will construct a PDA $C = (Q_C, \Sigma, \Gamma, \delta_C, s_C, Z_0, F_C)$ that recognizes $L \cap R$. We have
The PDA $C$ works by simultaneously moving through a computation of $A$ and $B$. When a transition is made, $C$ will keep track of the current state of $A$ via the first component of each state of $C$ and by using the stack as normal. The current state of $B$ is kept track of as the second component of the states of $C$. In addition, when $A$ makes $\varepsilon$-transitions, the state of $B$ does not change.
It is not too difficult to see that in this way, $C$ can move simultaneously through $A$ and $B$. Then, the set of accepting states of $C$ is defined to be pairs of states in $F_A$ and $F_B$. In other words, a word accepted by $C$ must have a computation that ends in a state $\langle p,q \rangle$ with $p \in F_A$ and $q \in F_B$. In other words, there is a computation for $w$ on $A$ that ends in a final state and there is a computation for $w$ on $B$ that ends in a final state. Thus, $C$ accepts $w$ if and only if $w$ is accepted by both $A$ and $B$ and this is only the case if and only if $w \in L \cap R$. Thus, $C$ is a PDA that accepts $L \cap R$ and $L \cap R$ is a context-free language.
Why would you want to take an intersection with a regular language? Recall that we can treat intersection with a language as kind of a filter. Regular languages happen to be quite handy for this—they're simple enough to describe and a lot of common "patterns" can be expressed as regular languages.
But how about intersection of two context-free languages? That poses a bit more of a challenge. For one thing, our product construction approach will fail—there's no obvious way to "share" a stack. For now, we're stuck and will have to keep this in the back of our minds.