We are continuing the example from last time. We want to determine whether $cabab$ is generated by the following grammar. \begin{align*} S &\rightarrow BC \mid b \\ A &\rightarrow BC \mid b \\ B &\rightarrow DC \mid BB \mid a \\ C &\rightarrow BA \mid b \\ D &\rightarrow CA \mid c \end{align*}
We will now consider substrings of length 3. Here, we have to do a bit more work, because strings of length 3, say $xyz$ can be generated by two variables by $xy$ and $z$ or $x$ and $yz$. We must check both possibilities. For example, for the string $cab$, we can generate it either by $ca$ and $b$ or by $c$ and $ab$. In the first case, $ca$ has no derivation, but the second case gives us a valid derivation, since $ab$ can be generated by $S$, $A$, or $C$ and we have $B \Rightarrow DC \Rightarrow cab$.
| $c$ | $a$ | $b$ | $a$ | $b$ | |
| 1 | 2 | 3 | 4 | 5 | |
| 1 | $D$ | $\emptyset$ | $B$ | ||
| 2 | $B$ | $S,A,C$ | $\emptyset$ | ||
| 3 | $S,A,C$ | $\emptyset$ | $D$ | ||
| 4 | $B$ | $S,A,C$ | |||
| 5 | $S,A,C$ |
We continue with strings of length 4. Again, we have to consider all of the ways to split up a string of length 4 into two substrings.
| $c$ | $a$ | $b$ | $a$ | $b$ | |
| 1 | 2 | 3 | 4 | 5 | |
| 1 | $D$ | $\emptyset$ | $B$ | $B$ | |
| 2 | $B$ | $S,A,C$ | $\emptyset$ | $D$ | |
| 3 | $S,A,C$ | $\emptyset$ | $D$ | ||
| 4 | $B$ | $S,A,C$ | |||
| 5 | $S,A,C$ |
Finally, we finish with the string of length 5, our original string $w$. We have constructed a table that tells us which variables can generate each substring $w$. To determine whether $w \in L(G)$, we simply need to see whether the substring corresponding to $w$ (i.e. $w[1..5]$ has a derivation that begins with $S$. We see that it does, so $w \in L(G)$.
| $c$ | $a$ | $b$ | $a$ | $b$ | |
| 1 | 2 | 3 | 4 | 5 | |
| 1 | $D$ | $\emptyset$ | $B$ | $B$ | $S,A,C$ |
| 2 | $B$ | $S,A,C$ | $\emptyset$ | $D$ | |
| 3 | $S,A,C$ | $\emptyset$ | $D$ | ||
| 4 | $B$ | $S,A,C$ | |||
| 5 | $S,A,C$ |
Since CYK is a dynamic programming algorithm, the running time is not complicated to figure out.
Given a CFG $G$ in Chomsky Normal Form and string $w$ of length $n$, we can determine whether $w \in L(G)$ in $O(n^3 |G|)$ time.
CYK takes $O(n^3)$ time since it has three loops: for each substring length $\ell$ from 1 to $n$, consider each substring of length $\ell$ (of which there are $O(n)$), and consider all of the ways to split this substring into two (again, $O(n)$). Alternatively, we can see that we are filling out an $n \times n$ table (about $O(n^2)$), where each entry requires the traversal of the associated row and column ($O(n)$), which gives us our $O(n^3)$ bound. This puts us into polynomial time, which is much better than our "try every derivation" approach.
As a side note, Leslie Valiant showed in 1975 that computing the CYK table can be reduced to boolean matrix multiplication, which at the time that most current formal languages books were printed had a time complexity of $O(n^{2.376})$-ish, due to Coppersmith and Winograd in 1990. This was true until about 2010 (i.e. 20 years later), when there was a series of small improvements, the most recent of which was due to Vassilevska Williams, Xu, Xu, and Zhou earlier this year (2024), clocking in at $O(n^{2.371552})$.
However, the same goes the other way around: matrix multiplication can't do any better than whatever algorithm we muster up for parsing context-free grammars, because Lillian Lee showed in 2002 that you can solve matrix multiplication by turning it into context-free grammar parsing. The consequence of this is that we don't really know if we can do parsing better than $O(n^2)$.
The more immediate problem is that $O(n^3)$ is still really big, if you think about your typical large software codebase and the amount of time it takes to build a project and how mad everyone gets when you break the build. Ideally, we would like something that runs in linear time, or in other words, something where we can essentially read our input once and parse it correctly without having to go back over it. This requires that attention is restricted to various subclasses of context-free languages.
So we know that CFGs can generate languages that aren't regular, but how exactly are context-free languages more powerful than regular languages? It's helpful to refer to a family of languages we've encountered briefly: the language of balanced parentheses. While we saw the grammar for balancing one type of parentheses, we can define a family of langauges where we have, say, $n$ types of parentheses and we want all the strings of those parentheses properly balaned.
Such a family of languages is called the Dyck languages, for Walther von Dyck, known for his contributions to combinatorial group theory. Dyck languages happen to have some interesting combinatorial and algebraic properties. In formal language theory, the Dyck languages give an important characterization for the context-free languages.
Theorem (Chomsky–Schützenberger). Every context-free language is a homomorphic image of the intersection of a Dyck language and a regular language.
The theorem is due to Chomsky and Schützenberger in 1963. A proof of the Chomsky–Schützenberger theorem can be found in Kozen, Chapter G.
Here, a homomorphism is a function $h:\Sigma^* \to \Gamma^*$ such that $h(uv) = h(u)h(v)$. The basic idea behind morphisms is that they map words in $\Sigma^*$ to words in $\Gamma^*$, where $\Sigma$ and $\Gamma$ are alphabets, while preserving the structure of the word.
The Chomsky–Schützenberger theorem tells us that every context-free language can be described by a regular language, a Dyck language, and a morphism. Since regular languages are closed under homomorphisms, what this tells us is that what really separates regular languages from context-free languages is the ability to express "nestedness", in the sense of brackets or trees. We will explore this idea by returning to the notion of a machine.
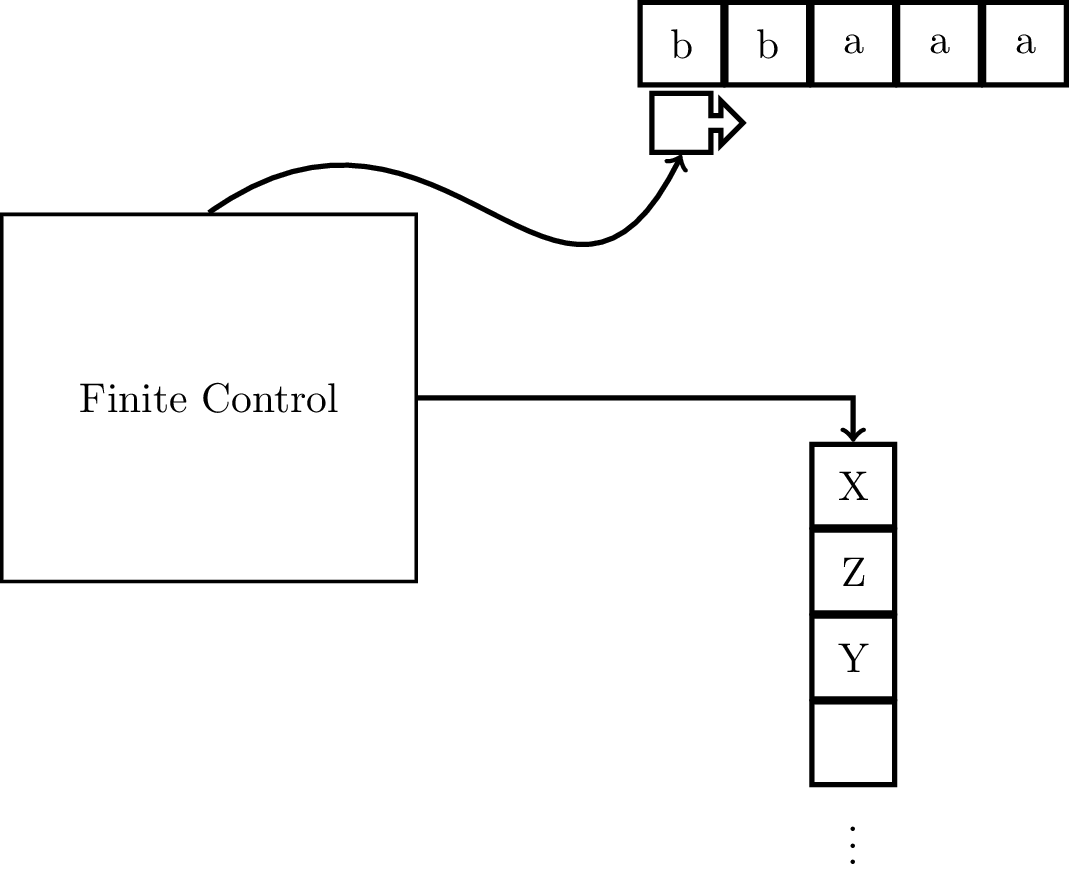
Recall that a finite automaton is limited in two important ways: the input can only be read once and it only has a finite amount of memory. We will be augmenting the NFA to take care of the second problem, by giving it access to a stack with unlimited memory.
Recall that a stack is a data structure in which one can
These are called stacks because of the analogy piling a stack of (plates/books/papers/to-do items). You add items to your metaphorical stack by putting stuff on top and you can only remove items from your stack by taking things off the top.
The idea is that when you read a symbol on the input tape, you also take a symbol off of the stack. The transition depends on three pieces of information: the symbol you read on the input tape, the current state, and the symbol on the top of the stack. These determine what the next state is and what gets put onto the stack. So although the machine now has access to unlimited memory, there are restrictions on how it is able to access this memory.
Going back to the Chomsky–Schützenberger characterization for context-free languages, we can see that a PDA is "almost" an NFA, since all that's changed is having a stack. Of course, the stack is what gives our otherwise-NFA the ability to process nestedness, since stacks are first-in first-out structures.
Many of the fundamental properties of pushdown automata can be attributed to Schützenberger (1963) and Chomsky himself, though many of these discoveries were independently published by others (Oettinger 1961, Evey 1963).
Marcel-Paul Schützenberger was a French mathematician who was one of Chomsky's early collaborators and together they proved many important results about context-free languages. Besides his work with Chomsky, Schützenberger produced many influential results in formal languages and combinatorics on words.
Around this time, research into formal languages and automata theory was picking up and there were all sorts of investigations into modifications and restrictions on grammars and automata. The pushdown automaton is one result of these kinds of questions being pursued.
As an aside, one can think about what other sorts of crazy contraptions you can stick onto a finite automaton. Of course, this really amounts to the question of changing how we're allowed to access unlimited amounts of memory. Since our stack has infinite memory, it's clear that what's limiting its power is how we're allowed to access this memory. What happens if we add more restrictions? What happens if we loosen some restrictions?
A pushdown automaton (PDA) is a 7-tuple $M = (Q,\Sigma,\Gamma,\delta,q_0,Z_0,F)$, where
There are a few features of the transition function that should be mentioned. First, the transition function is nondeterministic—notice that the codomain of the function is to sets of $Q \times \Gamma^*$. Secondly, on a transition, the machine takes the top symbol off of the stack but can put many symbols onto the stack, as long as it is a finite amount. We specify explicitly that the transition function must be finite, since a subset of $Q \times \Gamma^*$ can be possibly infinite without qualification.
Because of the added complexity of representing the stack, some like to treat $\delta$ as a relation instead, which is what Kozen does. In this view, $\delta \subseteq (Q \times (\Sigma \cup \{\varepsilon\}) \times \Gamma) \times (Q \times \Gamma^*)$ is a relation on $Q \times (\Sigma \cup \{\varepsilon\}) \times \Gamma$ and $Q \times \Gamma^*$. So a transition $$((q,a,X),(q',Y_1 Y_2 \cdots Y_k)) \in \delta$$ is equivalent to saying that $(q',Y_1 Y_2 \cdots Y_k) \in \delta(q,a,X)$, where $q,q' \in Q$, $a \in \Sigma \cup \{\varepsilon\}$, and $X, Y_1, \dots, Y_k \in \Gamma$. But, functions are really just special kinds of relations, so in the end, this is just a difference in notational preference (personally speaking, Kozen is the first textbook I've seen that does this).
As with finite automata, we can enumerate the parts of the PDA.
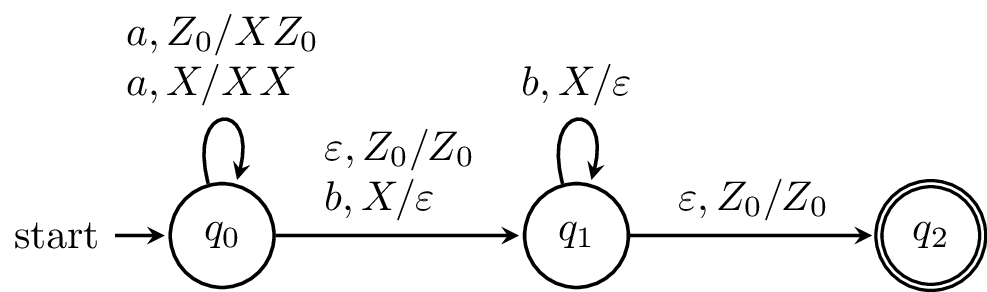
\begin{tikzpicture}[shorten >=1pt,on grid,node distance=3cm,>=stealth,thick,auto]
\node[state,initial] (0) {$q_0$};
\node[state] (1) [right of=0]{$q_1$};
\node[state,accepting] (2) [right of=1] {$q_2$};
\path[->]
(0) edge [loop above] node [align=left] {$a,Z_0/XZ_0$ \\ $a,X/XX$} (0)
(0) edge node [align=left] {$\varepsilon,Z_0/Z_0$ \\ $b,X/\varepsilon$} (1)
(1) edge [loop above] node {$b,X/\varepsilon$} (1)
(1) edge node [align=left] {$\varepsilon,Z_0/Z_0$} (2)
;
\end{tikzpicture}
We write transitions in the following way: $$\delta(q,a,X) = \{(q_1,\alpha_1), \dots, (q_n,\alpha_n)\}$$ where $q,q_1,\dots,q_n \in Q$, $a \in \Sigma$, $X \in \Gamma$, and $\alpha_1,\dots,\alpha_n \in \Gamma^*$.
Since $\alpha_i$ is a string, it's important to note the order in which we push symbols onto the stack. If $\alpha_i = X_1 X_2 \cdots X_k$ where $X_j \in \Gamma$, $X_k$ gets pushed onto the stack first and after all of $\alpha_i$ is pushed onto the stack, $X_1$ is on the top of the stack. In other words, the top of the stack should look like we just took $\alpha_i$ and turned it 90 degrees so that $X_k$ is at the bottom and $X_1$ is at the top.
As an example, we write one of the transitions from the above machine as $$\delta(q_0,a,Z_0) = \{(q_0,XZ_0)\}.$$
Of course, as with NFAs, listing the entire transition function explicitly can be quite cumbersome. Also, note that just like for NFAs, we can draw a state diagram for a PDA. The idea is mostly the same, but the difference is how to denote the changes to the stack. For a transition $(q',\alpha) \in \delta(q,a,X)$ we label the transition from $q$ to $q'$ by $a,X/\alpha$.
from automata.pda.npda import NPDA
A = NPDA(
states={f'q{i}' for i in range(3)},
input_symbols=set('ab'),
stack_symbols=set('XZ'),
transitions={
'q0': {
'': {'Z': {('q1', 'Z')}},
'a': {
'Z': {('q0', 'XZ')},
'X': {('q0', 'XX')}
},
'b': {'X': {('q1', '')}}
},
'q1': {
'b': {'X': {('q1', '')}},
'': {'Z': {('q2', 'Z')}}
}
},
initial_state='q0',
initial_stack_symbol='Z',
final_states={'q2'}
)
As with the NFA, if a transition is undefined, we assume that it goes to the empty set (since the image of the transition function is subsets of $Q \times \Gamma^*$). In practice, we treat this as the machine crashing. For a PDA, in addition to not having transitions defined on a state and symbol, we also take into consideration the symbol that we pop from the stack. One particular case of this is when we try to pop an element off of an empty stack (this is undefined, so we go to the empty set).