Notice that the application of productions in a grammar is nondeterministic. In this case, we have two ways in which we have a choice to make. First, we can replace any variable that is present in a sentential form, so we have a choice of which variable to choose to expand. Secondly, for each variable, we have a choice of which production to apply to the variable. This means that a string can be generated by a grammar in multiple ways—that is, strings may have multiple derivations.
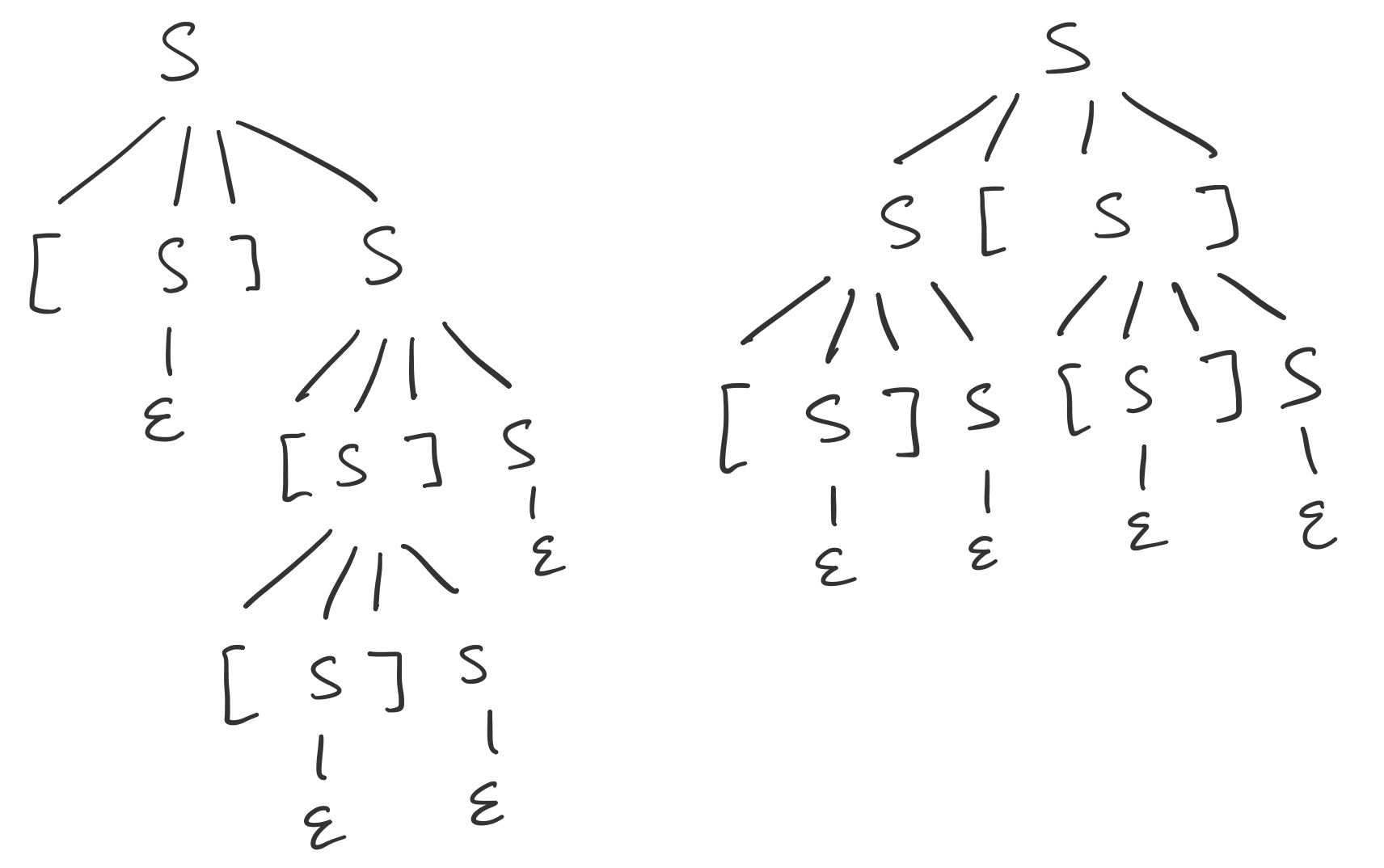
Consider the following grammar $G$ that generates strings of balanced parentheses \[S \to \mathtt [ S \mathtt ] S \mid S \mathtt [ S \mathtt ] \mid \varepsilon,\] The string $\mathtt{[][[]]}$ has the following derivations in $G$.
An interesting observation from this is that the first two derivations actually result in the same parse tree, on the left, while the different leftmost derivation admits a different parse tree.
What this suggests is that derivations for a particular string are not unique, nor are the length of their derivations, even if we restrict ourselves to leftmost derivations. Furthermore, they do not admit the same parse trees. But one can conclude that a parse tree corresponds to a particular leftmost derivation.
These definitions allow us to give the following definition for what it means to be "generated" by a grammar.
Let $G = (V,\Sigma,P,S)$ be a context-free grammar. The language generated by $G$ is $$L(G) = \{w \in \Sigma^* \mid S \Rightarrow_G^* w\}.$$ A language $L$ is a context-free language if there exists a context-free grammar $G$ such that $L(G) = L$.
Let's return to our example from above with the following proposition and show that the language $\{a^k b^k \mid k \geq 0\}$ is context-free.
Let $G$ be the context-free grammar \[S \to aSb \mid \varepsilon.\] Then $L(G) = \{a^k b^k \mid k \geq 0\}$.
Let $L = \{a^k b^k \mid k \geq 0\}$. First, we will show that $L \subseteq L(G)$. Let $w \in L$. We will show that $w$ can be generated by $G$ by induction on $|w|$.
The base case is $|w| = 0$, so $w = \varepsilon$. Then since $S \to \varepsilon$ is a production in $G$, we have $S \Rightarrow w$ and therefore $w \in L(G)$.
Now consider $|w| \geq 1$ and thus $w \neq \varepsilon$. For our inductive hypothesis, we assume that for any $x \in L$ with $|x| < |w|$, we have $x \in L(G)$. That is, $S \Rightarrow^* x$.
Since $w \in L$ and $|w| > 0$, we have $w = a^n b^n$ for some $n \geq 1$. We can write $w = a (a^{n-1} b^{n-1}) b$. Let $x = a^{n-1} b^{n-1}$ and we note that $x \in L$. Since $|x| < |w|$, we have $x \in L(G)$ by our induction hypothesis and thus there is a derivation $S \Rightarrow^* x$. Then we can use this to construct a derivation for $w$ by $$S \Rightarrow aSb \Rightarrow^* axb = a(a^{n-1} b^{n-1})b = a^n b^n = w.$$ Thus, we have $w \in L(G)$ and $L \subseteq L(G)$ as desired.
Now, we will show that $L(G) \subseteq L$. Let $w \in L(G)$. Then there exists a derivation $S \Rightarrow^* w$. We will show $w \in L$ by induction on $k$, the number of steps in the derivation of $w$.
For our base case, we have $k = 1$. The only derivation of length one is by applying the rule $S \to \varepsilon$, so $w = \varepsilon$. Since $\varepsilon = a^0 b^0 \in L$, the base case holds.
Now consider $k \geq 2$ and assume that every word $x \in L(G)$ with fewer than $k$ steps in its derivation is in $L$. Since $k \geq 2$, the first step in the derivation of $w$ must be $S \Rightarrow aSb$. So our derivation of $w$ is $S \Rightarrow aSb \Rightarrow^* axb = w$, where $x$ is a string generated by $S$. In other words, $S \Rightarrow^* x$.
Since $S \Rightarrow^* w$ is a derivation of length $k$, we have that $S \Rightarrow^* x$ is of length $k-1$. Therefore, $x \in L$ by our inductive hypothesis. So $x = a^j b^j$ for some $j \in \mathbb N$. Then we have \[S \Rightarrow aSb \Rightarrow axb = a(a^j b^j)b = a^{j+1} b^{j+1} = w.\] Since $j+1 \in \mathbb N$, we have that $w \in L$.
Thus, $L = L(G)$.
One challenging aspect of reasoning about grammars is that the only constraint on production rules $A \to \alpha$ is only that a single variable can be on the left hand side, while $\alpha$ can be any finite string over $V \cup \Sigma$. Compounding the issue is that productions can be applied nondeterministically. Thinking back to finite automata or derivatives, we were able clearly say something about the result of reading a particular word. Here, there seems to be many different ways of getting to the same word.
When we run into situations like these, we typically want to find some sort of standard form which has some structure that we can rely on. For CFGs, this idea is captured in the Chomsky normal form. Unsurprisingly, this normal form and many of its properties are due to Chomsky (1959). That this one is named after Chomsky also implies that there are other normal forms (namely Greibach).
A context-free grammar $G$ is in Chomsky normal form if every production of $G$ has one of the following forms:
Ironically, Chomsky normal form has a number of variants. The one here allows for $\varepsilon$ to be generated by the grammar. Kozen's presentation disallows $\varepsilon$ from being in the language. This is not a huge issue, but it does mean that the rules can be slightly different across presentations.
One very useful property of CNF grammars is that every derivation of a non-empty string $w$ via a grammar in CNF has exactly $2|w| - 1$ steps.
Let $G$ be a context-free grammar in Chomsky normal form. Then for any non-empty word $w \in L(G)$, a derivation of $w$ in $G$ has $2|w| - 1$ steps.
We will show something more general: that for any variable $A$ in $G$, a derivation $A \Rightarrow^* w$ has $2|w| - 1$ steps. We will show this by induction on $|w|$.
For the base case, we have $|w| = 1$. Then the only step in the derivation is $A \Rightarrow w$, for some production $A \to w$. Otherwise, we must apply a production rule of the form $A \to BC$, but this leads to a word of length at least two since there are no rules of the form $B \to \varepsilon$. Thus, we have a derivation of length 1 and $1 = 2 \cdot 1 - 1 = 2|w| - 1$ so the base case holds.
Now consider $|w| > 1$. Our induction hypothesis is that for all words $x$ with derivation $A \Rightarrow^* x$ and $|x| < |w|$, the derivation of $x$ has length $2|x| - 1$. Since $|w| > 1$, the first step of the derivation must be via a production $A \to BC$. So we must have a derivation \[A \Rightarrow BC \Rightarrow^* uC \Rightarrow^* uv = w,\] for some nonempty strings $u$ and $v$ where $B \Rightarrow^* u$ and $C \Rightarrow^* v$. As there are no $\varepsilon$-rules, both $u$ and $v$ are shorter than $w$ and by the induction hypothesis, they have derivations of length $2|u| - 1$ and $2|v| - 1$. Then a derivation of $w$ has length \[2|u| - 1 + 2|v| - 1 + 1 = 2(|u|+|v|) - 1 = 2|w| - 1.\]