The second important consequence of the theorem comes from the proof of the Myhill-Nerode theorem, when it defines a DFA $A_{\equiv_L}$ for a regular language $L$. If we recall that the Myhill-Nerode equivalence classes are about distinguishable prefixes with respect to $L$, this suggests that a DFA recognizing $L$ will need at least as many states as $L$ has Myhill-Nerode equivalence classes. But these equivalence classes correspond to the states of $A_{\equiv_L}$, which means that any DFA that recognizes $L$ must have at least as many states as $A_{\equiv_L}$.
For example, recall that we showed that we can use the product construction to obtain a DFA that recognizes the intersection of two regular languages. If the two languages have DFAs of size $m$ and $n$, then the product construction gives a DFA with up to $mn$ states. But do we really need that many? We can show that there exist languages for which we do need all of those states.
For all $m,n \geq 1$, there exist regular languages $L_m$ and $L_n$ recognized by a DFA with $m$ and $n$ states, respectively, such that a DFA that recognizes $L_m \cap L_n$ must have at least $mn$ states.
Let $\Sigma = \{0,1\}$ and consider the languages \begin{align*} L_m &= \{w \in \Sigma^* \mid |w|_0 = 0 \pmod m\}, \\ L_n &= \{w \in \Sigma^* \mid |w|_1 = 0 \pmod n\}. \end{align*} Then $L_m$ can be recognized by a DFA with $m$ states and $L_n$ can be recognized by a DFA with $n$ states (you can try to find the DFAs yourselves as an easy exercise). Then $$L_m \cap L_n = \{w \in \Sigma^* \mid |w|_0 = 0 \pmod m \wedge |w|_1 = 0 \pmod n\}.$$ So we need to consider the equivalence classes of $\equiv_{L_m \cap L_n}$.
We will consider strings $0^i 1^j$ with $0 \leq i \lt m$ and $0 \leq j \lt n$ to be our representatives for the equivalence classes. To show that these are all distinct, we consider two words $x = 0^i 1^j$ and $y = 0^k 1^\ell$ with $0 \leq i, k \lt m$, $0 \leq j, \ell \lt n$, and $x \neq y$. This means that $i \neq k$ or $j \neq \ell$ (or both). We suppose $i \neq k$; the $j \neq \ell$ case follows a similar argument.
We choose the word $z = 0^{m-i} 1^{n-\ell}$. Then $xz \in L_m \cap L_n$ but $yz \not \in L_m \cap L_n$. To see this, the number of $0$s in $xz$ is $i + m - i = 0 \pmod m$ and the number of $1$s in $xz$ is $j + n - j = 0 \pmod n$. But the number of $0$s in $yz$ is $k + m - i \neq 0 \pmod m$ if $k \neq i$. So $z$ distinguishes $x$ and $y$.
This means that there are at least $mn$ pairwise distinguishable Myhill-Nerode equivalence classes ($i$ can range from 0 to $m-1$ and $j$ can range from 0 to $n-1$).
Since we know that the product construction has at most $mn$ states, together with this result, we've also just shown that there's a DFA for $L_m \cap L_n$ that has exactly $mn$ states.
This leads to the notion of a minimal DFA, in terms of the number of states it has, for a language. So it's clear from this that any minimal DFA will have as many states as there are Myhill-Nerode equivalence classes for its language, but we can actually say something stronger than that: the Myhill-Nerode DFA is the only minimal DFA for its language.
Let $L$ be a regular language. The DFA $A_{\equiv_L}$ is the unique minimal DFA for $L$ up to isomorphism.
Let $A = (Q,\Sigma,\delta,q_0,F)$ be a minimal DFA for $L$. Recall that the equivalence classes of the relation $\sim_A$ correspond to states of $A$. By Lemma 12.1, $\sim_A$ refines $\equiv_L$ and therefore, the index of $\sim_A$ must be at least the index of $\equiv_L$. Since we assumed $A$ was minimal, this means that $A$ has exactly as many states as $A_{\equiv_L}$.
Now, we need to show that there is a correspondence between states of $A$ and states of $A_{\equiv_L}$. Let $q \in Q$. Then $q$ must be reachable from the initial state $q_0$, since otherwise, we can remove it. This means there exists a word $w \in \Sigma^*$ such that $\delta(q_0,w) = q$. Then $q$ corresponds to the equivalence class for $[w]$.
Assuming it's computable, the existence of a minimal DFA and the fact that a regular language has a unique minimal DFA gives us a way to test whether two DFAs or NFAs or regular expressions correspond to the same language: just turn the two objects into a minimal DFA and if they're the same, then they accept the same language.
Luckily, the minimal DFA can be computed, and even better is that it is efficiently computable. The algorithm with the best worst-case time complexity is Hopcroft's partition refinement algorithm (due to Hopcroft in 1971) which has $O(n \log n)$ time complexity.
Instead, we will consider the more straightforward algorithm that Kozen gives an algorithm in Section 14 of the textbook which runs in roughly $O(|\Sigma|n^3)$ time for a DFA with $n$ states. The basic idea behind this is to try to identify states in the DFA that are indistinguishable.
Consider a DFA $A = (Q,\Sigma,\delta,q_0,F)$ and two states $p,q \in Q$. We say that $p$ and $q$ are indistinguishable if for all $w \in \Sigma^*$, $\delta(p,w) \in F \iff \delta(q,w) \in F$.
In this case, $p$ and $q$ must correspond to the same Myhill-Nerode equivalence class and we can replace both states with a single state. Now, as stated, this seems difficult to do (verify for all strings in $\Sigma^*$), so we can reframe this property in terms of distinguishability.
Let $A = (Q, \Sigma, \delta, q_0, F)$ be a DFA. Two states $p,q \in Q$ are said to be distinguishable if
Notice that we get this just by negating the definition of indistinguishability. Distinguishability is also much easier to check and leads to our relatively simple algorithm from the textbook, which was first formulated by Moore in 1956.
Given a DFA $A = (Q, \Sigma, \delta, q_0, F)$,
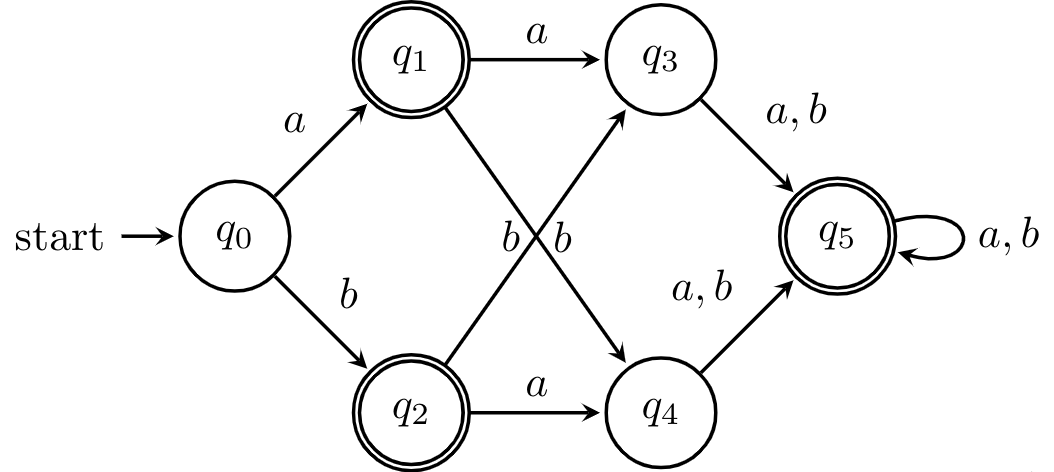
Here is an example. We have the following DFA.
First, we set up our table and consider the first iteration of our algorithms. Note that since pairs are unordered, we only fill half the table, so to distinguish unmarked cells from empty cells, we use -. Marked pairs of states are marked by which round of iteration they were marked in, for demonstrative purposes.
| $q_1$ | $q_2$ | $q_3$ | $q_4$ | $q_5$ | |
|---|---|---|---|---|---|
| $q_0$ | 1 | 1 | - | - | 1 |
| $q_1$ | - | 1 | 1 | - | |
| $q_2$ | 1 | 1 | - | ||
| $q_3$ | - | 1 | |||
| $q_4$ | 1 |
Next, we consider each pair of unmarked states and determine whether each pair reaches a marked pair. We have that $(q_1,q_5)$ and $(q_2,q_5)$ get marked in this phase, because $(\delta(q_1,a), \delta(q_5,a)) = (q_3,q_5)$ and $(\delta(q_2,a), \delta(q_5,a)) = (q_4,q_5)$, which have been marked distinguishable.
The reasoning here is simple: suppose that a pair wasn't distinguishable. Then, because the reaching a state relation $\sim_A$ is right-invariant, reading any word from the two states should get us to indistinguishable states. But clearly, this isn't the case, since reading $a$ brings us to a pair of distinguishable states. It's not too hard to see that we can extend this argument inductively.
| $q_1$ | $q_2$ | $q_3$ | $q_4$ | $q_5$ | |
|---|---|---|---|---|---|
| $q_0$ | 1 | 1 | - | - | 1 |
| $q_1$ | - | 1 | 1 | 2 | |
| $q_2$ | 1 | 1 | 2 | ||
| $q_3$ | - | 1 | |||
| $q_4$ | 1 |
We do another round of this, taking into account the new pairs of distinguishable states.
| $q_1$ | $q_2$ | $q_3$ | $q_4$ | $q_5$ | |
|---|---|---|---|---|---|
| $q_0$ | 1 | 1 | 3 | 3 | 1 |
| $q_1$ | - | 1 | 1 | 2 | |
| $q_2$ | 1 | 1 | 2 | ||
| $q_3$ | - | 1 | |||
| $q_4$ | 1 |
At this point, we're finished because and we have two pairs of states that are indistinguishable. We can merge these states safely to get the following DFA.
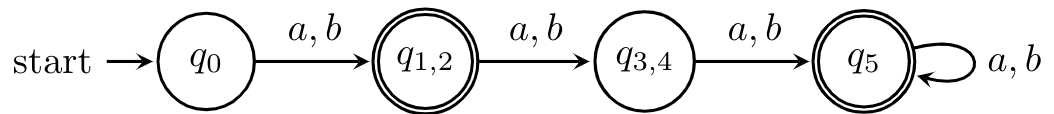
This algorithm is something like $O(|\Sigma| n^3)$ worst-case time complexity, where $n$ is the number of states in your DFA. If you are slightly more clever, we can get this down to $O(|\Sigma| n^2)$, by maintaining a list of pairs $\{p',q'\}$ for each pair $\{p,q\}$, with $p' = \delta(p,a)$ and $q' = \delta(q',a)$ for some $a \in \Sigma$. Then, once the lists are built, we can mark pairs by going through the list in one go.
By virtue of being a polynomial-time algorithm, we've shown that we can consider DFA minimization to be "efficient". So we can take for granted that we can efficiently determine whether two DFAs recognize the same language. For NFAs and regular expressions, things are a bit harder because the determinization process can lead to exponential state blowups.
Speaking of exponential state blow up, an algorithm that takes a very different approach from the Moore algorithm is due to Brzozowski. It is surprisingly simple to describe.
The DFA $\mathcal D((\mathcal D(A^R))^R)$ is a minimal DFA equivalent to $A$.
This gives us the algorithm: take your DFA $A$, compute the NFA for its reversal, compute the DFA for the reversal via the subset construction, reverse that, and finally do the subset construction on the result of that. Why does it work? It turns out one can show that applying the subset construction to an NFA that reverses a DFA will give you exactly the minimal DFA for the reversal of original DFA! So all you have to do is do it twice to get back where you started.
Let $A = (Q,\Sigma,\delta,q_0,F)$ be a DFA accepting $L$ and suppose that every state of $A$ is reachable. Then $\mathcal D(A^R)$ is a minimal DFA for $L^R$.
To show that the DFA $\mathcal D(A^R)$ is minimal, we show that no two states are equivalent. Let $\mathcal D(A^R) = (Q',\Sigma,\delta',q_0',F')$ and consider two states $X,Y \in Q'$. Remember that states of $Q'$ are subsets of states of $Q$, the state set of $A$.
Suppose $X$ and $Y$ are equivalent. First, we'll show that $X \subseteq Y$. Let $q \in X$. Since every state of $A$ is reachable, we know that there exists a word $w \in \Sigma^*$ such that $\delta(q_0,w) = q$. Then $q_0 \in \delta^R(q,w^R)$ in $A^R$ and so $\delta'(X,w^R) \in F'$ in $\mathcal D(A^R)$.
Since $X$ and $Y$ are equivalent, we have that $\delta'(Y,w^R) \in F'$ in $\mathcal D(A^R)$. Then there exists a $p \in Y$ such that $q_0 \in \delta^R(p,w^R)$ in $A^R$, which means that $\delta(q_0,w) = p$ in $A$. But $A$ is a DFA, so we must have $p = q$ and therefore $q \in Y$.
A symmetric argument will show that $Y \subseteq X$ and therefore, $X = Y$.
Because Brzozowski's algorithm is worst-case exponential, its complexity has been studied over the last few decades, both experimentally and through average-case analysis. Part of the challenge of doing such analysis is that it's difficult to generate random DFAs and NFAs with a reasonable distribution and that behave in a reasonable way. For instance, just randomly generating DFAs with $n$ states by randomly generating transitions between them will result in a lot of disconnected DFAs.