Trees are a fundamental structure in discrete mathematics and computer science. In general, trees are used to model hierarchical relationships and structures. For example, a document tree gives the outline of a document (sections, subsections, etc.). A phylogentic tree gives a representation of how species evolve and change. A parse tree encodes the grammatical structure of an expression.
We are particularly interested in binary trees. Binary trees are used in computer science as the backbone of many data structures, like binary search trees or binary heaps.
We can define a binary tree as follows. A binary tree is
These are called binary trees because each node contains only at most two trees. In general, non-binary trees, nodes can have any number of subtrees associated with them, also called the children of the node.
So how do we implement one of these in Racket? Our type definition will have to look very similar to our mathematical definition of a tree.
(define-type IntTree (U 'Empty IntNode))
(define-struct IntNode
([value : Integer]
[left-sub : IntTree]
[right-sub : IntTree]))Here, we have our integer binary trees, or IntTree.
Note that we will restrict ourselves to binary trees that hold integer values only, hence the int in the name. However, it's not hard to see how we might change the definition of the type if we wanted to make a tree that holds, say strings or reals, or really, values of any fixed type.
Our IntTree is a union type consisting of two types: either an empty tree, denoted 'Empty or a structure, IntNode.
We then need to provide a definition for IntNode. An IntNode contains a value, which we have said is of type Integer, and two subtrees. Note that the subtrees are of type IntTree. This means that they can either be empty or a whole other tree.
Now, it's not as clear how to format or define trees for use like this. Up until now, we've really been working with data that's easily representable linarly, like strings or numbers.
First, of course, we can define an empty tree.
(: a-tree IntTree)
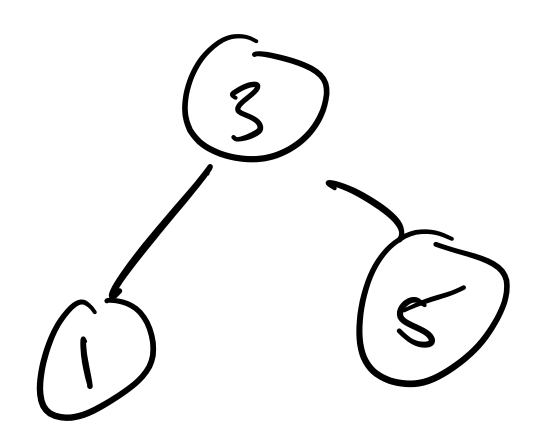
(define a-tree 'Empty)This seems obvious, but we will need to do this a bit later. But it turns out defining a nonempty is not too different from how we already format our code for readability. Suppose we want to define the following tree.
Here is a first attempt.
(: b-tree IntTree)
(define b-tree
(IntNode 3
(IntNode 1)
(IntNode 5)))This looks like correct, but we're forgetting something important: an IntNode has to have a value and both subtrees defined. We need to throw in those subtrees for the nodes containing 1 and 5, even if they're empty.
(: b-tree IntTree)
(define b-tree
(IntNode 3
(IntNode 1 'Empty 'Empty)
(IntNode 5 'Empty 'Empty)))Here's another example.
(: another-tree IntTree)
(define another-tree
(IntNode 7
(IntNode 6 'Empty 'Empty)
(IntNode 5
(IntNode 24
'Empty
(IntNode 34
'Empty
'Empty))
'Empty)))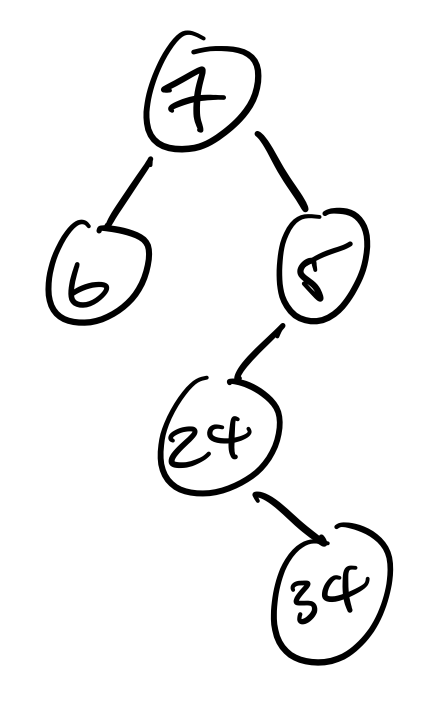
The recursive structure of binary trees gives a natural way to process them. First, let's consider the problem of counting how many nodes are in our tree. We can think of this as the size of the tree.
So as with all recursive algorithms, we want to think back to the definition of our structure. Well, what is a tree? It's either empty or a node. So we have two cases. First, if the tree is empty, then it has 0 nodes. But if the tree is a node, then we know it contains at least 1 node. But it could have more. How many more? Well, as many as are in its subtrees. But how do we know the size of the subtrees? Well, we can just run our size function on them, since they're trees!
This gives us the following definition. The size of a tree $T$ is the number of nodes in $T$, denoted $\operatorname{size}(T)$, and is defined as follows:
We can then turn this very naturally into a function in Racket.
(: tree-size (-> IntTree Integer))
;; Counts the number of nodes in the given binary tree
(define (tree-size t)
(match t
['Empty 0]
[(IntNode _ left right) (+ 1 (tree-size left) (tree-size right))]))Suppose now that we wanted to determine whether a value, say $k$, is stored in our tree. Again, we consider how to solve this recursively. There are two possibilities for our tree: it's empty or it's not. If our tree is empty, then it obviously does not contain $k$.
But what if our tree is a node? One thing we can do is check whether the value in our node is $k$. If it is, then we can report that our tree does contain $k$. But what if it isn't? Well, it might be in one of the two subtrees. So if it is in either one of our subtrees, we can report this fact. Otherwise, we know the tree doesn't contain $k$.
Let's call this $\operatorname{contains}(T,k)$ and let's call the value stored in the node at $T$ (if it's a node) $\operatorname{value}(T)$. This is going to be a boolean: it's either true or false that $T$ contains $k$. We then have two possibilities.
This gives us the following code.
(: tree-search (-> IntTree Integer Boolean))
;; Returns true if the given integer is in the tree
(define (tree-search t k)
(match t
['Empty #f]
[(IntNode val left right) (or (= k val)
(tree-search left k)
(tree-search right k))]))This looks very similar to the definition we worked out and the other definitions we saw before. Again, it's helpful to keep the idea of using the recursive definition of the structure you're working on in mind when coming up with recursive programs.