Just as with lists and trees, one thing we would like to do is visit every node or vertex. With lists, we only have one way to do this: down or forward, depending on how you view lists. With trees, we saw that there are multiple ways to do this. Even with only two children, we could consider preorder, in-order, and postorder traversals. In more general trees, we have more "ways" we could traverse a tree, but generally, the formula is quite simple: visit all the children.
Much like trees, a vertex in a graph may have arbitrarily many neighbours. But unlike trees, we can't just visit every neighbour of every vertex. Consider the following:
The trap here is that if we perform the same actions on a vertex we've already visited, we would never stop. Therefore, we now have the additional task of keeping track of which vertices we've already visited—something that was impossible to do with a tree.
For now, we can keep track of this by marking or "colouring" each vertex as we visit it. This will allow us to determine whether or not a vertex has been visited or not and avoid those that we've already seen.
Then with the "remembering" taken care of, there are two basic strategies to "explore" our graph. In both, we first choose an arbitrary vertex to begin at.
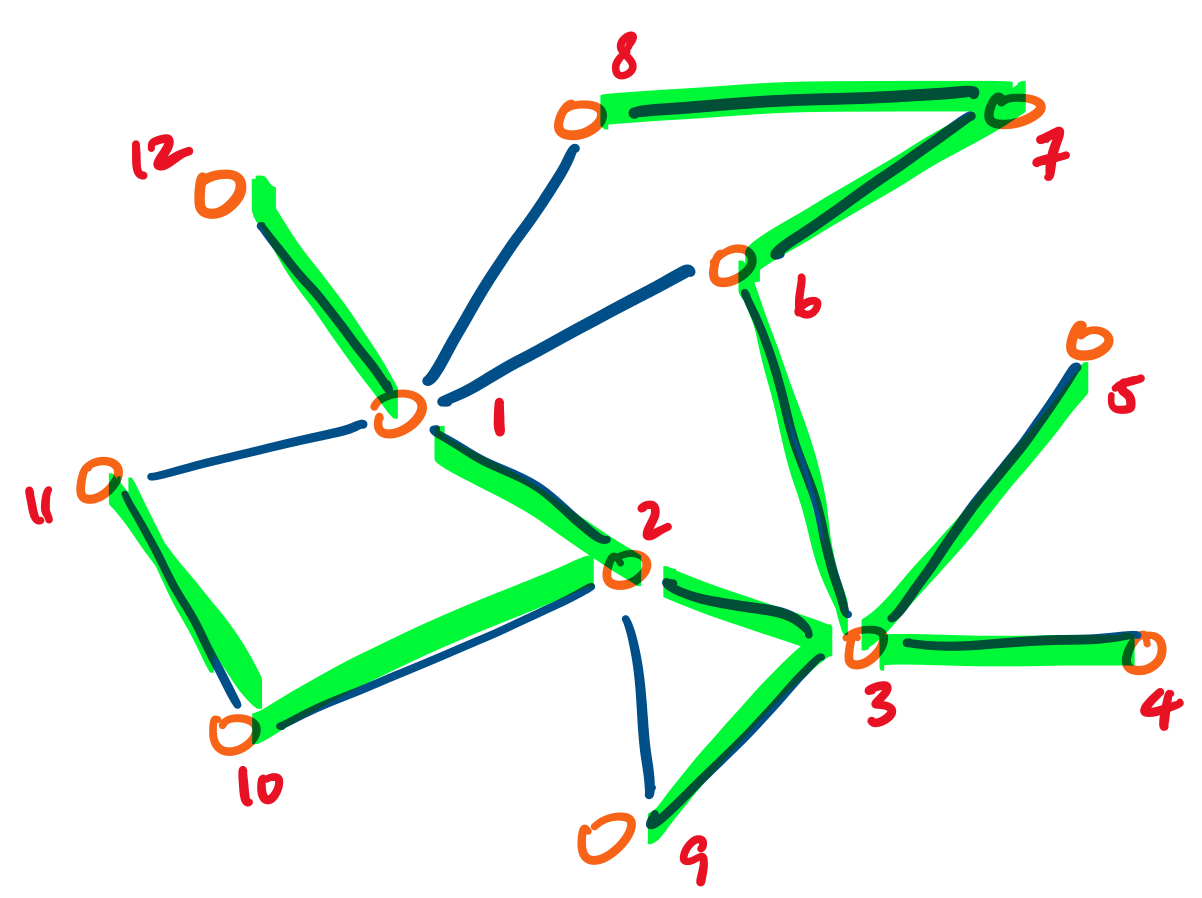
The first approach is to build a path from our starting vertex, as long as we can. Once we are unable to do so, we backtrack up the path we've just built to try to extend it to any vertices we haven't visited yet. This is called a depth-first traversal. For example, the following undirected graph is labeled with one possible depth-first traversal, with the edges taken highlighted in green:
Observe that the resulting traversal depends on two things: where we start, and in which order we choose to visit a neighbour. Where we start is particularly important in directed graphs, since it's possible that some vertices may be unreachable. The order for visiting neighbours is not so important, since we will eventually visit them all.
The second approach is to build paths by sweeping out from our source vertex, adding edges to all of its neighbours. Then for each of its neighbours, we repeat the process, as long as the vertices have not already been visited from a prior node. This is called a breadth-first traversal. For example, we have the same undirected graph as above, but this time, it is labeled with one possible breadth-first traversal, with the edges taken highlighted in yellow:
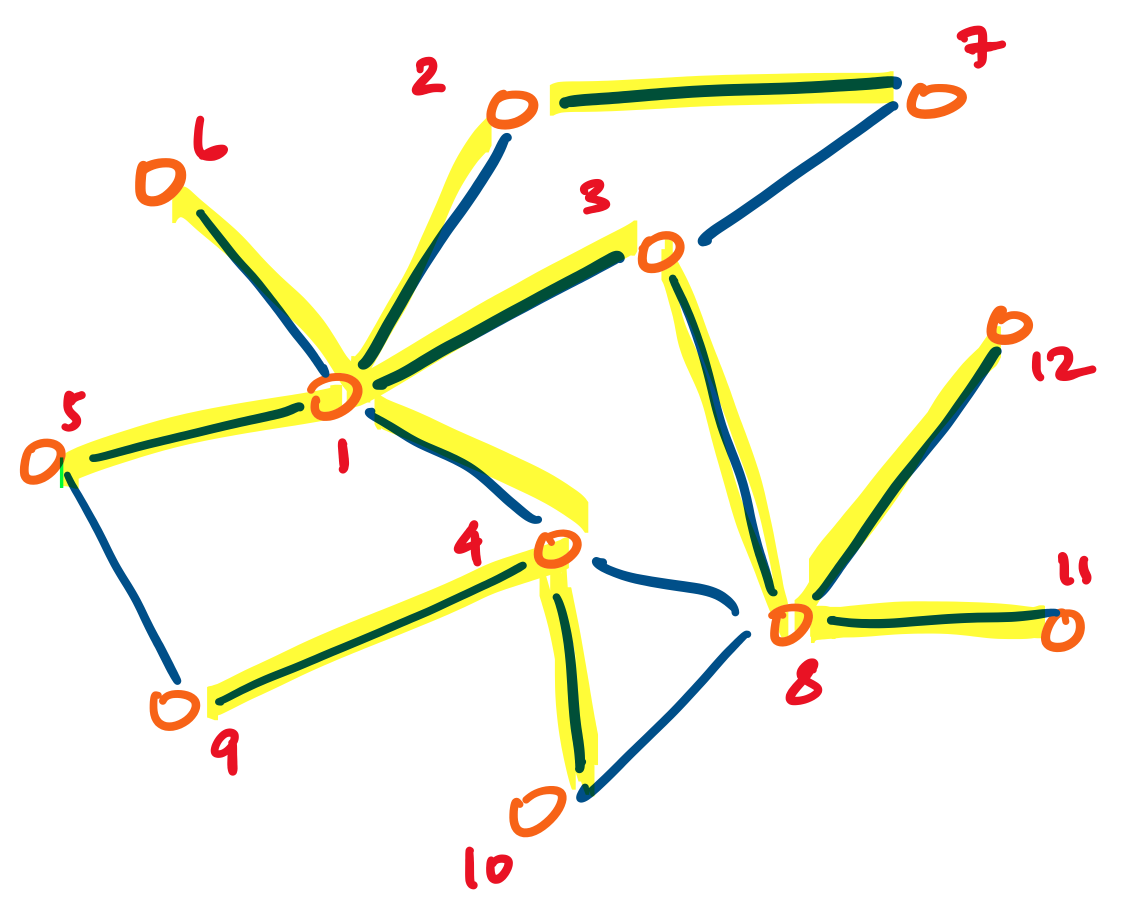
The same caveats of where we start and in which order we visit neighbours applies.
The main problem we are faced with is how to decide the order in which we visit vertices and remembering whether they've already been visited or not.
Just as we enforced conditions on binary trees to make them more efficient structures for retrieving data, we can place conditions on linear data structures (really, lists) for various applications. We will introduce two such data structures (really, abstract data types).
The first data structure we'll be considering is the stack. A stack has two operations:
As the name suggests, we can imagine the stack working like a physical stack: we put things on top of the stack and we remove things on top of the stack.
It's clear that a stack is a linear data structure, so the natural underlying structure should be a list. Therefore, we have the following type:
(define-type (Stack A) (Listof A))
Pushing an element onto the stack is quite natural: simply add it to the "top" (in this case the front) of the list:
(: push (All (A) (-> A (Stack A) (Stack A))))
;; Push an item onto the given stack and produce the resulting stack
(define (push x st)
(cons x st))
Popping an element from the stack sounds just as straightforward: simply take the element at the top off the stack off. However, there are some complications to consider. First, what happens if the stack is empty? In this case, we shouldn't get anything. This suggests that we may want to make the output type an Optional type. Secondly, what exactly do we "get"? Do we get the item we just took off, or the resulting stack? The answer is that we really need both, so we will "get" both, by using a pair.
(: pop (All (A) (-> (Stack A) (Optional (Pairof A (Stack A))))))
;; Pop the top item off of the given stack and produce the item and
;; resulting stack, if the stack is non-empty, and nothing otherwise.
(define (pop st)
(match st
['() 'None]
[(cons head tail) (Some (Pairof head tail))]))
The other data structure we'll be considering is the queue. A queue has two operations:
Again, the name suggests something about the operation of the structure: when we line up (or as the British might say, join a queue), the person who was there first gets served first.
Just as with stacks, queues are clearly linear, and so are really just lists with an additional constraint.
(define-type (Queue A) (Listof A))
We will take the "front" of the queue to be the head of the list. This is arbitrary—you can just as well choose to make the head the "end" of the queue. However, whichever way you choose, it will become necessary to get to the "end" of a list. In our case, this will be necessary with enqueue.
(: enqueue (All (A) (-> A (Queue A) (Queue A))))
;; Add an item into the given queue and produce the resulting queue
(define (enqueue x qu)
(append qu (list x)))
With our implementation of enqueue, we simply use append. The tradeoff is that dequeue is simpler, with the caveat that we have the same considerations to make as with pop.
(: dequeue (All (A) (-> (Queue A) (Optional (Pairof A (Queue A))))))
;; Remove an item from the given queue and produce the item and
;; resulting queue, if the queue is non-empty, and nothing otherwise.
(define (dequeue qu)
(match qu
['() 'None]
[(cons head tail) (Some (Pairof head tail))]))