Suppose we have a list of things and we want to find a particular item from the list. What can we do? The answer is there is actually very little we can do except to go through the entire list to look for it. This is kind of a problem, because this means we basically have to go through every item. This is not very good if we are dealing with a sufficiently large list.
So what are some strategies that we can use to make this easier to do? If we examine other examples of information that are intended to be searched, like indices, you'll notice that they are organized in a specific way. For example, you might arrange your list of items in some sort of sorted order, which is very convenient having just discussed this.
If you think about the index of a book, the list of topics are sorted alphabetically. We can then drill down relatively quickly from there: we look up the first letter of our topic, then either start scanning the list of topics, or we dig a bit further and check the second letter if it's particularly long. We might want to employ the same kind of strategy: arrange the data in some way and then make use of that ordering to eliminate large sections of the data from consideration.
Of course, with the alphabet, we have something like 26+ sections (the letters of the alphabet and possibly symbols). However, one might realize that the topics of a book are likely not going to be uniformly distributed among these categories. And what if we wanted to avoid doing the work of categorizing anything at all?
In this case, simply having the information in some sort of order is helpful. Note this requirement, though: the data has to be able to be put in order. We'll talk a bit more about that in a second. But suppose that we have our information in a nice ordering. How do we do the same thing with the letters and systematically narrow our search space?
Without knowing anything else, you can check the middle. If your item isn't in the middle then there are two possibilities: either it's in the first half or it's in the latter half. We can then repeat this process, narrowing down the space that we have to look through by half until we find our item (or don't).
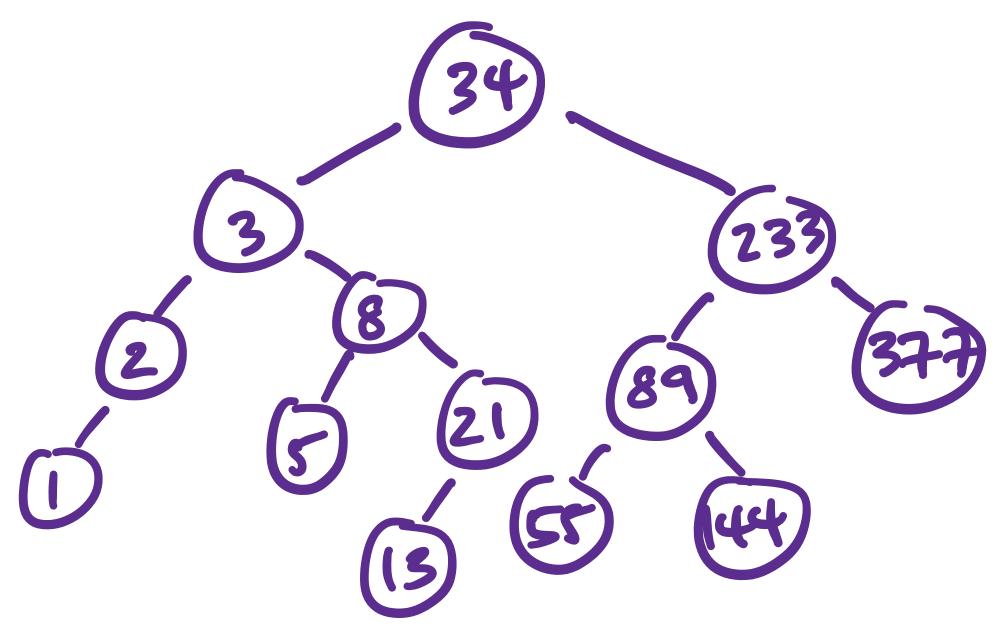
Consider the following set. Suppose we want to know whether or not the number 315 is in the list. Searching sequentially, we would have to travel almost to the end before determining it was not in the list. However, by using the idea of binary search, we can speed up our search. \[\begin{matrix} 1 & 2 & 3 & 5 & 8 & 13 & 21 & 34 & 55 & 89 & 144 & 233 & 377 \end{matrix}\]
First, we examine the centre element, 21. We figure out 315 is in the latter half. We then examine the (closest to) centre element again, 89, then check 233, and 377. We've cut the number of elements we needed to check by half in this case, but for much larger sets the efficiency will be much greater (we'll get to that soon).
There is one problem with this: we can't just jump to different places in a list. In other words, if we want to get to the middle, we have to crawl through the list to get there. This hitch not only makes looking for an item in a list difficult, but adding new items to a list is also possibly very costly. Why might this be the case? Suppose the item is at the end of the list. Similarly, if we're adding an item to our collection, we have to do a search to find the right place to put our new item.
This suggests that lists are not a very good structure for the purposes of organizing and storing data. We need a structure that can be organized so that it can be traversed quickly. It turns out that we have already seen such a structure: the binary tree.
As we mentioned when we first introduced them, on their own, there is nothing necessarily special about binary trees. Indeed, when we first encountered them, we still needed to check the entire tree to find an element. However, we can make use of the intuition that we developed to enforce a condition on our trees to organize how we store data in them and get the same kind of improvement we hinted at above.
A binary search tree is a binary tree that has the binary search property. That is, a binary search tree is either
A note on the key and value here.
Let's consider a binary search tree for our set from above. For convenience, we only label nodes with the keys.
How do we find an item in this tree? Before, we would need to check both subtrees for each node. However, with the guarantees a binary search tree provides, we can perform our search on the tree in the following way:
Suppose we want to find the node with key 15 in the above tree. This means we do the following.
Notice what this algorithm does: we only ever traverse down one subtree for each node. This has huge implications for the performance of the search.
As with the definitions we've seen before, our definition of the binary search tree leads naturally to the following definition in code.
(define-type (BSTree A) (U 'Empty (BSTNode A)))
(define-struct (BSTNode A)
([key : Integer]
[value : A]
[left : (BSTree A)]
[right : (BSTree A)]))This looks almost the same as our definition of the binary tree, and in fact, we could've made it exactly the same if we made a few assumptions. However, there are some additional considerations that led to this particular choice of definition.
First, observe that we have a key and value in our node. We made this choice in our definition too, but this is not totally necessary if you make your key and value the same thing. However, there are very good reasons not to do this, as we explain below.
We have chosen to use an Integer for the key, but we could use some other type, like String. The only constraint on what type the key can be is that there has to be a total order on the type. In other words, the type has to have an ordering that makes sense, since the idea behind binary search depends on being able to order the values in question.
On the other hand, the value can be anything we'd like. If we want to store arbitrary items in our tree, then it is likely that we can't use them as keys, since keys need to be ordered. For instance, if we want to store records of some kind, we often associate it with a unique identifier like a key for this purpose.
Now, there are two main things we want to do with our binary search trees: find stuff in them and put things in them.
We've already described the search algorithm. This leads to the following code.
(: bst-contains? (All (A) (-> Integer (BSTree A) Boolean)))
;; Determine whether or not a node with the given key is in the tree.
(define (bst-contains? key tree)
(match tree
['Empty #f]
[(BSTNode curr-key _ left right)
(cond
[(< key curr-key) (bst-contains? key left)]
[(> key curr-key) (bst-contains? key right)]
[else #t])]))
Recall again our earlier search function for ordinary binary trees. There, if we didn't find the node with the matching key, we would need to go down the left subtree and possibly go down the right subtree. However, with a binary search tree, we can easily rule out one of the two possibilities. This means there is no backtracking like before.
Something slightly more interesting than just figuring out whether our item is in the tree or not is to actually find and get it. This is particularly important if we have a tree that contains key-value pairs, rather than just a tree full of keys. We can take advantage of the binary search tree property for retrieval as well.
(: bst-retrieve (All (A) (-> Integer (BSTree A) (Optional (Pairof Integer A)))))
;; Find the value with the given key is in the tree, if it is in the
;; tree and `None otherwise
(define (bst-retrieve key tree)
(match tree
['Empty 'None]
[(BSTNode k v l r)
(cond
[(= key k) (Some (Pairof k v))]
[(< key k) (bst-retrieve key l)]
[else (bst-retrieve key r)])]))
You may recall that in a similar function for ordinary binary trees, we needed to do some work to determine which subtree our node could have been in. Again, we can rely on the binary search tree property to immediately rule out a branch. In this case, our code is greatly simplified by this assumption.
It is also possible to modify this further so that we retrieve the value rather than the entire node. This would look almost exactly the same, but with some modifications to account for the type and value that are produced.
Since our tree must satisfy the binary search tree property, we need to be far more careful in defining binary search trees. While we can still construct them directly as we've been doing, we need to be careful to ensure that the tree that we construct satisfies the property.
A better way to construct a binary search tree is to write a function to do build a binary search tree for us. If we write such a function correctly, we can guarantee that the resulting tree will satisfy the binary search tree property. Let's think about how to do this.
Suppose we have an existing binary search tree to which we want to add a new node for a key-value pair $(k,v)$. Where should such a node go? Conveniently, it should go into the spot that we reach if we were to search for it! We have the following possibilities:
As usual, the code follows naturally from this.
(: bst-insert (All (A) (-> (Pairof Integer A) (BSTree A) (BSTree A))))
;; Produce the binary search tree that results from adding a node for
;; the given key and value to the given binary search tree.
(define (bst-insert kv tree)
(match kv
[(Pairof key val)
(match tree
['Empty (BSTNode k v 'Empty 'Empty)]
[(BSTNode k v l r)
(cond
[(= key k) (error "Given key already exists in tree")]
[(< key k) (BSTNode k v (bst-insert pair l) r)]
[else (BSTNode k v l (bst-insert pair r))])])]))
Here, we have chosen to throw an error if the user attempts to add a value with a key that already exists in the tree. This is probably the most prudent action if you care about data integrity. However, there are other choices one can make. For instance, you can choose to just overwrite the old value or just choose to have it not do anything at all.
A neat thing about having an insert function is that we can use it to build a binary search tree much more conveniently. Suppose we have a set of elements that we want to build a binary search tree out of. Starting with an empty tree, we can insert each element one after the other on the resulting trees. This sounds suspiciously like a fold.
(: create-bst (All (A) (-> (Listof (Pairof Integer A)) (BSTree A))))
;; Create a binary search tree from a list of (key,value) pairs
(define (create-bst lst)
(foldl (inst bst-insert A) 'Empty lst))Consider the set $\{3,1,5,7,6,2,8,9,4\}$. If we insert the elements in this order, we can arrive at the following tree.
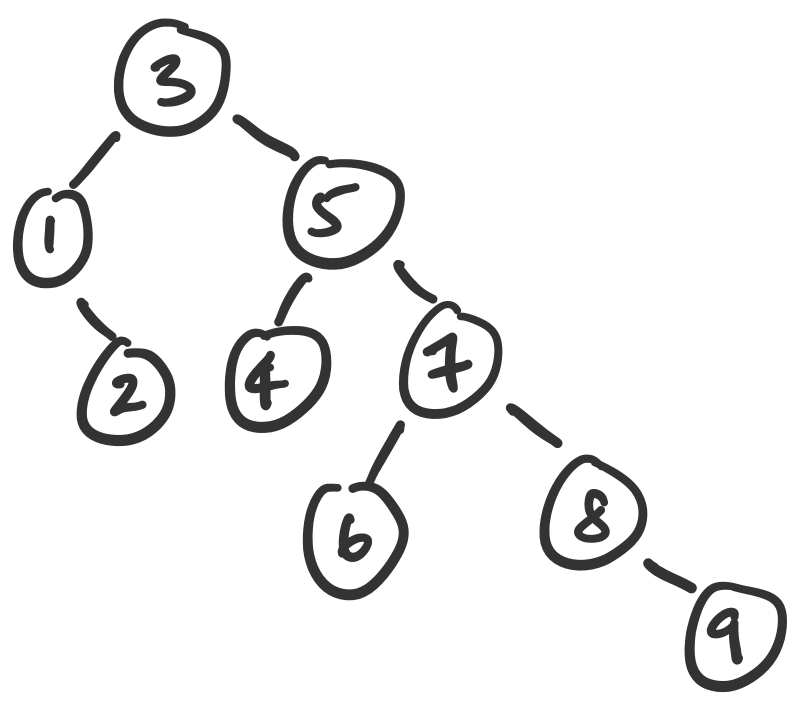
Notice the choice of words here: if we insert the elements in this order, we get this tree. But what if we choose a different order? For example, we could have used foldr instead of foldl. Or we could have chosen something completely different. Let's consider the following binary search trees.
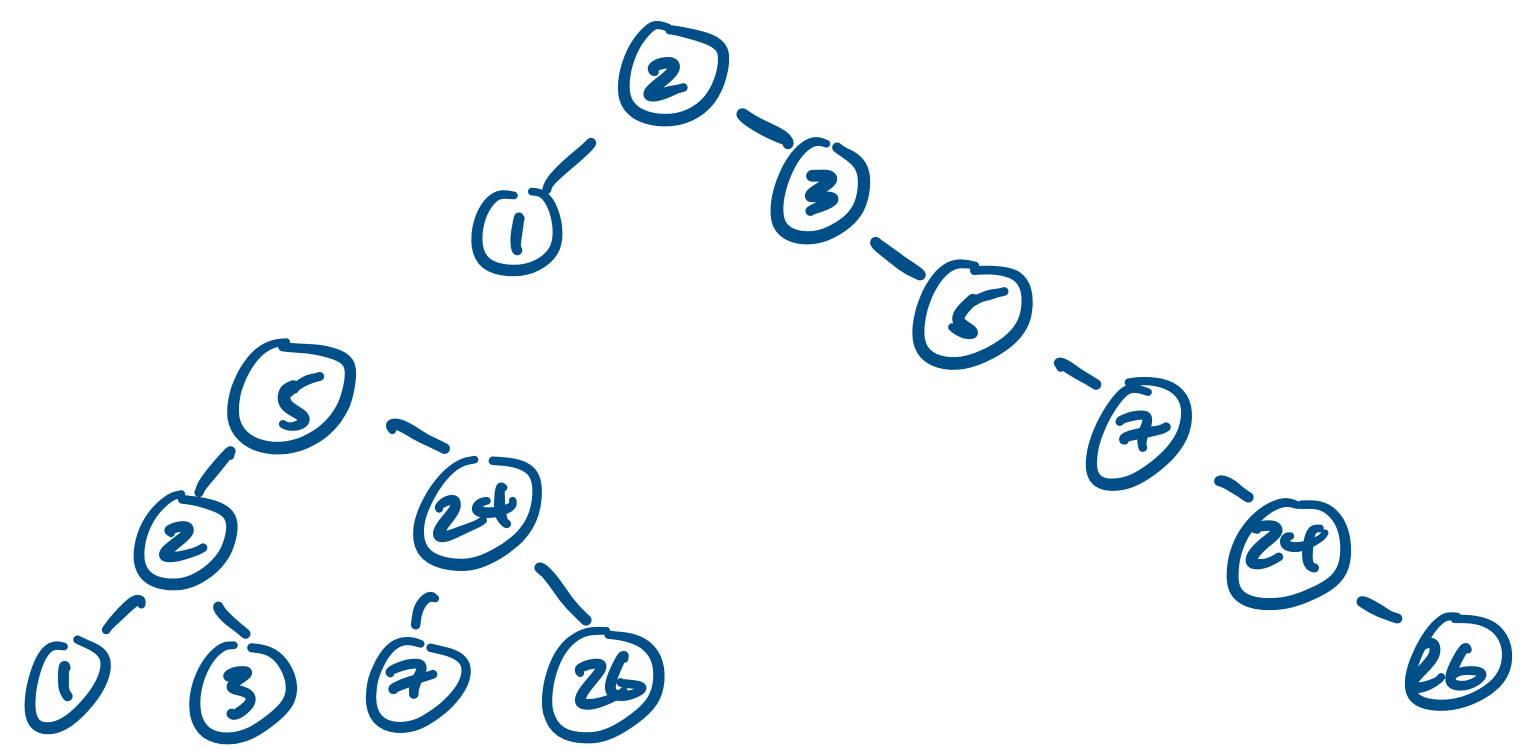
These two trees hold the same data but have very different shapes. That's neat, but does it really matter? Well, consider our initial rationale for dealing with binary search trees. In theory, it allows us to avoid having to visit every element in our set when we are searching for an item. However, for the tree on the right, our search algorithm will still visit almost every item in the set.
So in this sense, the shape of the tree matters. But how much does it really matter?