Now that we've begun to think about the idea of efficiency with respect to sorting, we will continue on that train of thought. Here, we start poking at another deficiency of structural recursion (though this time we don't completely dispense with it). Let's consider an example.
Suppose we want to find the minimum of a list. This shouldn't be too bad—recall that you did something similar for a tree.
(: list-min (-> (Listof Real) Real))
;; Produces the smallest number in the given nonempty list
(define (list-min xs)
(match xs
['() (error "Empty list")]
[(cons head '()) head]
[(cons head tail)
(if (< head (list-min tail))
head
(list-min tail))]))
This function works perfectly fine—it gives us the right answer. But one might notice that it takes a while under certain circumstances.
First, we'll introduce two very helpful functions for our exploration:
reverse reverses a given list.
build-list builds a list of a given length with a given function. For example,
(build-list 10 sqr)
(list 0 1 4 9 16 25 36 49 64 81). It has a type ascription of
(All (A) (-> Integer (-> Integer A) (Listof A)))
build-list as a function that creates a list of integers $0, \dots, n-1$ and then applies map on it with a function of type (-> Integer A). This is a very handy function for defining longer lists.
So we can try running list-min on a simple list, say (build-list 30 add1), and it runs perfectly fine. But what if we reverse it? The computer takes a while, but eventually gets the right answer. But something is amiss: it is really not great that simply giving our numbers in a different order should make such a big difference.
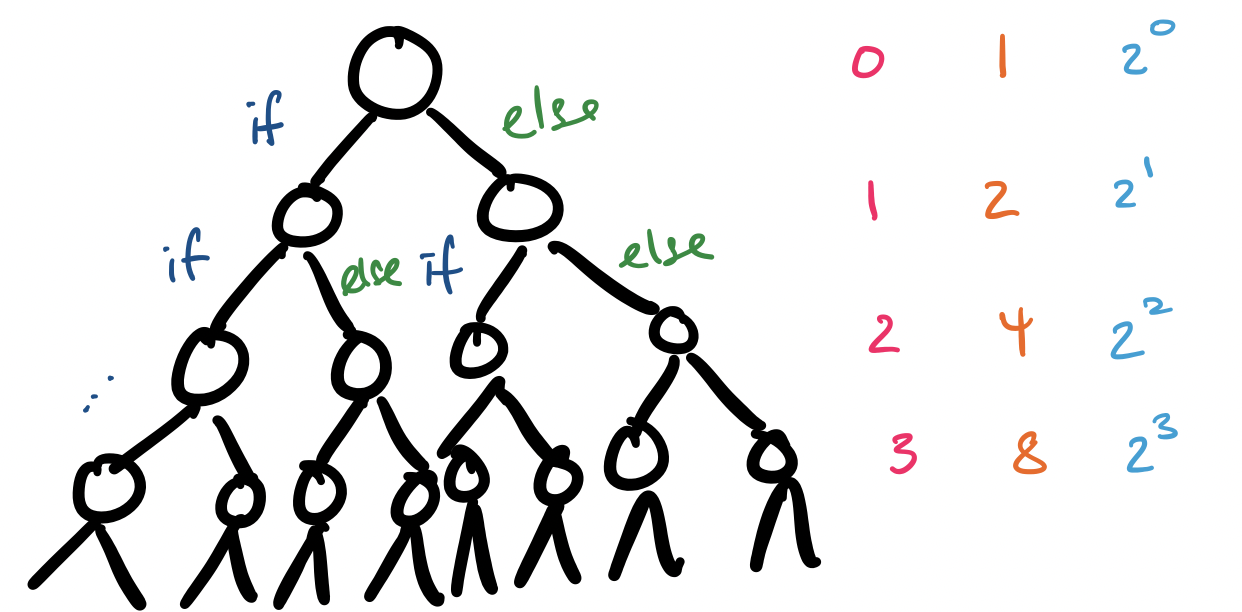
So what is going on under the hood? Notice that each time our function is called, it makes up to two recursive calls. In the first list, this never happens: 1 is always smaller than every other number in the list. But in the second list, this always happens. But what's the worst that could happen? Let's visualize this.
So how many function calls are we making? Observe that each level $i$ of our recursion tree (denoted in pink) has exactly $2^i$ calls (denoted in orange and blue). Adding these all up, we get \[\sum_{i=0}^{n-1} 2^i = 2^n-1.\] It does not take $n$ to get very large before things get out of hand:
| $n$ | $2^n$ |
|---|---|
| 1 | 2 |
| 2 | 4 |
| 5 | 32 |
| 10 | 1024 |
| 20 | 1048576 |
| 30 | 1073741824 |
So in order to find the minimum element in our 30 element list, this function was performing roughly one billion steps. While computers do things a little differently from humans, this still seems absurdly costly.
However, we observe that the two recursive calls that we make really refer to the same value. In other words, we could simply remember this value the first time we compute and reuse it in other places. We can do this by naming the value. This was the commonly suggested fix for some of the poor performance you might have encountered when writing tree functions.
(: list-min (-> (Listof Real) Real))
;; Produces the smallest number in the given nonempty list
(define (list-min xs)
(match xs
['() (error "Empty list")]
[(cons head '()) head]
[(cons head tail)
(local
{(define tail-min (list-min tail))}
(if (< head tail-min)
head
tail-min))]))
This still seems a bit strange. If we think a bit more deeply about the problem, the issue is that in order to determine the minimum element, this function waits until it knows the minimum in the rest of the list. But this is not what we do naturally. Instead, we read the list from left to right and remember which element was largest.
(: list-min (-> (Listof Real) Real))
;; Produces the smallest number in the given nonempty list
(define (list-min xs)
(local
{(: list-min-acc (-> (Listof Real) Real Real))
;; Produces the smallest number in the given list by
;; remembering the smallest number encountered
(define (list-min-acc xs curr-min)
(match xs
['() curr-min]
[(cons head tail)
(if (< head curr-min)
(list-min-acc tail head)
(list-min-acc tail curr-min)])))}
(list-min-acc (rest xs) (first xs))))
This looks a lot like foldl! And in fact, one could turn this into a left fold with not too much work. The key design point of left folds and other similar functions is the addition of an argument to capture the context of a computation. This argument is called an accumulator.
One observation here is how the role of thinking through recursion differs between the "foldr" way and the "foldl" way. With foldr, we think of the computation in a way that's similar to standard mathematical induction: we assume that the result of the recursive call is correct and we specify how to make an additional step to finish the computation. The key point here is that we don't need to know much else about the computation. This is doubled-edged sword: it often simplifies our reasoning, but sometimes this lack of knowledge hampers certain computations.
With foldl and accumulators, we assume that the context (i.e. the partially computed result) that we've been handed from the computation so far is correct and specify how to continue on to the next step. The tradeoff is that it is more difficult to formally reason about these kinds of functions. Note that with foldr, all we needed to do was assume that the recursive call for the rest of our input was correct. However, with foldl, we need to argue about the correctness of a partial computation. This can be difficult, if this isn't the final product, which means an additional argument about the remainder of the input may be necessary (i.e. that there is a property that's consistent with the partial computation and the remainder of the input at every step).
Now, you may notice that there is not much of a gain in terms of efficiency between the accumulator version of list-min and the classical fixed single recursive call version. Let's take a look at another example, which will illustrate how complexity can creep in if we're not careful.
Suppose we want to reverse a list. In other words, we want to write a version of reverse. This turns out to be very similar to a lab we did already, about reversing strings (this is not surprising because strings are really just a special kind of list). This involved the use of a function for concatenating strings, so we can try the same thing with lists, by using append.
First, let's think through the formal definition for reverse. Suppose we have a list lst. Then we define the function rev, which has the type ascription (All (A) (-> (Listof A) (Listof A))), by the following,
lst is '(), then (rev lst) is '().
lst is (cons head tail), then the reversal of lst is (append (rev tail) head).
Note that this doesn't quite work as written, because head has to be put into a list. But this translate easily to the kind of functions we've been writing.
(: rev (All (A) (-> (Listof A) (Listof A))))
;; Reverses the given list
(define (rev lst)
(match lst
['() '()]
[(cons head tail)
(append (rev tail) (cons head '()))]))Note that we had to put head into a list to use append.
However, there's a bit more going on here than meets the eye. Recall the definition of append.
(: append (All (A) (-> (Listof A) (Listof A) (Listof A))))
;; Appends the second list to the end of the first list.
(define (append xs ys)
(match xs
['() ys]
[(cons head tail)
(cons head (append tail ys))]))Something that this definition makes less opaque is the fact that append doesn't simply tack on the second list to the first list. Or rather, that's not what this code is doing, because the issue is we don't know where the "end" of the list is. In other words, we have to find the end of the list by going through the entire thing in order to attach our new list.
This suggests that, like the insertion sort algorithm we saw before, our reversal algorithm is doing a lot more work than is obvious at first. If our list is of size $n$, then moving the first letter to the end requires $n-1$ steps, moving the second requires $n-2$, the third takes $n-3$, and so on, which gives us roughly a total of \[(n-1) + (n-2) + \cdots + 1 = \frac{n(n-1)}{2}\] steps that our function performs. It's that number again!
Intuitively, it doesn't seem like this kind of thing should take that much work. Perhaps there is a better way? If we think back to our discussion of foldr and foldl, we saw that we got very different results when we tried both with string-append—specifically one was the reverse or what we expected. What if we used this property to our advantage?
(: rev2 (All (A) (-> (Listof A) (Listof A))))
;; Reverses the given list
(define (rev2 lst)
(local
{(: rev-acc (-> (Listof A) (Listof A) (Listof A)))
(define (rev-acc xs acc)
(match xs
['() acc]
[(cons head tail)
(rev-acc tail (cons head acc))]))}
(rev-acc lst '())))
So what is happening here? Rather than build a reversed list by using the mathematical definition directly, we are building a list incrementally as we traverse the list. In some sense, this is quite natural: we already know where each of these elements belongs relative to the final list.
In practice, this gets us something even better: instead of trying to find the end of a list at each step, we simply take an element from the front of our input list and attach at the front of the reversed list that we're incrementally building. Since there's no searching or traversing to be done these can be done in essentially one or two steps and the result is that we only require $n-1$ steps to achieve this.
As a final note, remember that we modeled this after foldl, so maybe we can actually rewrite this using foldl. But what is the function that we're folding? It's cons! So it turns out we could have written
(: rev3 (All (A) (-> (Listof A) (Listof A))))
;; Reverses the given list
(define (rev3 lst)
(foldl (inst cons A) '() lst))
and called it a day.