When we were first introduced to functions, we described their use conceptually: as a way to logically group together a series of statements that performs a single task. Typically, we think of this as a "problem" that the function "solves".
However, we did gloss over some of the technical details. For instance, we mentioned (and it seems pretty clear) that the flow of control changes when we call a function and we have to evaluate it. What goes on underneath when this happens?
Here, we'll take some time to walk through some of the details of implementation.
One issue that we've avoided until now but becomes quite important with the definition of functions is the usage of names. Suppose I have two functions each with loops with loop variables named i. Are these names going to be in conflict?
For a simpler example, consider the following function that just adds one to a given number.
def incr(a):
one = 1
return a + one
>>> incr(4)
5
>>> print(one)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NameError: name 'one' is not defined. Did you mean: 'None'?
>>> print(a)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NameError: name 'a' is not defined.
If we try to access one outside of the function, we'll get an error. In some ways, this makes sense—a variable shouldn't exist outside of where it's defined. This notion is called scope. Variables that are defined within a function only exist inside of that function and are called local variables—they are local and exist only within the context of the function.
Function parameters, the variables that represent the inputs to the function, are also considered local variables and their scope is also the body of the function. When a function is called, values get assigned to those names for the duration of the function execution. This ties in to the general principle that a function should be considered independent units of computation.
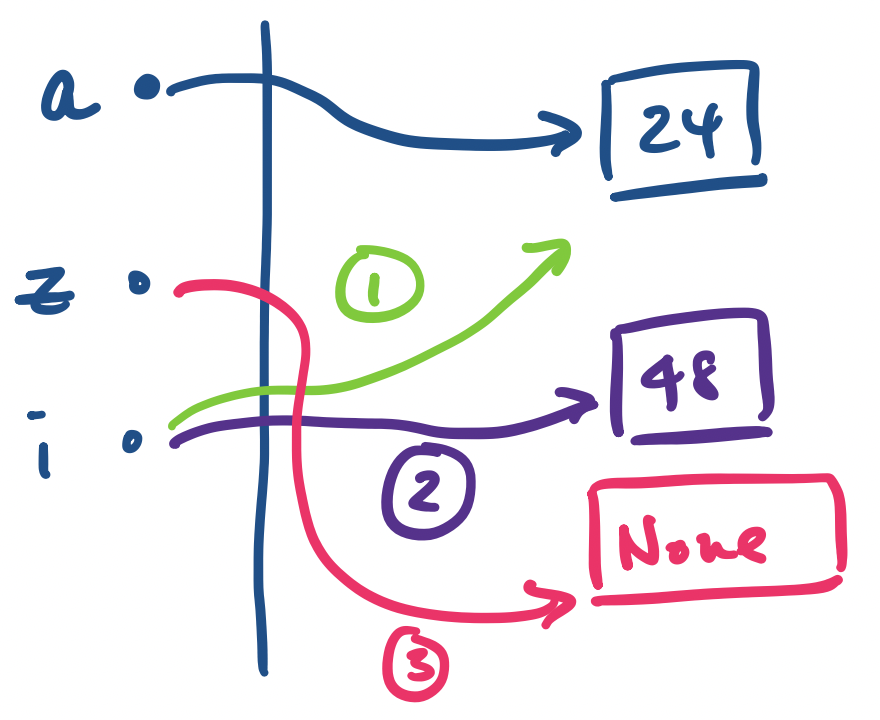
For instance, consider the following function. It has a parameter i and the intent of the function is to reassign i to i * 2, doubling the original value by trying to mutate it.
def double(i):
i = i * 2
However, when we actually run this function, we see that nothing has changed.
>>> a = 24
>>> z = double(a)
>>> print(a)
24
Why? We begin with a assigned to 24. Let's walk through what happens when we attempt to make an assignment to z.
double(a). This causes an assignment for the parameter i, which is whatever value was assigned to a.
i is reassigned to i * 2, which is 48.
double ends. But double does not have a return statement, so z gets assigned None.
This is depicted in the following diagram. Conceptually, we imagine our variables, which we have access to, on the left hand side having references to values on the right hand side, which we call the heap. The heap is where all of our values actually exist in memory.
This place is called the heap because you can imagine it in the same sort of chaotic way: whenever we need to store items in memory, we find some space for it in the heap. This space is not necessarily organized in any particular way, which is why we need variables which hold references to the values in the heap in order to find them.
The thing to notice here is that a never gets "modified" at all during this process, which is why print(a) still displays 24.
This principle works in both directions. Because functions cannot access variables defined in other functions, they cannnot rely on or interfere with some other computation. On the other hand, because functions cannot access variables defined in other functions, they do not need to worry about or keep track of anything going on outside of the function.
One thing to note is that this separation occurs between functions and is not just a matter of whether the variable "exists" or not. For example, consider the following functions.
def plus(m,n):
ans = add(m)
return ans
def add(a):
return a + n
>>> print(add(2, 3))
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "<stdin>", line 2, in plus
File "<stdin>", line 2, in add
NameError: name 'n' is not defined
Though add is called during the execution of a call to plus, it still cannot (and should not be able to) access the variable n which was defined by plus.
Of course, that should make sense: what happens if some other function calls add but doesn't have a variable named n? Whoever wrote add shouldn't have to worry about that.
Here, we'll expand a bit on how all of this stuff is represented internally. How exactly does the computer keep track of all of the function calls and the various variables that each function call defines?
This is all represented by what is called the call stack. Each time a function call is made, a corresponding entry is added to the stack. Such an entry is called a stack frame.
Why is it called a stack? As we make more and more function calls, more and more frames are added to the stack. However, we always execute the most recent function calls first in order to evaluate them. In other words, the call that is made last is always executed first. The stack then gives us the natural order in which our function calls are all executed.
Each stack frame consists of all of the local defintions that each function makes. This includes the values assigned to the parameters, the local variables that are defined, and at the very end, the value that is returned as output.
Here is a diagram of the above example with plus and add.
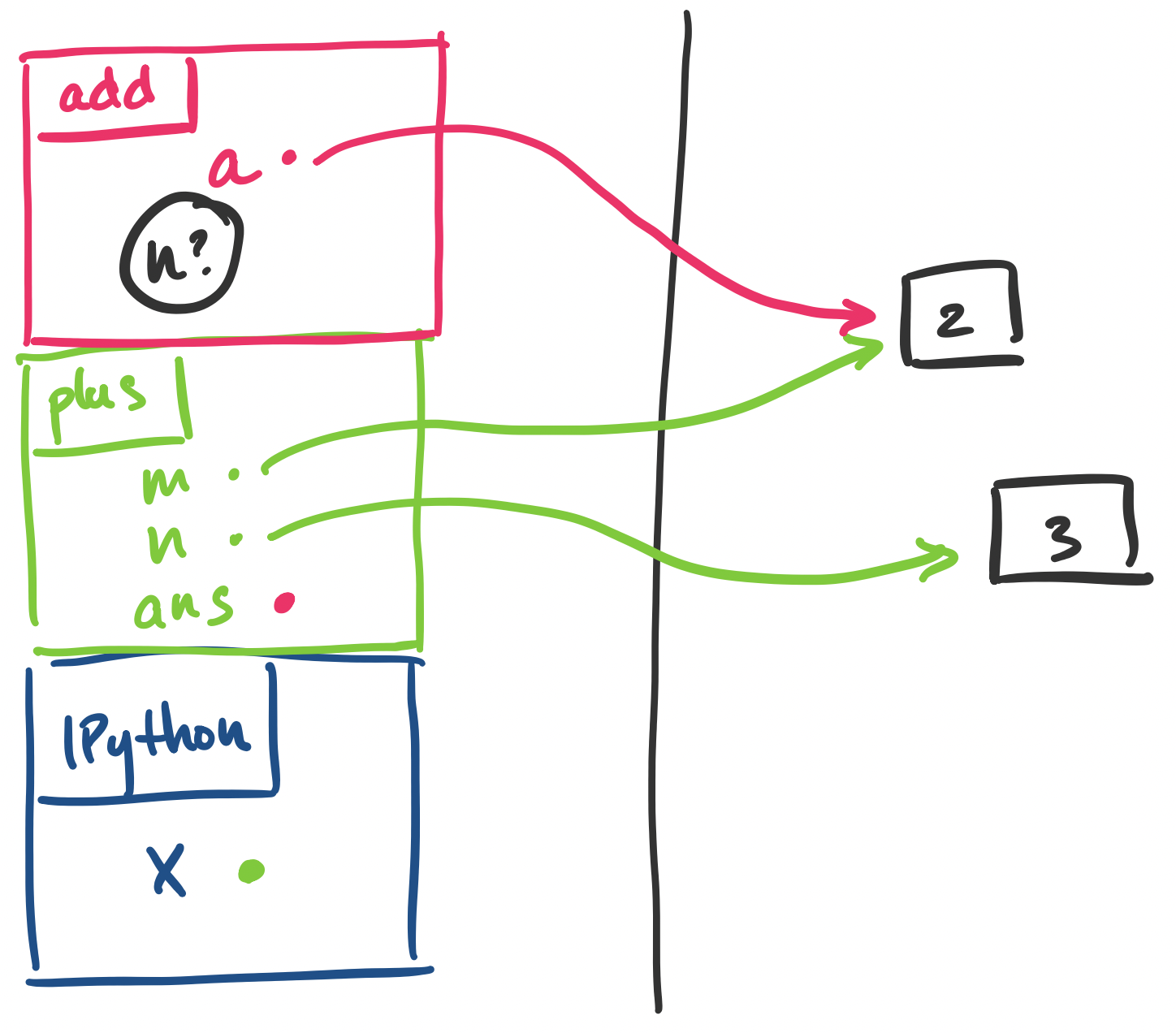
Notice the following:
plus was called from IPython and add was called from plus, they are all stacked on top of each other in order.
a + n is being evaluated, control flow is in add, which is at the top of the stack as expected.
n is not defined in the stack frame of add, it can't be found, leading to the error that we get.
Let's walk through the following example.
def f(i):
i = i + 1
return i
def g(i):
j = h(i*5)
return j
def h(i):
return i+1
def main():
i = 7;
j = k = l = 0;
j = f(i)
k = f(j*3)
l = g(i)
return i, j, k, l
Suppose we call main().
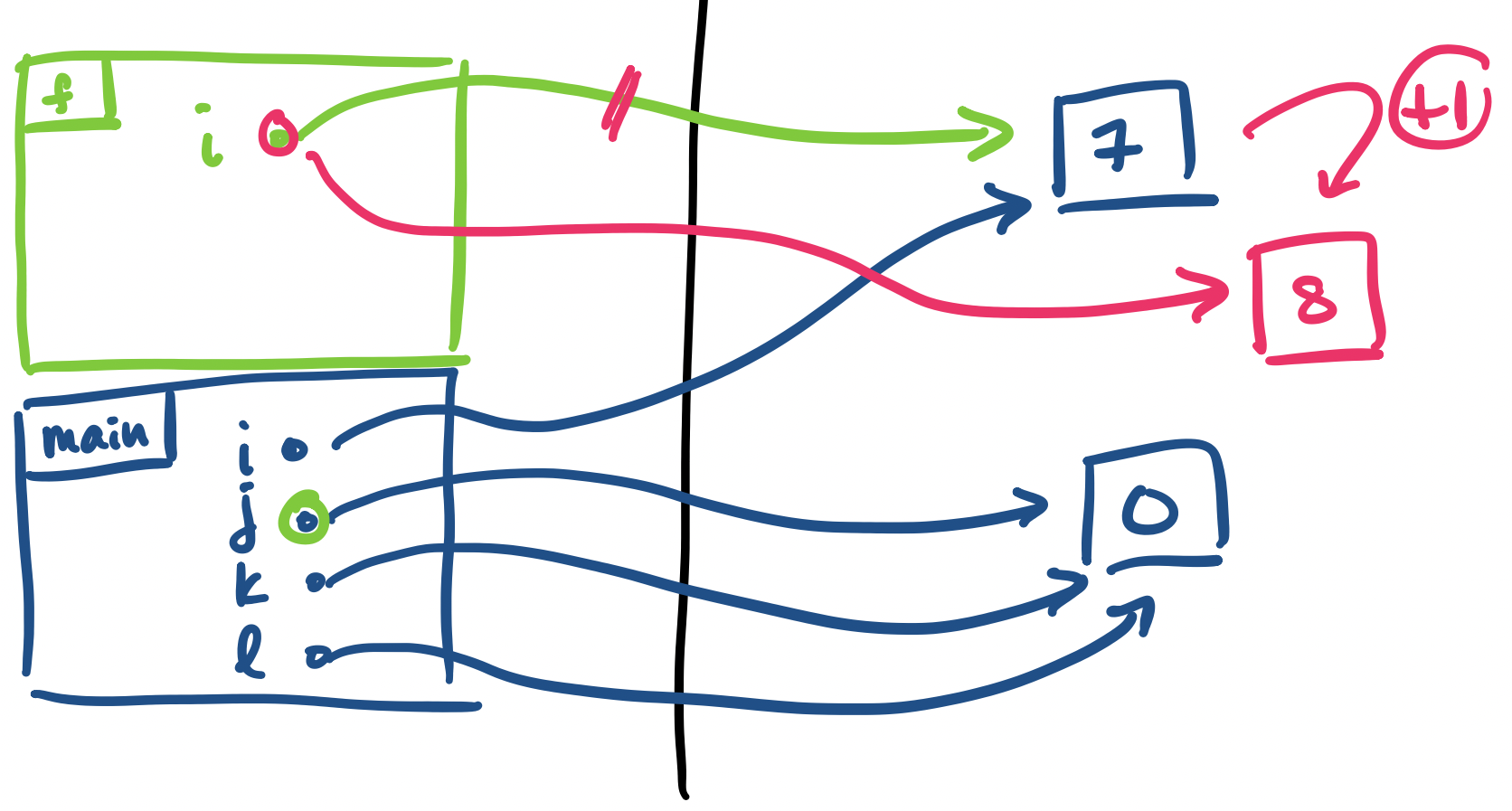
main get executed, also in blue.
j to f(i).
f(i), we create a new stack frame for f and make an assignment to the parameter i. This is all reflected in green.
i's are different—they exist in different stack frames, so they don't conflict with each other. We make an assignment to the i in green, which is in the stack frame of f.
f, we reassign i to i + 1. This is reflected in pink, and is the value that our function call will be evaluated to.
Upon completion of the function, the stack frame is removed from the stack and control flow returns to main. The call to f(i) has been evaluated and assigned to j. We are now ready to perform the next assignment.
Our next assignment involves a function call to f(j * 3).
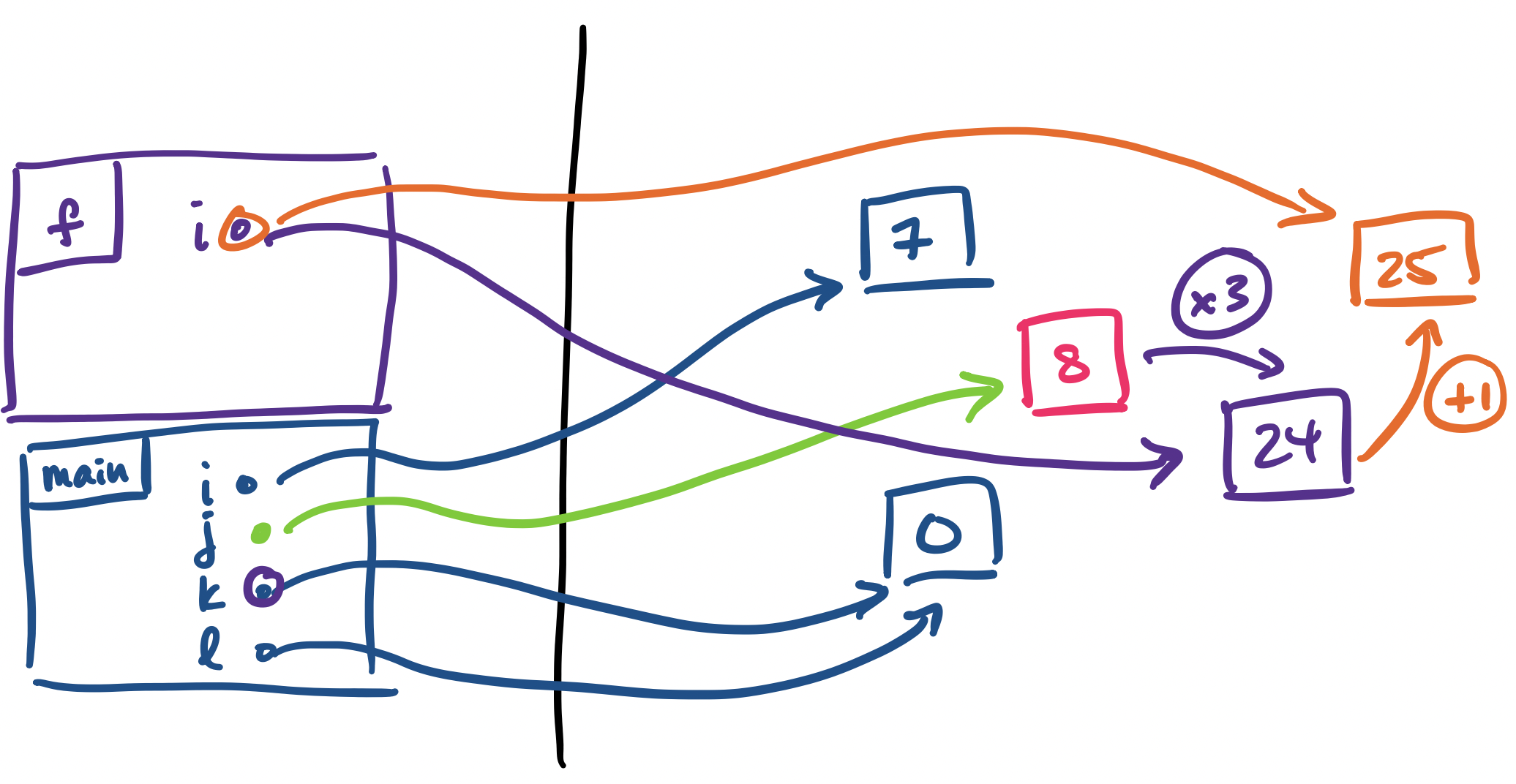
f again.
i, we evaluate j * 3. All of this is done in purple.
f, we make our reassignment of i to i + 1. This is done in orange.
Again, when f is finished with evaluation, it returns the value referred to by i and we assign that value to k and the stack frame is removed.
Once control has returned to the stack frame for main, we make a call g(i) in order to assign a value to l.
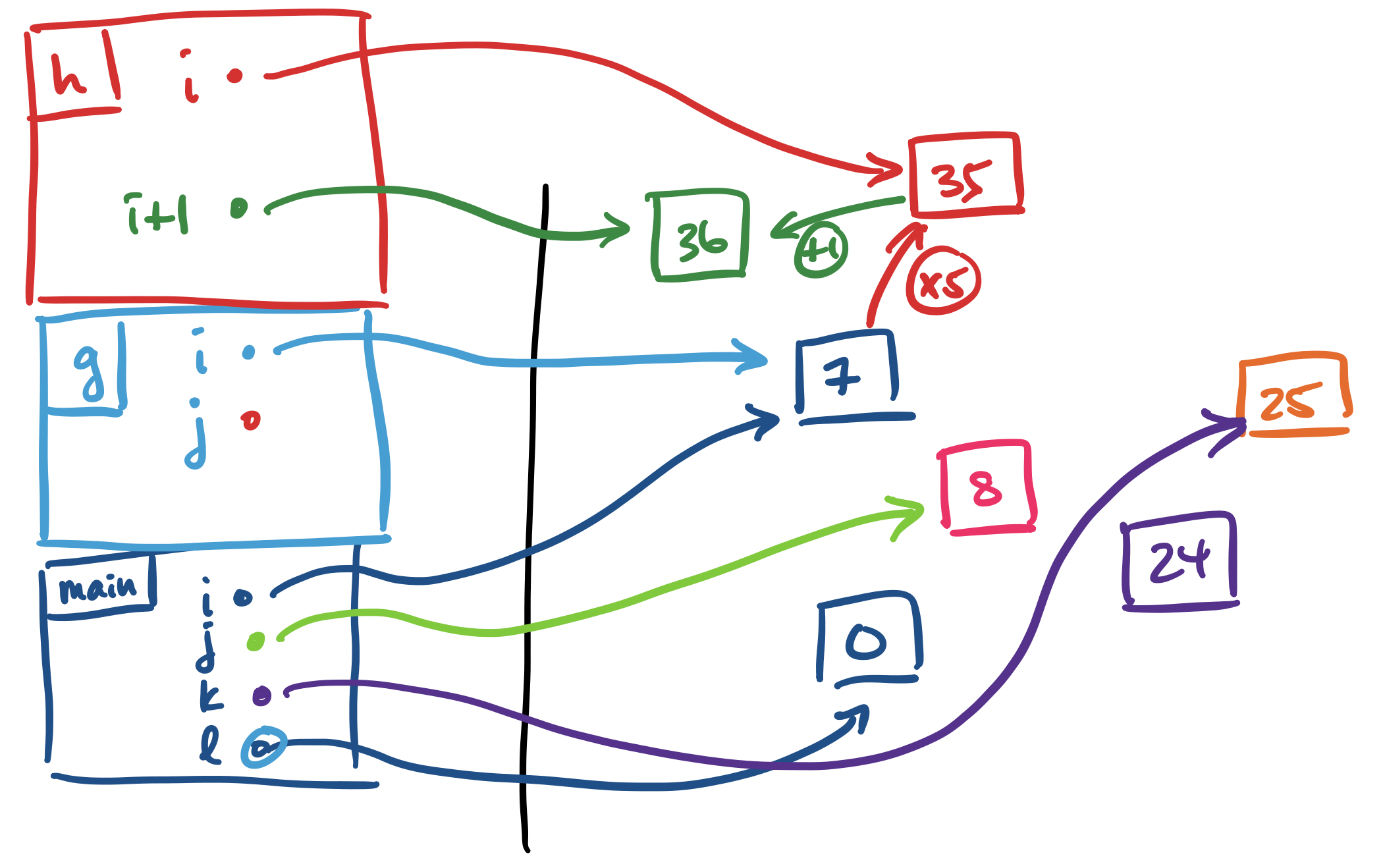
g(i), the value of i gets assigned to the parameter i as usual.
g is an assignment to j. This is a call to h(i * 5).
i gets an assignment to i * 5, which is 35.
h returns i + 1, in dark green.
Once execution of h has ended, its stack frame is removed and the returned value is assigned to j. Now, execution of g ends and j is returned.
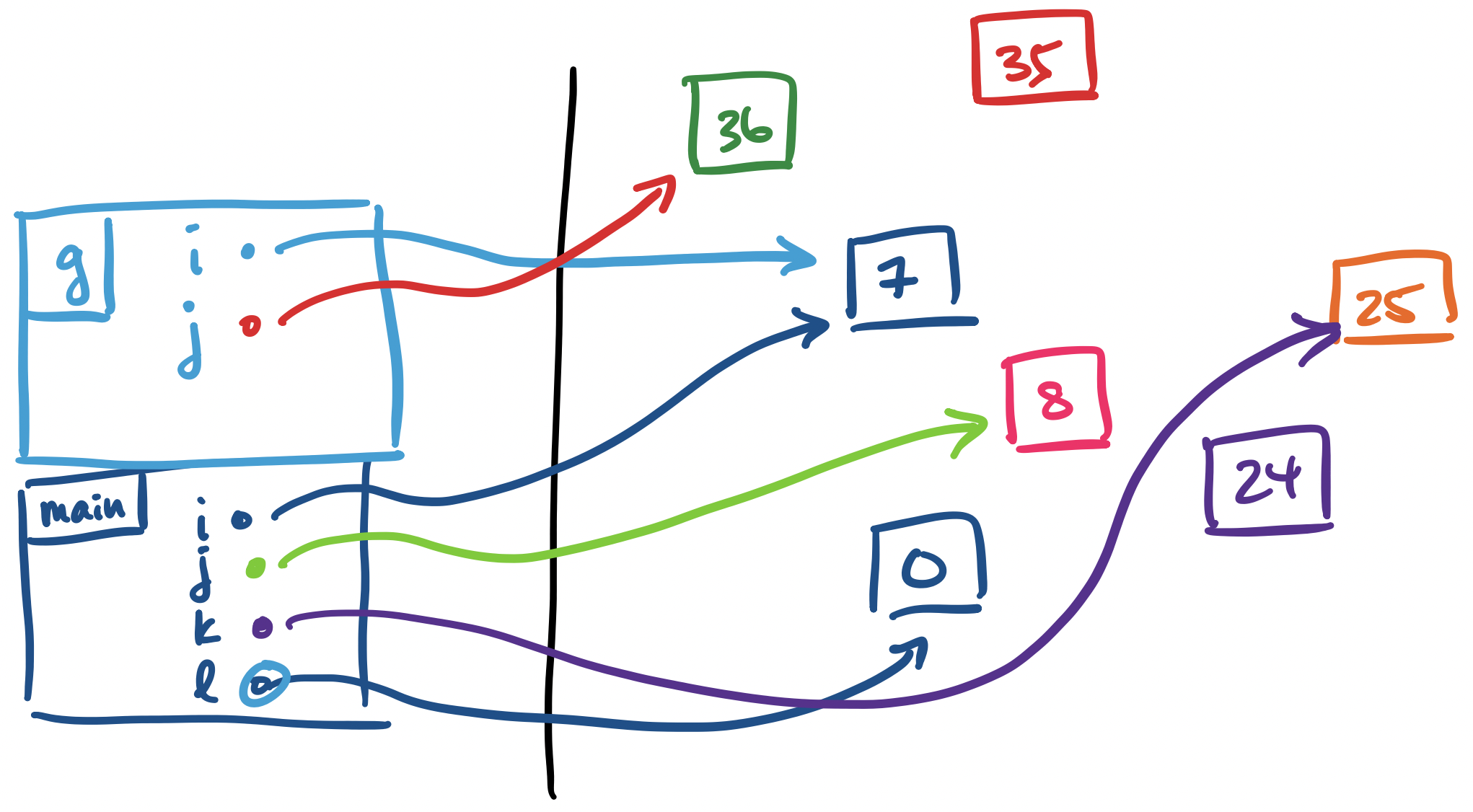
We remove the stack frame for g and the value that j was pointing to is now assigned to l. We should end up with:
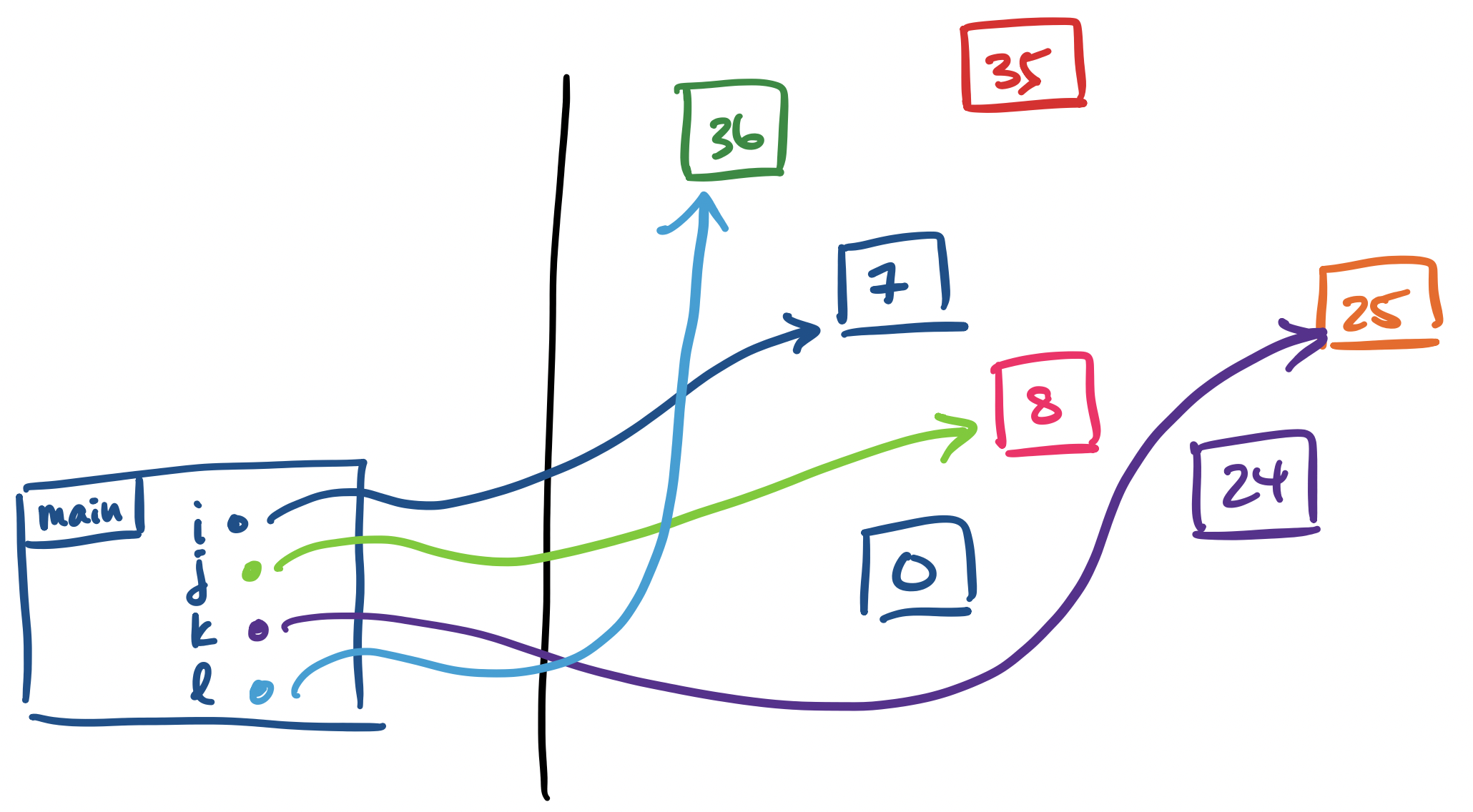
>>> main()
7, 8, 25, 36
The function main produces all of these values as a tuple and the stack frame gets cleared.
When viewed in this way, the mechanics of functions become a bit more clear:
(Curious individuals may wonder what happens to the values that are still hanging out in the heap without references to them. Generally, values with no references to them are thought to be no longer accessible. This means they need to get removed, otherwise your computer can run out of memory. In older programming languages, like C, one needs to explicitly do this and get rid of any allocated memory. In modern programming languages, a feature called garbage collection detects the existence of items with no references and clears out the memory for you. Convenient!)
What we described above is the simple case. Unfortunately, things become a bit more complicated when we remember we have to deal with lists.
Recall that the value of a list variable is a reference to the list, not the list itself. This means that when a function is called with a list as an argument, it really receives the location of the list. In this case, all the usual caveats about how list access works hold: it is possible for a function to mutate a list that is defined somewhere else. This is one of those things that makes mutation complicated to reason about.
Consider the following function, which takes a list and increases the first element of the list (i.e. the "zeroth" element) by 1.
def incr_zeroth(xs):
xs[0] = xs[0] + 1
Notice that this function does not have a return statement! Since the function mutates the list, it does not produce any value. Suppose we try to make an assignment:
old_list = [2,3,4,6,8,11]
new_list = incr_zeroth(old_list)
What should we expect to see? Let's examine the call stack.
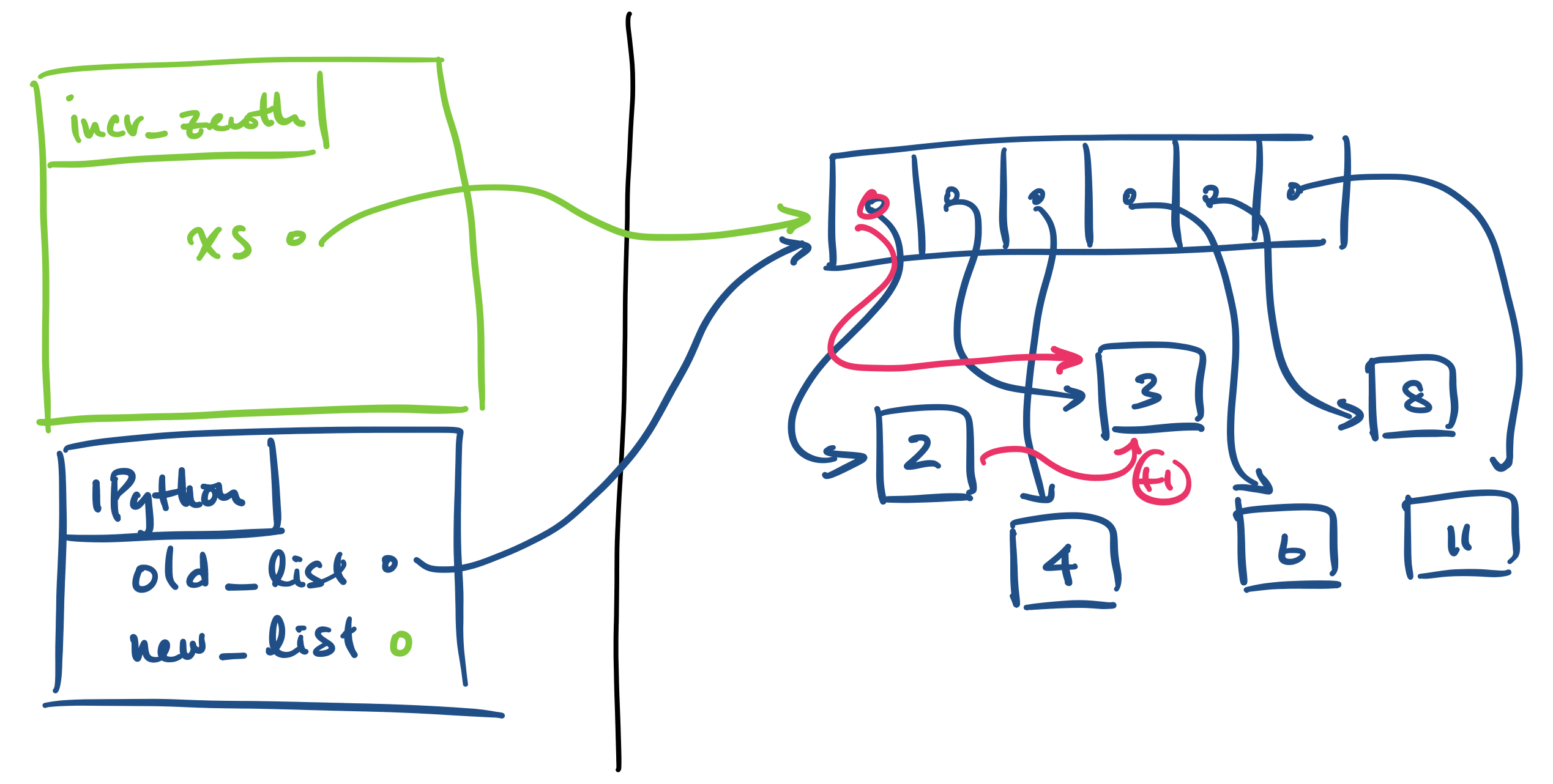
old_list, which is a reference to a list.
new_list. This involves a call to incr_zeroth.
old_list and assign it to xs. This is done in green.
incr_zeroth assigns xs[0] + 1 to xs[0]. This is done in pink.
After this, execution of incr_zeroth ends and its stack frame is removed. The state of our program now looks like this:
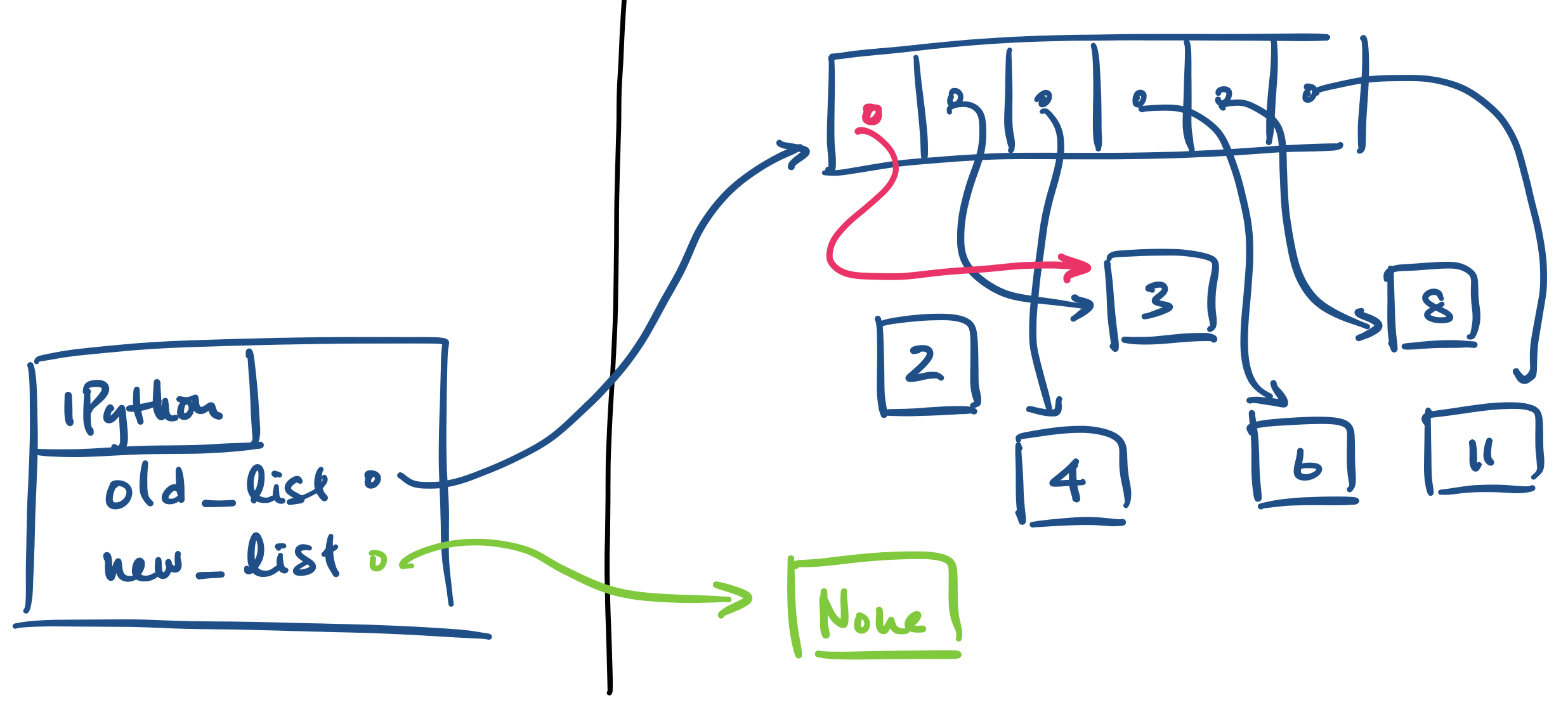
Notice the following.
incr_zeroth didn't have a return statement, new_list receives an assignment to None.
old_list, we'll see that it's changed! The increment of the zeroth element of old_list has persisted outside the stack frame of incr_zeroth!
This is a nice demonstration of what it means to assign "values" to variables and the difference between immutable and mutable values. When dealing with immutable values, the distinction between copying the value itself or the reference to the value didn't really matter.
But when we have mutable values, the fact that we copy references to the values means that there can be two or more variables referring to the same values. And if we change this set of values, this change will be reflected by any reference to these values. If we're not careful about this, it can be very easy to be surprised when this happens.
Finally, suppose instead of modifying an existing list, we wanted to create a new list with based on the old list with the zeroth element incremented. In this case, we can't just use assignment—we have to explicitly create a new list by copying the values.
def incr_zeroth(xs):
new_list = []
for item in xs:
new_list.append(xs)
new_list[0] = new_list[0] + 1
return new_list